
你是不是也经历过这些时刻:
- 下载了一个号称“支持GLM-Image”的项目,结果跑起来报错27行,光装依赖就折腾半天;
- 看到别人生成的赛博朋克武士图直呼惊艳,自己照着命令行敲完却只出了一张模糊的色块;
- 想试试“水墨风江南雨巷”,但不知道该写“ink wash painting”还是“Chinese traditional style”,更别提怎么排除“文字水印”“畸形手指”这些玄学问题。
别急——这次我们不讲原理、不堆参数、不聊transformer结构。这篇教程只做一件事:让你在30分钟内,从零开始,在自己的机器上点几下鼠标,就生成第一张真正拿得出手的AI图像。
它不是给算法工程师看的论文复现指南,而是给设计师、内容创作者、产品经理、甚至只是好奇想玩玩AI的朋友准备的“真实可用”方案。界面是Gradio做的,操作像美图秀秀一样直观,连“负向提示词”这种听起来高大上的功能,我们都给你配好了常用模板。
下面我们就从最实际的问题开始:你的电脑现在就能跑吗?需要改什么配置?点哪里?输什么?一张图、一段话、一行命令,全说清楚。
别急着复制粘贴命令。先花2分钟,看看你的设备能不能稳稳托住这个34GB的大模型。
2.1 最低可行配置(能跑,但要等)
小提醒:如果你用的是云服务器(比如阿里云ECS),选“gn7i”或“gn8i”系列GPU实例,自带CUDA驱动和镜像,比本地装环境快10倍。
2.2 一键启动前的3个确认动作
不用打开终端,先肉眼检查:
- 确认CUDA已就绪:在终端输入 ,看到GPU型号和驱动版本(≥525),说明显卡被识别;
- 确认Python版本:输入 ,显示 或 即可(别用3.11+,部分依赖不兼容);
- 确认端口未被占用:默认用7860端口,输入 ,若无返回则空闲;若有,后面启动时加 换个端口就行。
这三步做完,你已经避开了80%的新手卡点。接下来,才是真正的“一键”。
整个过程不需要你手动下载模型、编译代码、配置环境变量。所有脏活累活,都封装在 这个脚本里了。
3.1 启动服务(真·一行命令)
打开终端,直接执行:
你会看到类似这样的滚动日志:
成功标志:最后出现 ,且没有红色报错。
如果卡在 超过5分钟:
→ 大概率是首次运行,正在后台静默下载34GB模型(走HF镜像源,国内速度约2–5MB/s);
→ 此时别关终端,耐心等。你可以打开另一个终端,输入 查看下载进度。
3.2 打开网页,认出你的“画布”
你会看到一个干净的界面:左侧是输入区(正向/负向提示词、参数滑块),右侧是预览区,顶部有「加载模型」「生成图像」两个大按钮。
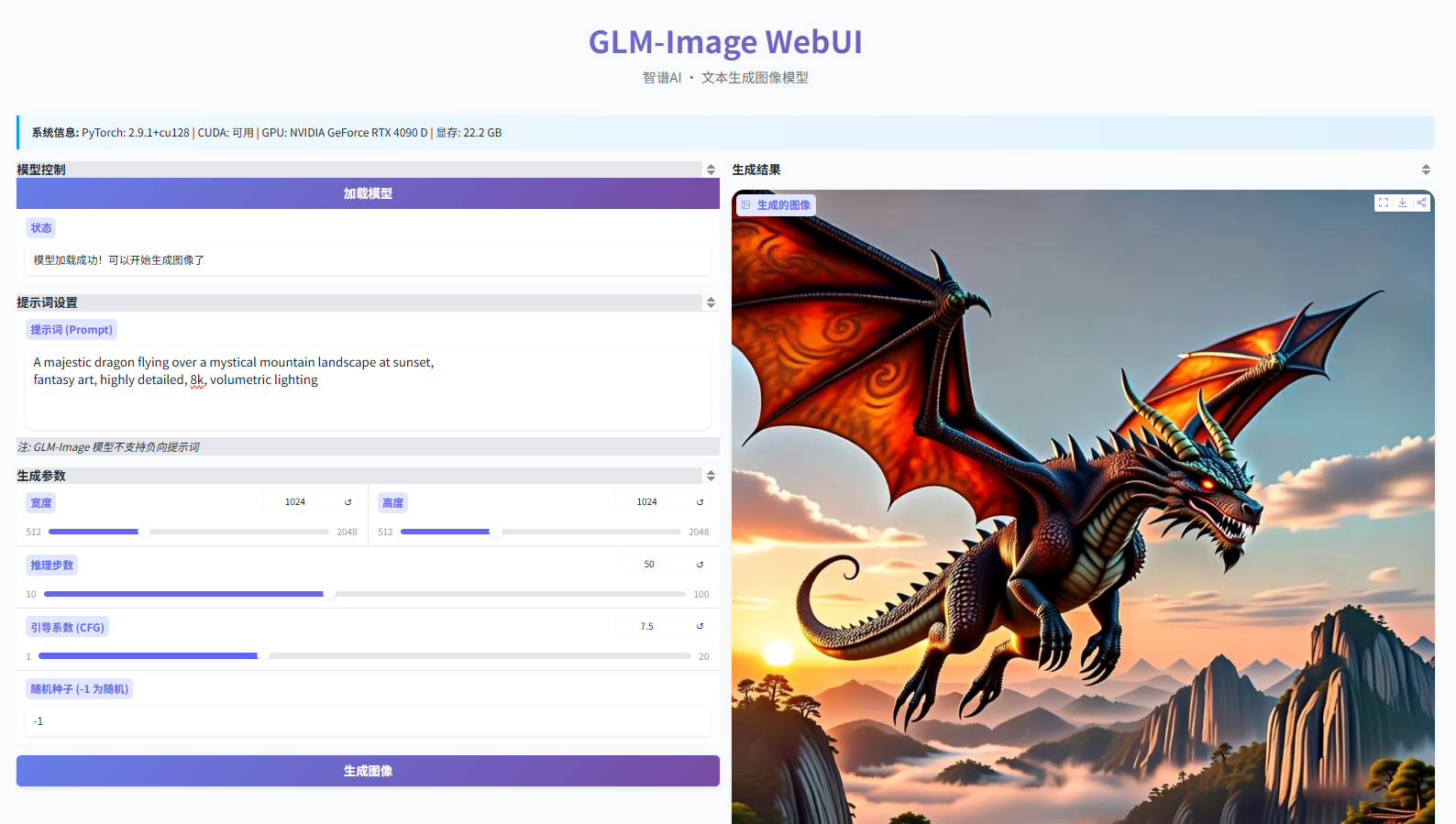

界面细节小贴士:
- 「加载模型」按钮只在首次使用时需要点一次(后续重启自动加载);
- 右上角有「Share」按钮——点它会生成一个公网链接,方便发给同事远程看效果(需网络可达);
- 所有生成图自动存进 ,文件名含时间戳,不怕覆盖。
3.3 首张图:用最简提示词,验证全流程
别一上来就写“梵高风格星空下的机械猫”。先用最基础的测试:
- 正向提示词:
- 负向提示词:
- 宽度/高度:(新手友好,生成快)
- 推理步数:(平衡速度与质量)
- 引导系数:(默认值,足够听话)
- 随机种子:(每次生成新图)
点击「生成图像」,等待约45秒(RTX 4090)或120秒(RTX 3060),右侧就会出现一颗红润饱满的苹果——这意味着:模型加载成功、显卡调用正常、路径写入无误。
很多人以为AI画图=把想法打成文字。其实更接近“和一位有点较真的艺术家沟通”——你描述越具体,它越少自由发挥;你排除越明确,它越难画歪。
4.1 描述主体:先定“是什么”,再补“什么样”
错误示范(太抽象):
正确写法(拆解要素):
拆解逻辑:
- 主体:mountain range + lake + pine forest(三个核心元素)
- 状态:reflected(倒影)、snow-capped(积雪)
- 氛围:golden hour light(黄金时刻光线)
- 质量要求:ultra-detailed(告诉模型“别糊弄”)
4.2 控制风格:用公认的术语,别自创“赛博国风”
AI不认识“赛博国风”,但认识:
- (水墨)
- (赛博朋克)
- (吉卜力)
- (UE5渲染)
直接抄这组万能组合:
例:
4.3 排除干扰:负向提示词不是“写不要什么”,而是“写AI常犯的错”
别写 ——AI根本不懂什么叫“坏东西”。要写它高频翻车点:
界面上那些滑块,不是摆设。但乱调反而让图变差。记住这三条铁律:
5.1 分辨率:先小后大,别一上来就2048
- :快速试错,10秒出图,适合调提示词;
- :日常出图主力,细节丰富,RTX 4090约2分钟;
- :仅用于最终交付,显存吃紧,生成慢,且细节未必提升(模型原生训练分辨率是1024)。
实测结论:对GLM-Image而言,1024×1024是性价比天花板。再大,显存爆、时间翻倍、细节提升微乎其微。
5.2 智谱 AI GLM 教程 推理步数(Inference Steps):50是甜点,30够用,100是折磨
- :速度快,适合批量生成初稿;
- :质量/速度黄金比,90%场景首选;
- :仅当50步仍觉边缘生硬、质感塑料时尝试,耗时增加60%,但提升有限。
5.3 引导系数(CFG Scale):7.5是默认,5.0更自由,12.0易崩坏
- :提示词影响适中,画面自然,适合写实类;
- :严格遵循提示,适合复杂构图、多元素场景;
- :极易出现过饱和、对比爆炸、结构扭曲,慎用。
新手建议:固定用 ,把精力放在写好提示词上,别迷信调参。
90%的“打不开”“出错图”“卡死”,都能在这三步里找到答案。
6.1 图片出不来?先看右下角小字
WebUI界面右下角有一行灰色小字,实时显示状态:
- → 模型还在加载(首次必经,等);
- → 正在生成(此时看GPU显存占用是否飙升);
- → 显存不足,立刻停掉其他程序,或改用CPU Offload模式(启动时加 参数)。
6.2 生成图全是噪点/色块?检查提示词和负向词
- 先清空正向提示词,只写 ,看是否正常;
- 若正常,说明原提示词有冲突词(如同时写 和 );
- 若仍异常,把负向提示词清空,看是否改善——很多“噪点”其实是负向词过度抑制导致的。
6.3 保存路径找不到图?确认输出目录权限
生成图默认存进 。如果没看到文件:
- 输入 ,看是否有文件(注意隐藏文件);
- 若目录为空,输入 赋予权限;
- 再次生成,必现。
这不是一个“部署完就结束”的工具,而是一个持续进化的创作伙伴。今天你用它生成一张苹果,明天就能生成整套电商主图;今天你调参花10分钟,下周就能30秒出稿。
所以,别再搜索“GLM-Image怎么用”,关掉这篇教程,现在就打开终端,敲下那行 。第一张图,永远比一百篇教程更有说服力。
发布者:Ai探索者,转载请注明出处:https://javaforall.net/267262.html原文链接:https://javaforall.net


