
处理音频数据时,我们是不是经常要切换各种工具?转写用 ASR(语音识别),转音频又得找稳定的 模型(工具)……
最近月之暗面 正式开源了 Kimi-Audio,可以帮助我们解决处理音频时来回切换不同工具的痛点。


Kimi-Audio 由月之暗面(Moonshot AI)开发,是一款开源音频基础模型,基于 Qwen 2.5-7B 构建,可以统一处理音频理解、生成和对话任务。
依托 1300 万小时音频数据预训练,通过混合输入(离散语义标记 + 连续声学特征)与创新架构,统一多种任务。
Kimi-Audio 支持语音识别(ASR)、音频问答(AQA)、音频字幕(AAC)、情感识别()、声音分类(SEC/ASC)、文本到语音(TTS)、语音转换(VC)和端到端语音对话。
月之暗面 Kimi 教程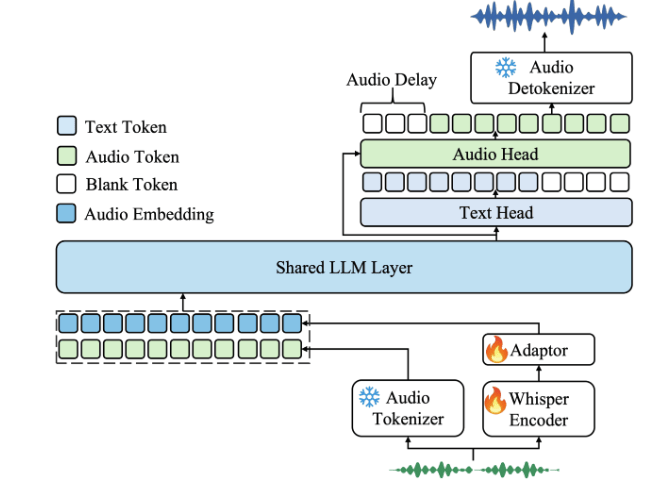
主要功能
快速部署
Kimi-Audio 提供 Docker 和本地部署两种方式。
本地部署
1、克隆项目
2、安装依赖
Docker 部署
1、构建镜像
或使用预构建镜像
2、运行容器
使用方法
1、加载模型
2、语音识别(ASR)- 示例
3、语音对话 – 示例
运行评估工具包
1、克隆 Evalkit
2、运行 ASR 评估
更多使用细则可参考项目文档或HF模型说明。
写在最后
Kimi Audio 是基于 Qwen 2.5-7B 构建的音频-文本多模态基础模型,它既能听懂,又能说话,而且理解深、表达自然、响应快。
具备语音识别(ASR)、音频理解(分类/情绪识别/问答)、端到端语音生成(TTS对话)等核心功能,真正把过去需要多个不同模型的能力,统一到一套模型架构之中!
是一款同时能听懂、听会、还能回答、还能说的超级音频模型,一步到位搞定音频所有需求。
比如用它做智能听写系统、语音版Chatbot、音频情绪检测之类的都是可以满足的。
- GitHub :https://github.com/MoonshotAI/Kimi-Audio
- HuggingFace:https://huggingface.co/moonshotai/Kimi-Audio-7B-Instruct
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/267645.html原文链接:https://javaforall.net


