
@
GLM-4V-9B 是智谱 AI 推出的最新一代开源视觉多模态模型,具备强大的图像理解、对话及推理能力。相比于云端 API,本地部署能更好地保护数据隐私,并显著降低长期使用的成本。
本教程将指导你如何在已安装 PyTorch 的 Linux 服务器上,快速完成 GLM-4V-9B 的部署与推理。
在开始之前,请确保你的服务器满足以下基础条件:
- 操作系统: Ubuntu 20.04+ (推荐)
- 显存:
- FP16 模式:至少 24GB(如 RTX 3090/4090, A10/A100)
- Int4 量化模式:至少 12GB(如 RTX 3060/4070)
- 已安装: Python 3.10+, CUDA 11.8+, PyTorch 2.0+
如果你已经安装了 PyTorch,可以进入该步骤安装额外的库来处理图像和复杂的 Tokenizer:
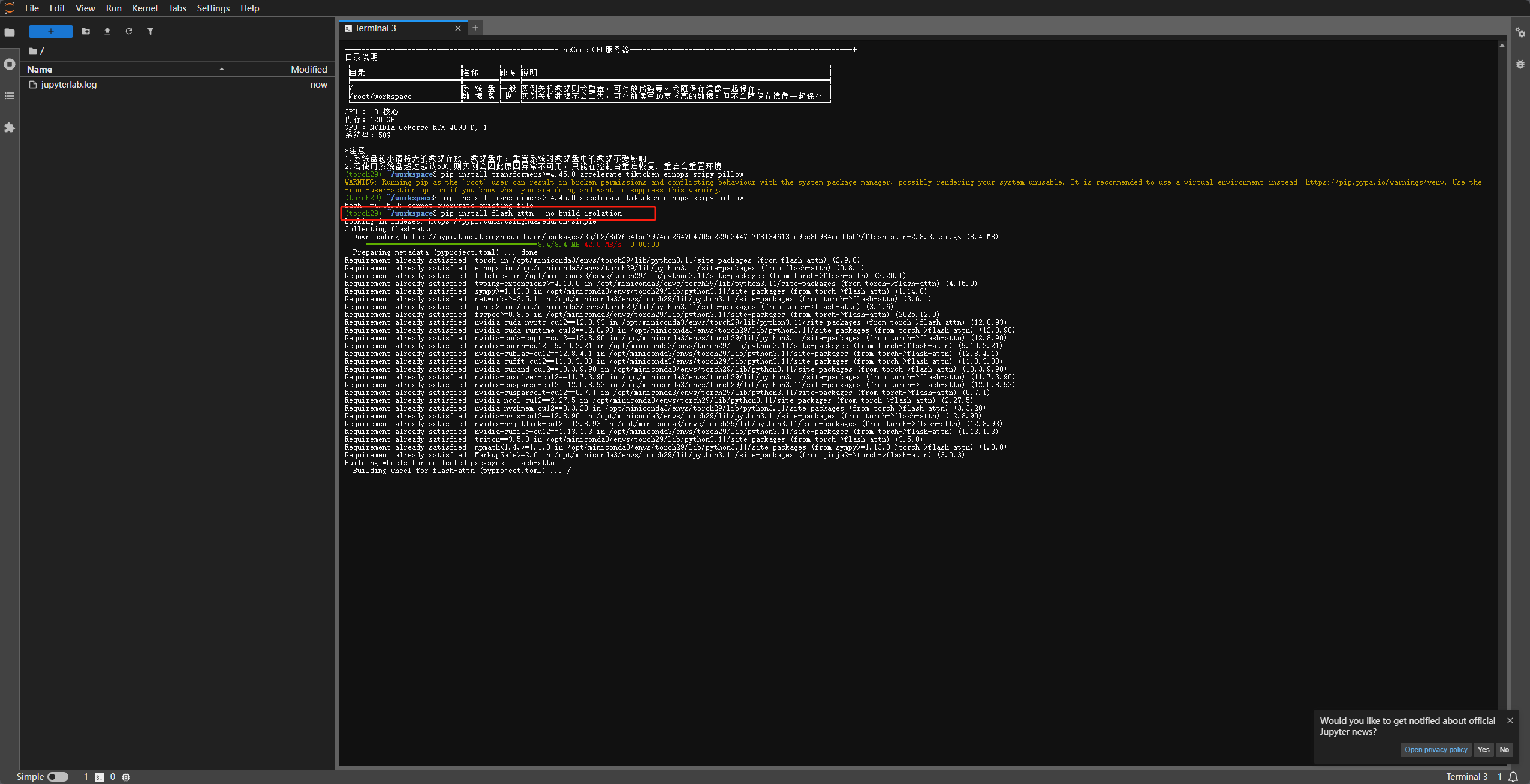
由于模型权重文件较大(约 18GB),国内用户推荐使用 ModelScope(魔搭社区),下载速度通常比 Hugging Face 快得多。
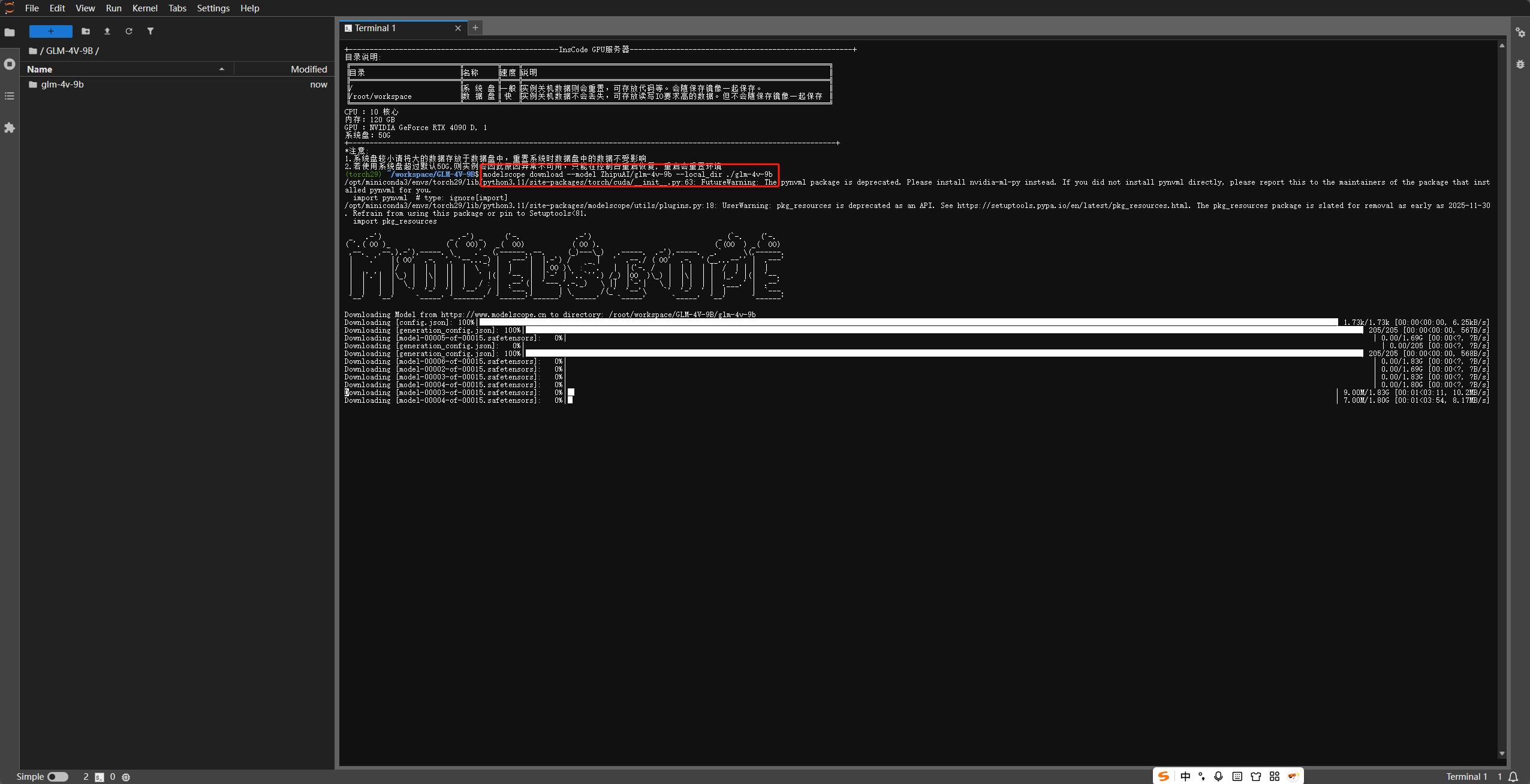
推荐用多线程脚本加速
创建一个 文件,填入以下代码。该脚本支持加载本地权重并进行一次图文对话。
智谱 AI GLM 教程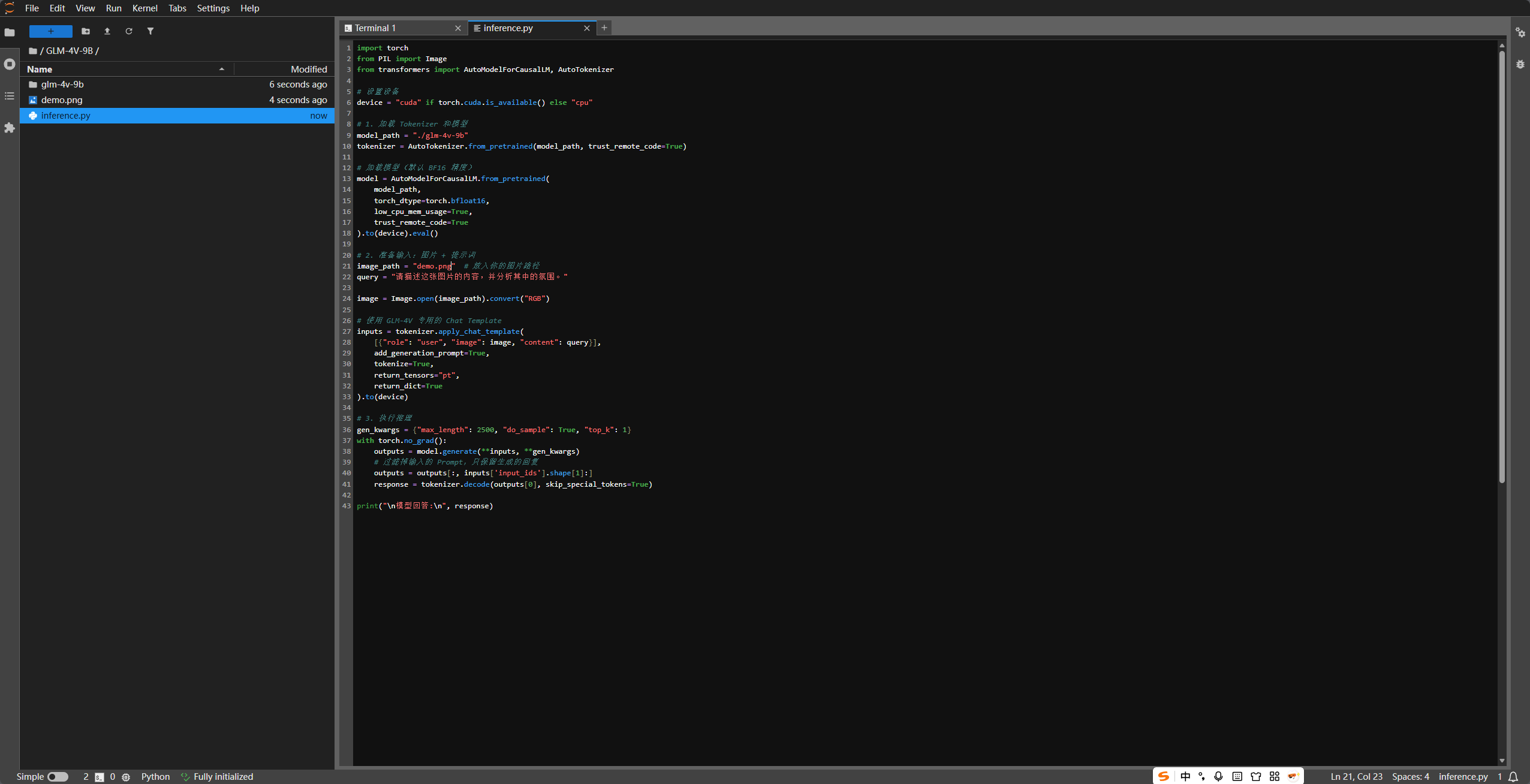
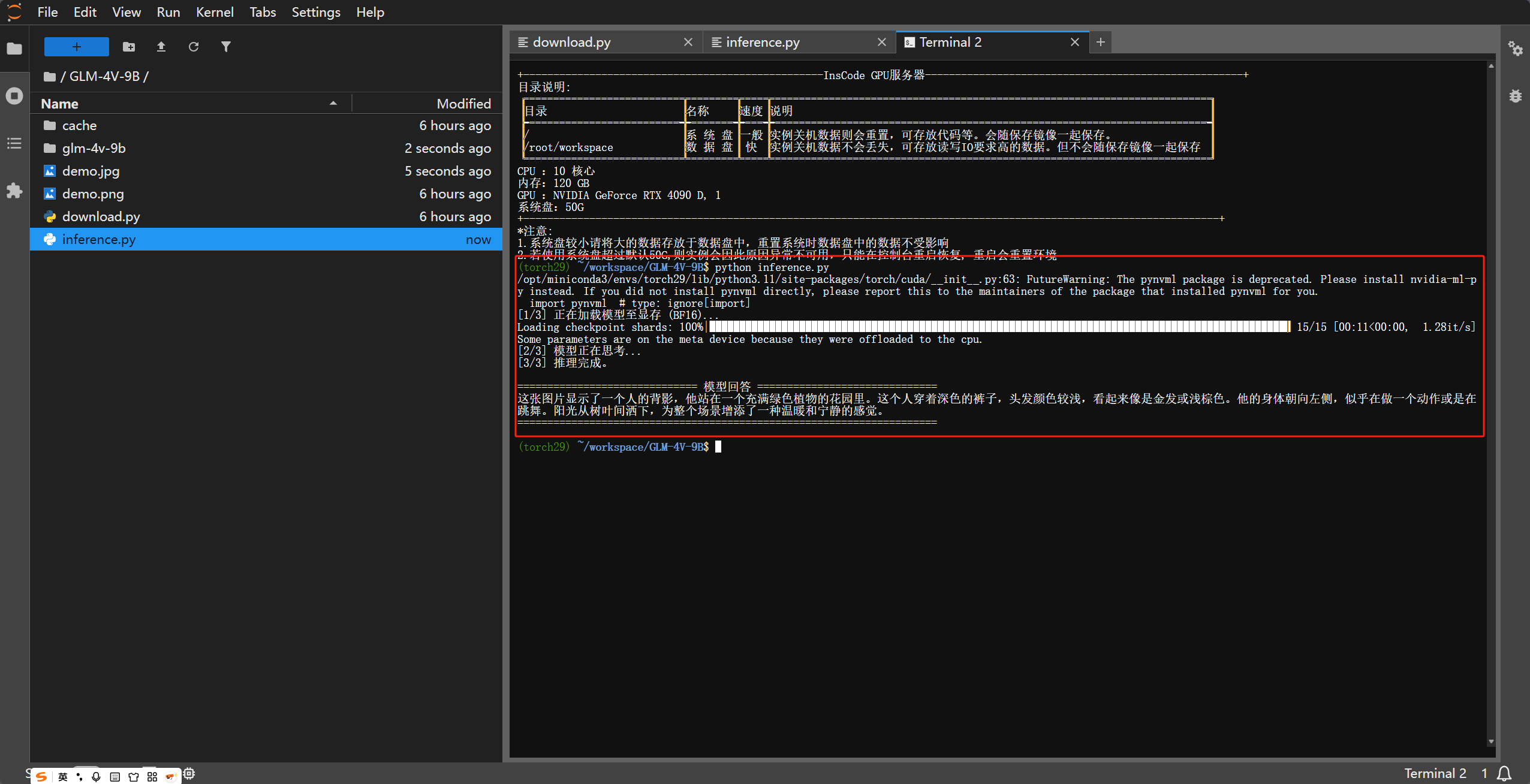
如果你的显存小于 20GB,可以通过 开启 4-bit 量化加载,显存占用将降至约 9-11GB。
首先安装:
修改模型加载部分:
如果你希望将模型作为 API 服务提供给前端使用,推荐使用 vLLM 框架,它的吞吐量比原生 Transformers 高出数倍。
部署后,你可以直接使用 的 SDK 调用它。
- 报错
- 解决: 请确保 版本大于 4.44.0。如果版本正确仍报错,检查 是否在模型目录中。
- 显存溢出 (OOM)
- 解决: 减小 ;或者使用上文提到的 4-bit 量化方案。
- 图片识别效果差
- 解决: 检查图片读取时是否转换为了 ,GLM-4V 对灰度图或带 Alpha 通道的图可能不兼容。
GLM-4V-9B 展现了极强的图文理解能力,通过本地部署,你可以将其集成到自动化办公、智能安检、医疗影像辅助等多种私有化场景中。如果你在部署过程中遇到问题,欢迎在评论区交流!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/267648.html原文链接:https://javaforall.net


