
你是否试过在深夜赶海报,对着空白画布发呆半小时?是否想过“如果我描述一个画面,AI就能立刻生成一张高清图该多好”?现在,这个想法已经不是幻想——智谱AI推出的GLM-Image,正以极简的Web界面,把专业级图像生成能力交到你手上。
它不依赖命令行、不折腾环境配置、不写一行Python代码。打开浏览器,输入一句话,点击生成,几秒后一张构图完整、细节丰富、风格可控的AI图像就出现在眼前。本文将带你从零开始,手把手走完全部操作流程:如何启动服务、加载模型、写好提示词、调出理想效果、保存成果,甚至避开新手最常踩的5个坑。全程无需技术背景,只要你会打字、会点鼠标,就能上手。
GLM-Image不是Stable Diffusion的复刻版,也不是Luma或Runway那种黑盒SaaS。它是智谱AI自主研发的端到端文生图模型,核心优势不在参数量,而在工程落地友好性。
简单说:如果你想要的是“今天装好,今晚就能用”,而不是“装了三天,还在配环境”,那GLM-Image Web界面就是为你设计的。
别被“34GB模型”吓住——整个过程比安装微信还简单。我们分两步走,每步都有截图指引。
2.1 确认服务状态(90%的问题都卡在这一步)
当你拿到镜像后,系统通常已预启动HTTP服务。但为防万一,请先确认:
- 打开终端(Ctrl+Alt+T),输入以下命令:
- 如果返回类似 的进程,说明服务已在运行;
- 如果无任何输出,则需手动启动。
注意:不要重复执行启动命令。若已运行却再次执行,会导致端口冲突,界面打不开。
2.2 一键启动(仅需一条命令)
执行这行命令即可:
你会看到类似这样的输出:
此时服务已就绪。无需记IP、不用查端口、不改配置文件——默认就是 。
2.3 访问界面:三秒打开,所见即所得
- 打开任意浏览器(Chrome/Firefox/Edge均可)
- 在地址栏输入:
- 回车,你将看到这个界面:
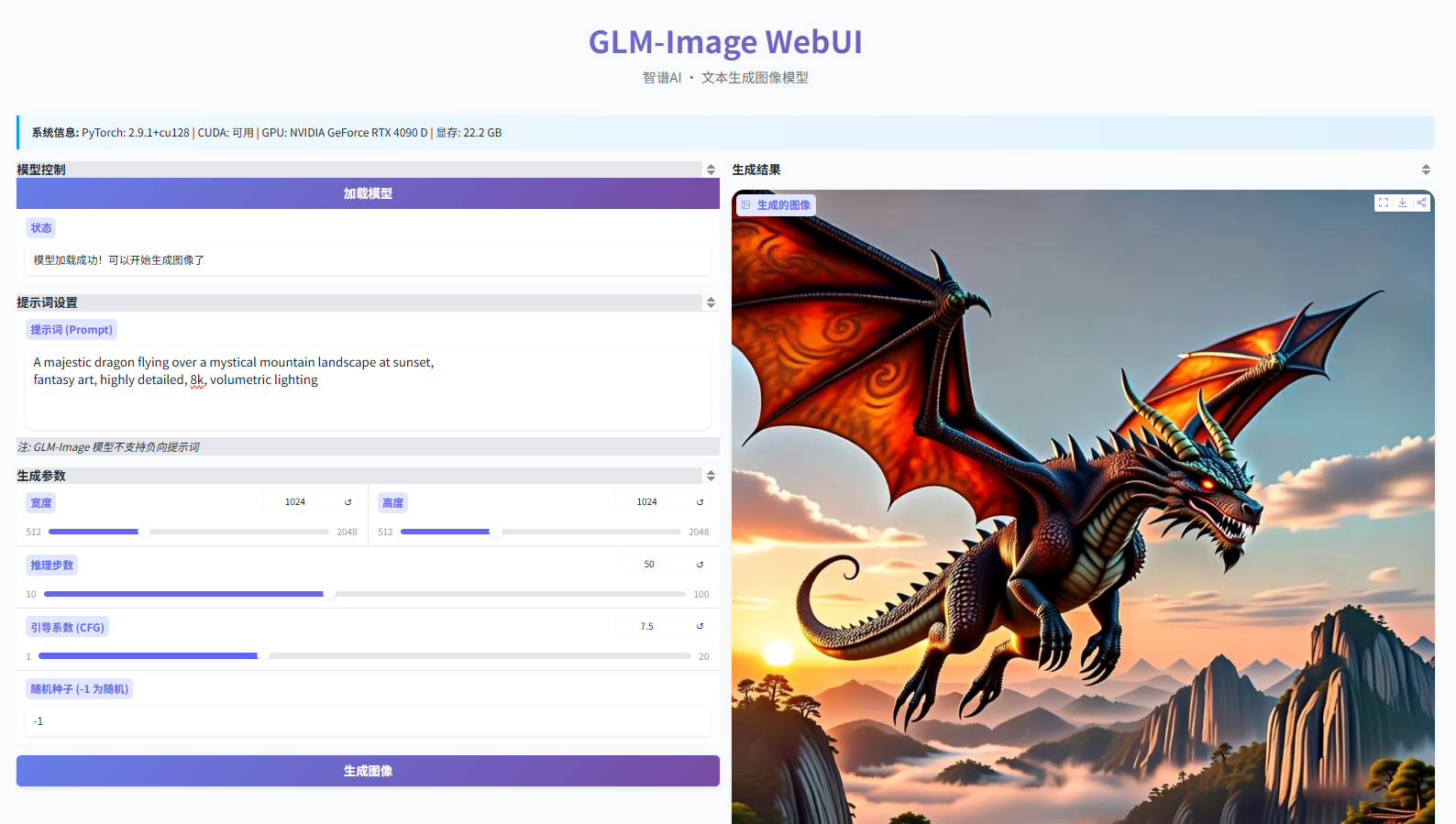

小贴士:如果打不开,请检查是否在虚拟机中运行——部分镜像需将网络模式设为“桥接”,而非NAT;若在云服务器部署,需在安全组放行7860端口,并将URL中的 替换为服务器公网IP。
首次使用必须加载模型。这是唯一需要等待的环节,但值得。
3.1 点击「加载模型」按钮
在Web界面左上角,找到蓝色按钮「加载模型」,单击。
- 界面右下角会出现进度条与日志滚动;
- 日志中会显示 ,表示正在拉取;
- 全程约需8–15分钟(取决于网络速度),期间可离开做其他事。
3.2 如何判断加载成功?
出现两个明确信号:
- 进度条走满,日志末尾显示 ;
- 「正向提示词」输入框下方出现绿色提示:“ 模型已就绪,可开始生成”。
❗ 常见失败原因排查:
- 网络中断:重试即可,脚本支持断点续传;
- 磁盘空间不足:确保 所在分区有≥50GB空闲;
- Hugging Face访问受限:镜像已预置国内镜像源(),无需额外配置。
很多人以为提示词越长越好、越英文越好。其实对GLM-Image而言,清晰、具体、符合中文语境才是关键。
4.1 正向提示词:讲清“你想要什么”
请按这个结构组织你的描述(缺一不可):
好例子(直接复制可用):
❌ 差例子及问题分析:
- “狗” → 太模糊,模型无法判断品种、姿态、环境;
- “很酷的图” → 主观词无意义,模型无法映射;
- “A dog, best quality” → 中英混杂且无上下文,中文理解优先级下降。
4.2 负向提示词:告诉模型“你不要什么”
这不是可选项,而是提升质量的关键开关。常用排除项:
实用技巧:
- 如果生成图总带奇怪边框,加上 ;
- 如果人物脸型扭曲,加上 ;
- 如果想避免AI味过重,加上 (反向强化真实感)。
4.3 提示词调试心法:三轮迭代法
别指望一次成功。按此节奏快速试错:
- 第一轮:用最简描述生成(如“山水画,远山近水”),确认基础构图正确;
- 第二轮:加入风格与画质词(如“宋徽宗风格,绢本设色,工笔细描”),观察质感变化;
- 第三轮:微调负向词(如去掉 后发现图中出现乱码,就加回 ),锁定最终版本。
界面右侧有5个核心参数滑块。我们只聚焦真正影响结果的3个,其余保持默认即可。
5.1 分辨率:从“能看清”到“能印刷”的跨越
- 默认值:1024×1024
- 推荐范围:512×512(快速预览)→ 1024×1024(社交分享)→ 1536×1536(公众号封面)→ 2048×2048(印刷级)
注意:分辨率每翻一倍,显存占用约增3倍。若生成中途报错“CUDA out of memory”,请立即降低分辨率。
5.2 推理步数(Inference Steps):质量与时间的平衡点
- 默认值:50
- 实测效果对比:
- 30步:出图快(约45秒),但细节偏平、边缘略糊;
- 50步:黄金平衡点,细节丰富,色彩自然,推荐日常使用;
- 75步:纹理更锐利,适合特写类图像(如珠宝、织物),耗时增加约60%。
5.3 引导系数(Guidance Scale):让AI“听你的话”
- 默认值:7.5
- 作用:数值越高,AI越严格遵循提示词;越低,越自由发挥。
- 推荐策略:
- 描述具体时(如“穿红裙子的少女”)→ 设为8.0–9.0,确保颜色准确;
- 描述抽象时(如“孤独感”“科技未来”)→ 设为5.0–6.5,保留创意空间;
- 若生成图严重偏离描述 → 先提高引导系数,再检查提示词是否歧义。
隐藏技巧:勾选「随机种子」旁的锁形图标,可固定本次种子。当你调出满意效果后,只需改一个词(如把“白天”换成“夜晚”),就能生成同构图不同氛围的系列图。
点击「生成图像」后,界面右侧实时显示生成进度条与预览图。
6.1 查看结果:四层信息,一目了然
生成完成后,右侧区域显示:
- 主图:最高清渲染结果(与设定分辨率一致);
- 缩略图栏:底部横向排列4张小图,展示本次生成的多样性(因随机性产生);
- 参数面板:精确记录本次使用的全部参数(含种子值),方便复现;
- 提示词回显:正/负向词原文,防止误操作覆盖。
6.2 保存位置:路径固定,命名规范
所有图像自动保存至:
文件名格式为:
例如:
💾 本地导出建议:使用或FTP工具连接服务器,进入该目录批量下载;或在WebUI界面右键图片 → “另存为”,直接保存当前预览图(分辨率略低,适合快速分享)。
这些不是文档里写的,而是我在连续生成200+张图后总结的真实心得。
7.1 快速切换风格:建一个「提示词模板库」
新建文本文件 ,存入常用组合:
每次生成前,复制对应模板,再填入具体内容,省去重新构思时间。
7.2 批量生成:用「随机种子」制造系列图
- 设定固定分辨率、步数、引导系数;
- 将种子值从1开始,每次+1,连续生成10张;
- 得到10张构图一致、细节各异的图,任选最优解。
7.3 修复局部:先生成大图,再用PS裁切放大
GLM-Image对整体构图把控强,但对毫米级细节(如印章文字、袖口刺绣)生成尚不稳定。建议:
- 先生成1536×1536主图;
- 用Photoshop打开,选取局部(如手部)→ 放大至300% → 应用“超分辨率”滤镜增强;
- 效果远胜直接生成4096×4096(后者易崩)。
7.4 降低显存压力:启用CPU Offload(适合24GB以下显卡)
编辑启动脚本:
在 前添加环境变量:
保存后重启服务。实测RTX 3090(24GB)可稳定运行1024×1024@50步,RTX 4060(8GB)可跑512×512@30步。
7.5 自定义快捷键:给高频操作提速
WebUI支持键盘操作:
- :快速提交生成(替代鼠标点击);
- :在正向词→负向词→宽度→高度→步数→引导系数间顺序切换;
- :清空当前输入框。
每天节省10次鼠标点击,一年就是3650次——技术人的优雅,藏在细节里。
回顾一下,你刚刚完成了整套工作流:
- 启动服务(1条命令)
- 加载模型(1次点击,静待完成)
- 编写提示词(按“主体+场景+风格+画质”结构)
- 设置参数(分辨率/步数/引导系数,三者定乾坤)
- 生成与保存(结果自动归档,路径固定)
你不需要成为算法工程师,也不必啃透Diffusers源码。GLM-Image Web界面的设计哲学,就是把复杂留给自己,把简单交给用户。
下一步,你可以:
- 尝试生成一组“节气海报”,用24个提示词批量产出全年视觉;
- 把生成图导入Figma,作为UI设计初智谱 AI GLM 教程稿快速验证;
- 或干脆关掉教程,打开界面,输入你此刻最想看见的画面——比如“一只猫在火星基地窗边看地球升起”。
技术的意义,从来不是让人仰望参数,而是让人伸手就能触达想象。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/268430.html原文链接:https://javaforall.net


