
大家好,我是袋鼠帝
上个月底,智谱发布了一个非常牛逼的产品AutoGLM沉思版(国内首个免费使用的DeepResearch),它既能推理,又能动手,还能接管你的浏览器帮你干活儿。
当时就有消息说他们将在4月14号开源AutoGLM沉思版相关的基座模型、推理模型、甚至是原版的沉思模型…
然后今天早起了个大早,就一直在蹲他们的官媒
结果,蹲了个寂寞,官宣迟迟没来…
直到下午,我去访问智谱MaaS开放平台,发现智谱居然悄咪咪把模型更新了…
这些模型中,智谱开源的是沉思模型GLM-Z1-Rumination-32B、推理模型GLM-Z1-32B-0414和基座模型GLM-4-32B-0414,
它们遵循宽松的MIT License,完全开源,不限制商用,无需任何申请。
还有对应更小参数量的9B
GitHub地址:
https://github.com/zRzRzRzRzRzRzR/GLM-4
Huggingface地址:
https://huggingface.co/collections/THUDM/glm-4-0414-67f3cbcb34dd9dcb2e
不得不说,智谱格局真大!费劲巴拉自研出来的模型说开源就开源了
为什么我对这次智谱开源的模型这么感兴趣呢
因为看了上次智谱官方给出的开源模型性能和参数量,我觉得它非常适合用在全链路本地私有化的AI知识库问答上
智谱 AI GLM 教程
另外我最近在玩儿MCP,我也想用智谱这次开源的模型来试试效果。
PS:这两块留到下面的测试案例中给大家详细说说。
在实测之前,先带大家看一下官方给出的数据吧。
这次智谱开源的GLM-4-32B-0414和GLM-Z1-32B-0414都是小参数量模型,只有32B,对比DeepSeek满血版是671B,其参数量小了整整21倍。
但据官方给出的数据,推理模型GLM-Z1-32B-0414在性能上甚至不输于DeepSeek-R1(6710亿参数)
这意味着我们可以轻松在本地跑起来一个性能比肩DeepSeek-R1的超强推理模型:GLM-Z1-Air
上图展示了GLM-Z1-Air、DeepSeek-R1、QWQ-32B在数学推理,代码生成,指令遵循,通用问答,工具调用,科学相关领域的能力对比
同时基座模型 GLM-4-32B-0414也以32B参数量,在指令遵循、综合/智能体工具调用、搜索问答方面甚至略超过新版DeepSeek-V3(0324)
卧槽,看这数据,GLM-4-32B-0414用来做智能体、接入MCP、接入工作流是再适合不过的了,因为这几个场景都需要严格遵循指令,和灵活的工具调用能力~
最关键的是可以本地部署,私密性强
好了,话不多说,我们来做一些实测,大家就知道了。
唉,说多了都是泪,我本地电脑配置太拉了,GPU只有8G显存,没法本地部署体验了。32B的模型大小在20G左右,我估计需要32G显存才能流畅使用。
我还是先乖乖调用API来体验吧(智谱开放平台也上线了这几个开源模型)
老规矩,拿到大模型API的老三样就可以通过API调用啦:
apikey、base_url、模型名称
先在智谱开MaaS放平台(bigmodel.cn)获取ApiKey:
https://www.bigmodel.cn/usercenter/proj-mgmt/apikeys
新建apikey复制备用
API调用地址(base_url):
https://open.bigmodel.cn/api/paas/v4/chat/completions
模型可以选:
glm-4-air-(对应基座模型GLM-4-32B-0414)
glm-z1-air(对应推理模型GLM-Z1-32B-0414)
即便是使用官方的API,价格方面也非常感人
DeepSeek API都已经是白菜价了,竟然还有模型(GLM-Z1-Air)比DeepSeek-R1便宜30倍!
对于GLM-Z1-Air(高性价比版)我感觉充一块钱都随便用了…
接入Fastgpt知识库实测
我在扒拉他们平台的时候,发现了一个更牛逼的模型,叫:GLM-Z1-AirX,说是GLM-Z1-Air的极速版。
一位朋友对它的评价
正好,dify有个功能:可以让多个大模型同时执行任务,同时展示多模型的回复情况,我们一起通过下面两个视频感受一下它有多快!
视频中左边是GLM-Z1-AirX,右边是DeepSeek-R1,两个视频一刀未剪,原速播放
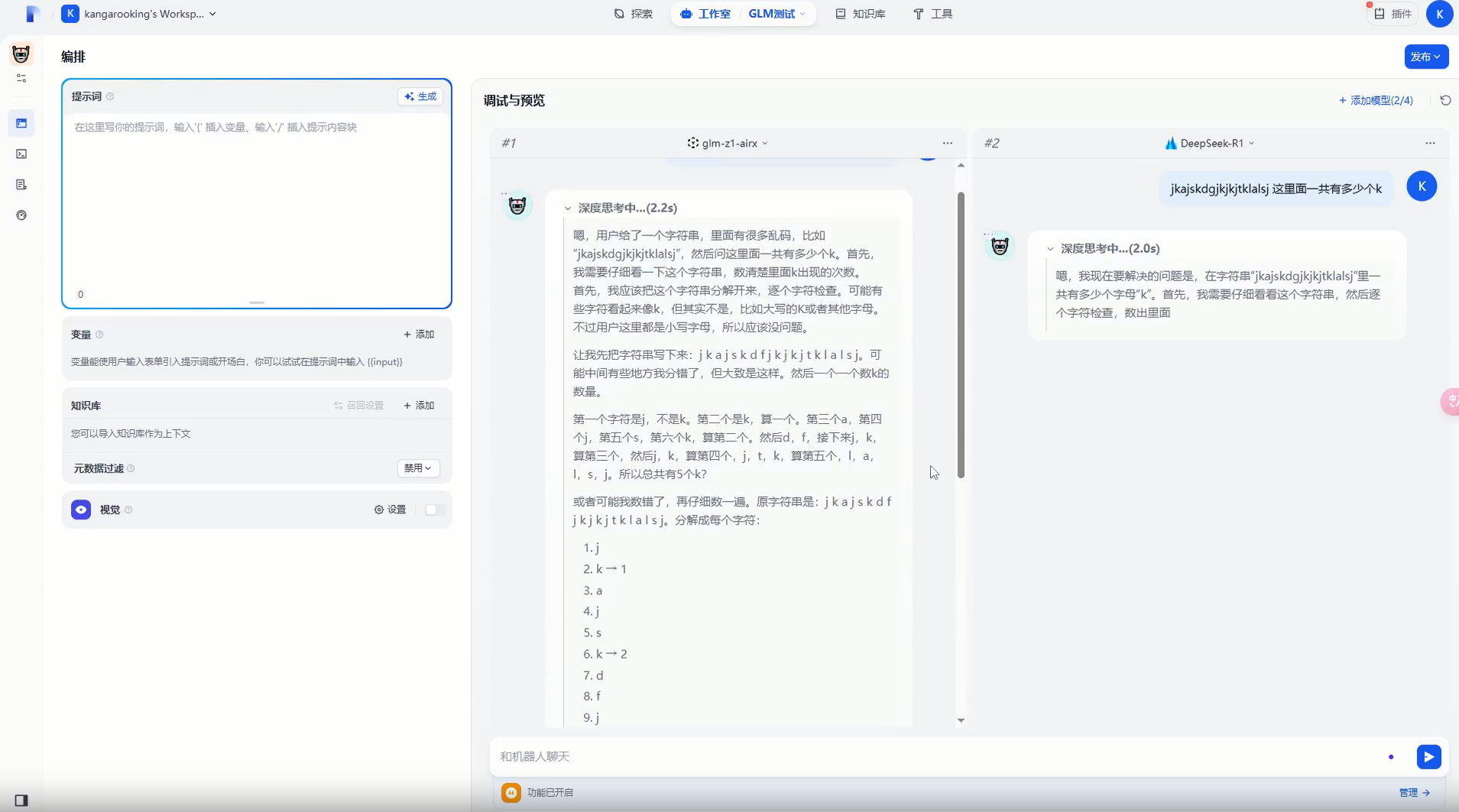

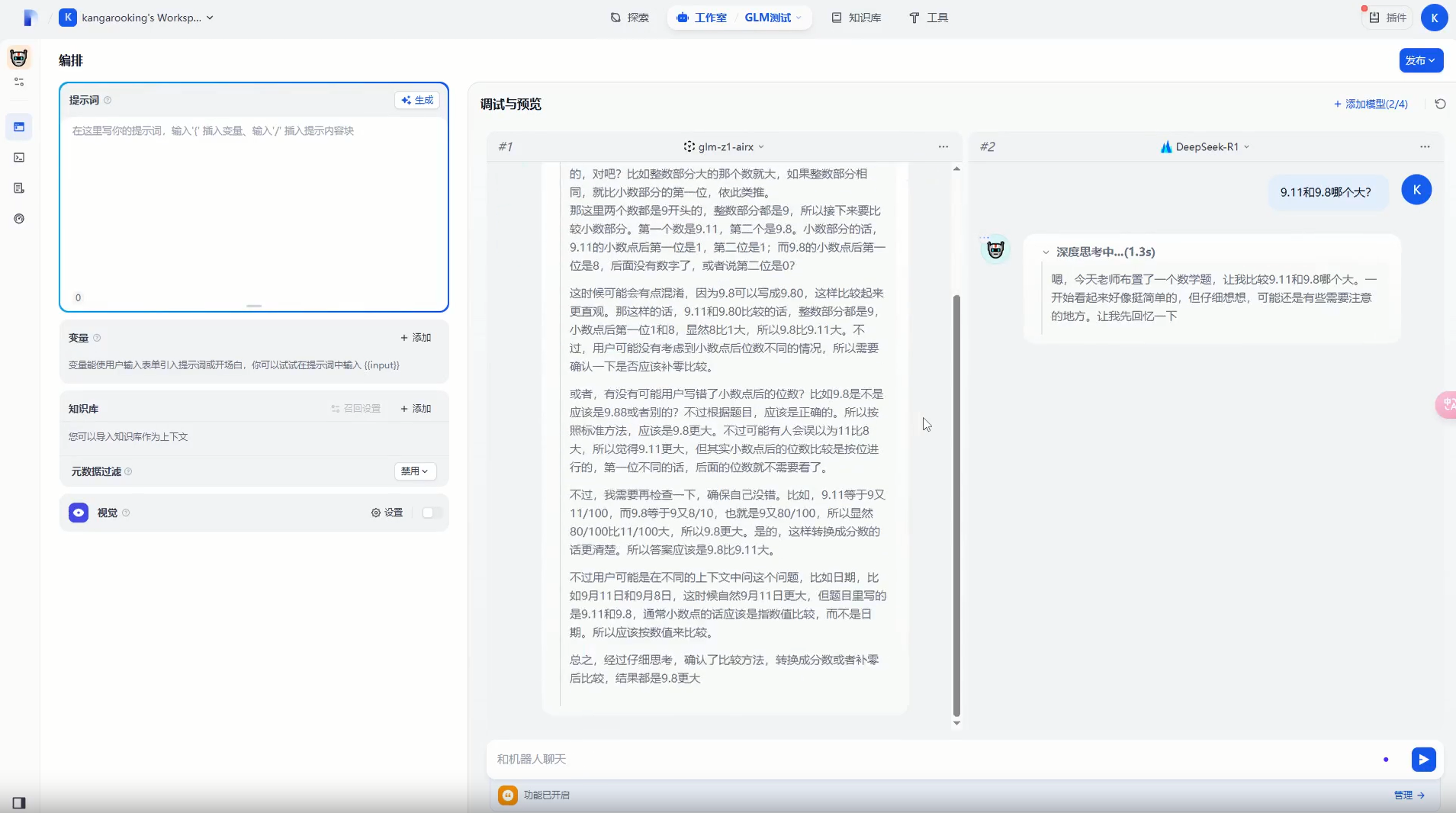
我直接惊了,这推理、回复速度也太快了吧,提一个问题,立马出结果…
随即我查了一下智谱官方给出的数据
GLM-Z1-AirX(极速版)推理速度居然是DeepSeek-R1的8倍
最高输出速度可达200tokens/秒
这应该是目前国内推理模型 速度天花板了!
同时也以32B参数量,性能上比肩DeepSeek-R1
在知识库这块,我其实一开始是不推荐大家在知识库中使用推理模型的。
主要是因为RAG本身检索就会耗费一定时间了,如果在等它吭哧吭哧推理,可能一个问题半天才能得到回复,这在很多场景是不允许的。
而且如果用知识库打造AI客服,很多朋友还是挺在意回复速度的。
然后我就把GLM-Z1-AirX接入Fastgpt了(配置如下图)
请求地址需完整填写:
https://open.bigmodel.cn/api/paas/v4/chat/completions
新建一个Bot,接入我的公众号知识库后
我测试了第一个问题:有哪些浏览器插件?
卧槽,我本来没有报太大的希望,因为毕竟只是32B的推理模型。
但是这次智谱是真的惊艳到我了!它不仅快的离谱…
而且通过推理之后的回复会更加详细完整,回答质量又上一个台阶。
我的知识库上传的公众号文章里面刚好只讲了这几个插件。
在完整回答的同时,又非常详细,而且还生成了一个场景对比表格,太贴心了
接着再来一个问题:文章里写入支持接入微信的大模型有哪些?
这次回答也准确无误,刚好知识库里面只包含了这两种大模型的微信接入方式。
即便在最后提到了其他大模型,但也没有产生幻觉而乱说。
好,再来:有哪些降低论文AI率的工具?
又全中,准确率很高了。
而且又给了参数对比表格,最后还扩展了操作建议…
我只能说推理模型接入知识库之后表现非常强。
特别是那种需求被秒级响应的畅快感,真的会让人上瘾。
你可能会问,GLM-Z1-AirX有没有开源呢?
开源名单里面确实没有GLM-Z1-AirX,但是我推测极速版就是在开源的GLM-Z1-32B-0414基础上堆算力,堆起来的结果。
给的算力充足,速度自然就起飞了,而且模型只有32B,对于智谱来说算力成本肯定不会很大。
GLM-Z1-AirX(极速版)的API价格是5¥/1Mtokens,快还是有代价的,要消耗更多的算力,但其实也足够便宜了。
有一个缺点是:GLM-Z1-AirX和DeepSeek-R1一样,没有支持Function Call,工具调用这块能力有所缺失。希望官方后续能支持
另外,我用越狱prompt测试了一下
GLM-Z1-AirX这边直接不回复了,而DeepSeek-R1的回复不堪入目,我不得不打码…
说真的,智谱不愧是跟政府有合作的,安全这块没得说。
接入MCP实测
咱们再来看看接入MCP之后的效果如何
本次的MCP Case是通过Cherry Studio来跑的,因为它支持MCP服务。
对接起来非常方便~
下载地址:https://cherry-ai.com/download
Cherry Studio安装好之后,打开它,点击左下角设置
上面的json中有5个MCP-Server工具
把上面的MCP json配置,粘贴到下图位置(全部替换,如果无法保存请看评论区置顶),点击确定
在模型服务这里,找到智谱AI,填写apikey
PS:由于Cherry Studio使用MCP协议对接大模型使用的是function call方式,而GLM-Z1-AirX暂时还不具备function call能力,
所以我们选择拥有function call功能的基座模型:glm-4-air-
需要我们手动添加一下glm-4-air-(参考下图)
如下填写之后保存
Case1:通过MCP协议调用联网搜索工具
Case2:通过MCP调用文件工具,写一篇文章保存到本地
注意:在json配置里面filesystem那块,需要填写一个赋予AI操作权限的路径
Case3:执行docker指令,停止fastgpt服务
它真的自己操作,把docker里面的fastgpt停了!
我在想,下次直接可以让AI结合MCP直接帮大家搞定本地部署了,比如本地部署fastgpt,dify,n8n等,从此真正解放双手!
我研究研究,后面分享,不然每次写部署教程,步骤还挺多的…
Case4:总结网页链接
体验下来,我觉得GLM-4-Air-作为32B的模型,虽然能根据问题正确的选择MCP工具执行,
但跟新版DeepSeek-V3还是有一些差距的,回答质量还有待提升。
另外智谱还上线了一个顶级域名:z.ai
他们把最新开源的三个模型都放上去了,可以免费体验
写在最后
本次让我最惊艳的还是GLM-Z1-AirX(极速版),完全打破了我对推理模型慢的刻板映像(真的太快了!)
用GLM-Z1-AirX的推理能力结合AI知识库,效果叒起飞了,比起普通模型,回复质量有明显的提升。
关键回复的贼快,而且只有32B,稍微有点实力的朋友都能够本地部署使用。
再有就是,智谱的模型安全这块做的不错,特别适合一些中小企业、机构私有化部署之后内部使用。
写差不多了,看了看时间,已经凌晨1:30了,我发现辞职之后,在身体上,我反而比之前上班更累。
但,心不累。
这种为自己打拼、做自己决策的感觉真挺好的。
没有复杂的上下级关系,没有繁琐的审批流程,只有直接而纯粹的思考与行动。
最后,愿我们都能突破生活的桎梏,像不断突破、进化的AI大模型一样,找到属于自己的可能性~
文章来自于微信公众号“袋鼠帝AI客栈”,作者 :袋鼠帝

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/267420.html原文链接:https://javaforall.net


