
嘿各位,我是Dora。
最近,GLM-4.7-Flash频繁出现在我信任的人的讨论中,通常伴随着一句淡淡的评价:“快得足以不碍事。“这句话戳到了我。我现在不在追逐闪闪发光的新模型:我在追寻让日常工作感觉更轻松的工具。你懂吧?
所以我在我的工具栈里试用了几天GLM-4.7-Flash(2026年1月20-21日)。短提示、小型API脚本、几个批量任务。没什么大动静。我一直想问的问题很简单:这是个实用的补充,还是又一个在时间线上匆匆而过的模型名字?
GLM-4.7-Flash是智谱AI推出的GLM-4.7系列中专注于速度的变体。可以把它看作当你想要快速响应、低延迟生成而不需要繁重推理的时候选择的模型。它不是想赢得长文本基准测试或哲学辩论:它的目标是快速廉价地返回不错的答案。
 智谱AI(也称为Z.ai)是GLM系列的幕后团队。如果你用过早期的GLM模型,命名方式会很熟悉:数字代表代数,后缀(Flash、Standard等)暗示了性能与资源的权衡。他们的文档直白且定期更新:如果你在做集成开发,记下智谱开发者门户的官方API文档。
智谱AI(也称为Z.ai)是GLM系列的幕后团队。如果你用过早期的GLM模型,命名方式会很熟悉:数字代表代数,后缀(Flash、Standard等)暗示了性能与资源的权衡。他们的文档直白且定期更新:如果你在做集成开发,记下智谱开发者门户的官方API文档。
过去一年里,当我需要多语言覆盖和稳定、可预测的输出时,我时不时会用智谱的模型。GLM-4.7-Flash延续了这个模式,只是在速度和吞吐量上投入了更多关注。
以下是我实际使用中感受到的差异:
- Flash:针对速度优化,每个请求计算量低,适合高吞吐量端点、UI助手以及批量分类或标记任务。我注意到它在处理简洁提示和清晰结构时表现最佳。
- Standard(非Flash):速度较慢,但在推理密集型任务上更稳定。如果我向Flash投入多步分析,它会尽力,但我能看出它在压缩步骤以保持低延迟。
如果你在两者之间选择,有个温和的规则:如果延迟和成本是你日常考虑的重点,就从Flash开始。如果多跳推理的准确性是你的首要限制,那么Standard(或更大的推理优化模型)可能会更好。你懂,各选各的武器。
智谱AI在2026年1月19日宣布了GLM-4.7-Flash。我从第二天开始测试。这些模型的版本背景很重要:早期阶段通常会快速迭代。如果你现在看这篇文章,检查官方文档中的发布说明以确认任何限制或行为的变化。
我不需要知道模型的内部结构就能使用它,但某些细节能帮助我估计成本和它的应用场景。
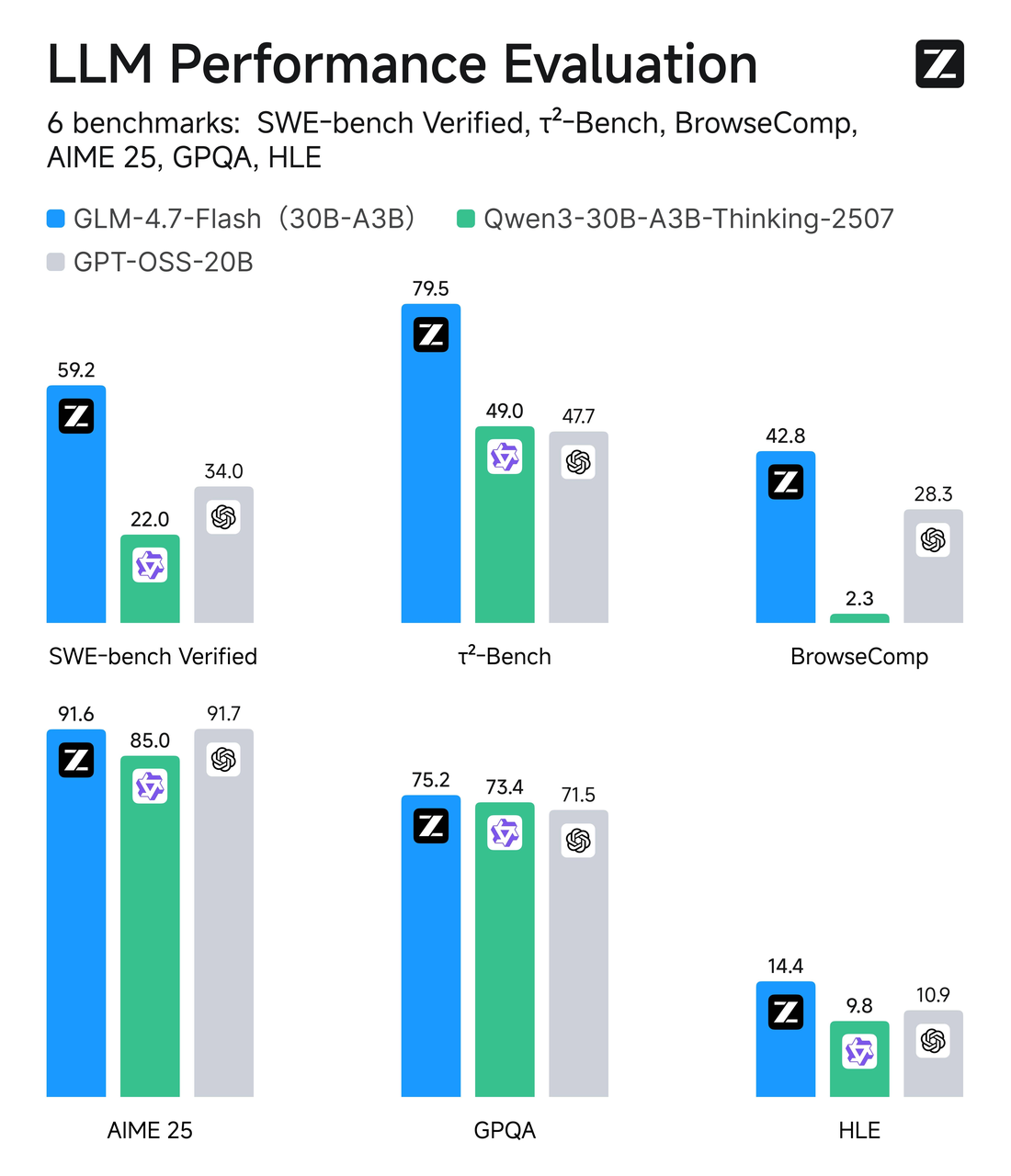 GLM-4.7-Flash使用混合专家(MoE)设计,总参数量约30B,但每个token只有~3B专家是活跃的。简单来说:这是一个宽模型,有选择性的路由。大多数时候,只有网络的一小部分处理你的token,这保持了推理的精简。
GLM-4.7-Flash使用混合专家(MoE)设计,总参数量约30B,但每个token只有~3B专家是活跃的。简单来说:这是一个宽模型,有选择性的路由。大多数时候,只有网络的一小部分处理你的token,这保持了推理的精简。
在实际应用中,MoE通常能给你一种”需要时大脑更强”的感觉,而不需要总是支付完整的计算成本。在我的测试中,这转化为即使在负载下也有快速响应智谱 AI GLM 教程,以及比类似报告规模的密集模型更一致的延迟。这不是魔法,只是平衡容量和速度的聪明方法。
文档提到了MLA(多头潜在注意力)。我作为用户的理解:这是一种注意力策略,目的是比经典的完整自注意力更高效,特别是在较长上下文下。我没有在这里推动长上下文限制:我的大部分运行都在几千个token以内。不过,内存占用保持合理,当提示从”短”增长到”中”时,我没看到通常的延迟缓慢下滑。
如果你在规划检索密集型工作流或agent循环,MLA加MoE是个有用的信号:这个模型被设计用来保持吞吐量上升,而不是追求最大单次推理深度。
免费接入是个亮点。这里我要小心,因为免费配额有时会变化,有时甚至一周一变。我分享的是2026年1月20-21日我观察到的情况,以及智谱文档在发布时建议的内容。在投入生产前,总要再检查一遍限制。  简言之:免费API让我能做真实的请求,有合理的默认设置。我运行了小任务而没在测试中途碰到付费墙。这降低了在实际脚本中试用而不是在playground里试用的摩擦。
简言之:免费API让我能做真实的请求,有合理的默认设置。我运行了小任务而没在测试中途碰到付费墙。这降低了在实际脚本中试用而不是在playground里试用的摩擦。
我观察到的:
- 并发:我能轻松地从一个小型worker运行多个并行请求而不触发错误。在我的测试中,5-10个并发调用保持稳定。当我大幅增加时,开始看到限流,这在免费层上是预期的。
- 吞吐量:短提示(分类、小转换)的返回时间在亚秒到低秒范围。平均来说,我看到很短响应时间为300-900毫秒,中等输出为1.5-3秒。网络变化适用。
- 安全性:当我超过限制时,API返回清晰的错误代码。这本身就为我节省了时间,我不必猜测出了什么问题。
我没有追求精确的TPS上限:我的目标是看小型管道是否能在没有监管的情况下运行。它们可以。这感觉像自由,说实话。如果你在规划波动性工作负载,用实际并发进行测试并建立简单的重试/退避。免费层很慷慨,直到它不再慷慨。
智谱提到了”FlashX”付费选项,针对更高的吞吐量和更可预测的性能。在这次运行中我没有将我的测试迁移到FlashX,但当你升级这样的提供商层级时,通常会发生什么:
- 更高且有保障的速率限制,限流更少。
- 每个密钥更多并发请求,对批量任务和面向用户的助手有用。
- 优先路由(更低的尾延迟)。当你关心最差的5%请求而不仅仅是中位数时,这很重要。
如果你在发布面向客户的功能,FlashX是更安全的选择。如果你在做实验,免费层足以感受稳定性和集成工作。你的里程数将取决于你的延迟预算和你多久批量一次。
我试过一些真实任务。没什么花哨的,就是我这周遇到的东西。
- UI助手界面,其中延迟会破坏体验。想象:内联改写、小型澄清、简短后续。GLM-4.7-Flash让UI感觉立即响应。
- 批量文本转换。我运行了一个小CSV(几千行)来调整语气和分类标记。模型保持一致,中途没有偏离。
- 创建脚手架。大纲、逐点展开、简单简报。当我给它清晰的指令时,它处理结构很好。就像有个你不用贿赂的迷你助手。
- 短上下文窗口的检索摘要。当我输入2-4个片段时,它干净地响应而不会出现怪异的幻觉桥接。有了长的、混乱的上下文,它试图有帮助,但有时压缩过于激进。
- “第一次通过”代码注释或文档字符串。不是深度重构。只是澄清意图和命名,快速且有用。
我不会在以下情况使用它:
- 多跳分析,其中精度比速度更重要的边界情况。我会选择更重的推理模型。
- 需要在数千个token上保持稳定语调和深层事实联接的长文本生成。Flash可以做,但感觉不太对。
为什么这很重要:不会砸碎你预算的快速模型为你打开了你本来会砍掉的功能。如果你的产品每次会话需要几十个微小的模型调用,削减的延迟和每次调用的较低计算成本加起来。小赢,大回报。
💡 为了让在实际工作流中运行GLM-4.7-Flash这样的模型更容易更可靠,我使用WaveSpeed——我们自己的平台,它处理API请求、并发和批量任务,让你可以专注于结果而不是管理脚本。
试试WaveSpeed →  从实战中的一个小建议:我的第一个小时没有更快。我调整了提示结构、温度和最大token数。几次运行后,我找到了模式,短系统提示、明确的输出格式、清晰的约束。这减少了时间和心智努力。这不是魔法:这是设置。
从实战中的一个小建议:我的第一个小时没有更快。我调整了提示结构、温度和最大token数。几次运行后,我找到了模式,短系统提示、明确的输出格式、清晰的约束。这减少了时间和心智努力。这不是魔法:这是设置。
还有谁开始了一次GLM-4.7-Flash(或任何Flash模型)的”快速10分钟测试”,然后眨眼发现时钟显示午夜?在评论中分享你的个人记录——以及那个最终让它表现的提示调整。
发布者:Ai探索者,转载请注明出处:https://javaforall.net/264448.html原文链接:https://javaforall.net


