
在大型语言模型(LLM)的应用落地中,RAG(检索增强生成)是解决模型幻觉和知识时效性的关键技术。本博客将对本多文档高精度智能分析与问答系统的关键技术进行说明介绍。该系统集成了 在线 OCR 解析、Milvus 混合检索(向量+关键词) 以及 多维度的重排序(Reranker) 策略,旨在提升低资源环境下的检索准确率,以实现高精度多文档分析与问答。
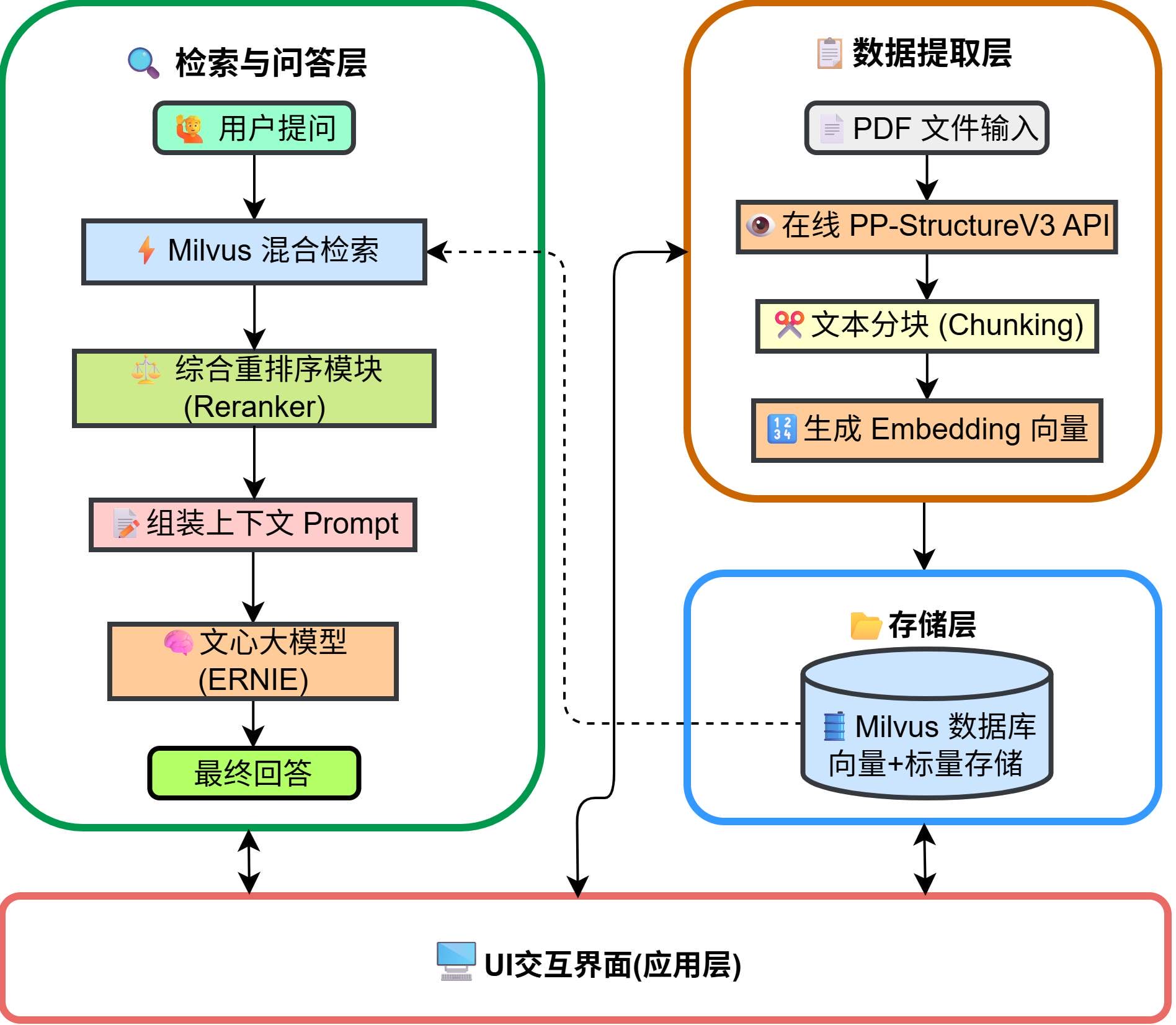
本项目的系统主要由四个核心模块组成:
- 数据提取层:使用在线 OCR API 进行高精度的文档布局分析(Layout Parsing)。
- 存储层:利用 Milvus 向量数据库存储 Dense Embedding,同时维护倒排索引以支持关键词检索。
- 检索与问答层:实现向量检索与关键词检索的加权融合(RRF),集成 ERNIE 大模型 API 接口生成回答。
- 应用层:基于 Gradio 构建交互界面。

- 🐙 GitHub 代码仓库:点击访问
- 🚀 星河社区在线应用:立即体验
- 📓 星河社区 Notebook:在线运行
针对科研论文中常见的双栏排版、公式混排及图表嵌入问题,传统的 PyPDF2 等纯文本提取工具往往力不从心(容易导致段落乱序、表格崩坏)。
为此,本项目在 backend.py 中封装了 OnlinePDFParser 类,直接集成 PP-StructureV3 在线 API 进行高精度的文档布局分析(Layout Parsing)。
该方案具备三大核心优势:
- 结构化输出:直接返回 Markdown 格式(自动识别标题层级、段落边界)。
- 图表提取:在解析文本的同时,自动提取文档中的图片并转存,为后续的“多模态问答”提供素材。
- 上下文保留:基于滑动窗口进行切分,防止关键信息在切片边界丢失。
2.1.1 核心解析逻辑
在 backend.py 中,我们构建了 API 请求,将 PDF 文件流发送至服务端,并解析返回的 layoutParsingResults,提取出清洗后的 Markdown 文本和图片资源。
2.1.2 滑动窗口文本分块
拿到结构化的 Markdown 文本后,为了避免语义被生硬切断(例如一句话跨了两个 chunk),我们实现了一个带有 overlap(重叠区)的滑动窗口分块策略。
2.2.1 知识库命名的工程化处理
在实际部署中,Milvus 等向量数据库对集合名称(Collection Name)通常有严格的命名限制。为了解决这一问题,我们在后端代码中实现了一套透明的编解码机制。
- 编码 (Encode):当用户创建如“物理论文”的库时,系统将其 UTF-8 字节转换为 Hex 字符串,并添加 前缀。
- 解码 (Decode):在前端展示时,自动将 Hex 字符串反解为原始中文。
2.2.2 向量化入库与元数据绑定
在 OCR 解析并将长文本切分为 Chunks 后,系统并非简单地将文本存入数据库,而是执行了 “向量化 + 元数据绑定” 的关键步骤。
为了支持后续的精确溯源(Citation)和多模态问答,我们在设计 Milvus Schema 时,除了存储 384 维的 Dense Vector 外,还强制绑定了 filename(文件名)、page(页码)和 chunk_id(切片 ID)等标量字段。
这一过程在 vector_store.py 中通过 insert_documents 方法实现,采用批量 Embedding 策略以减少网络开销:
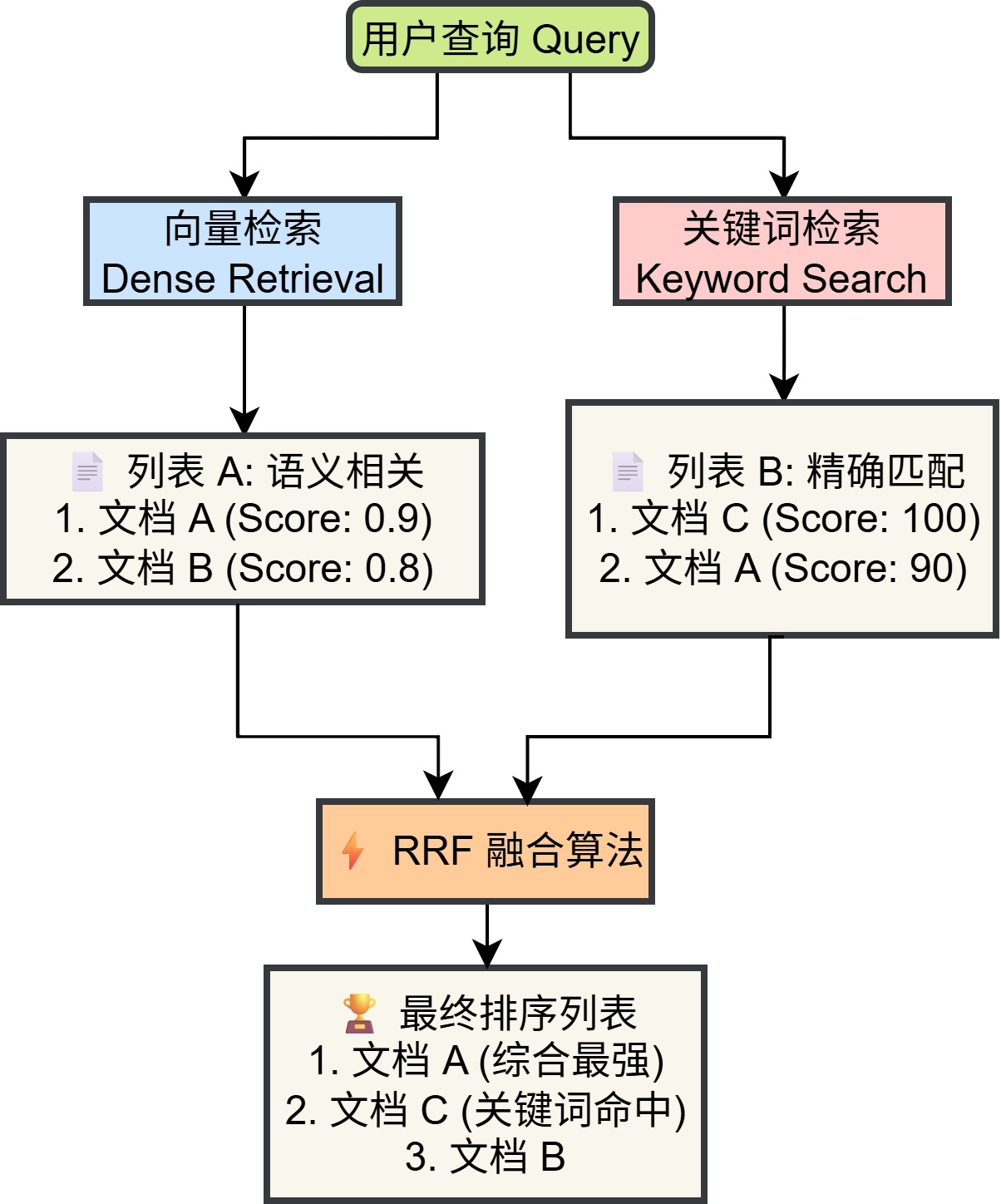
2.2.3 混合检索策略
检索前,系统首先利用 LLM 生成的问题的双语翻译,避免中文问题询问英文文档,使得关键词不匹配,以最大化语义覆盖。随后并行执行两路检索:
- Dense (向量检索):捕捉语义相似度(例如“简谐振子”与“弹簧振子”的语义关联)。
- Sparse (关键词检索):弥补向量模型对专有名词或精确数字匹配的不足(例如精确匹配公式中的变量名)。
向量检索容易因语义泛化而召回错误概念(如“弹簧振子”与“简谐振子”),而关键词检索能确保专有名词的精确命中,从而大幅提升准确率。
然后执行:
- RRF (倒排融合):系统内部使用倒排秩融合算法 (Reciprocal Rank Fusion) 将两路结果合并,确保多样性。
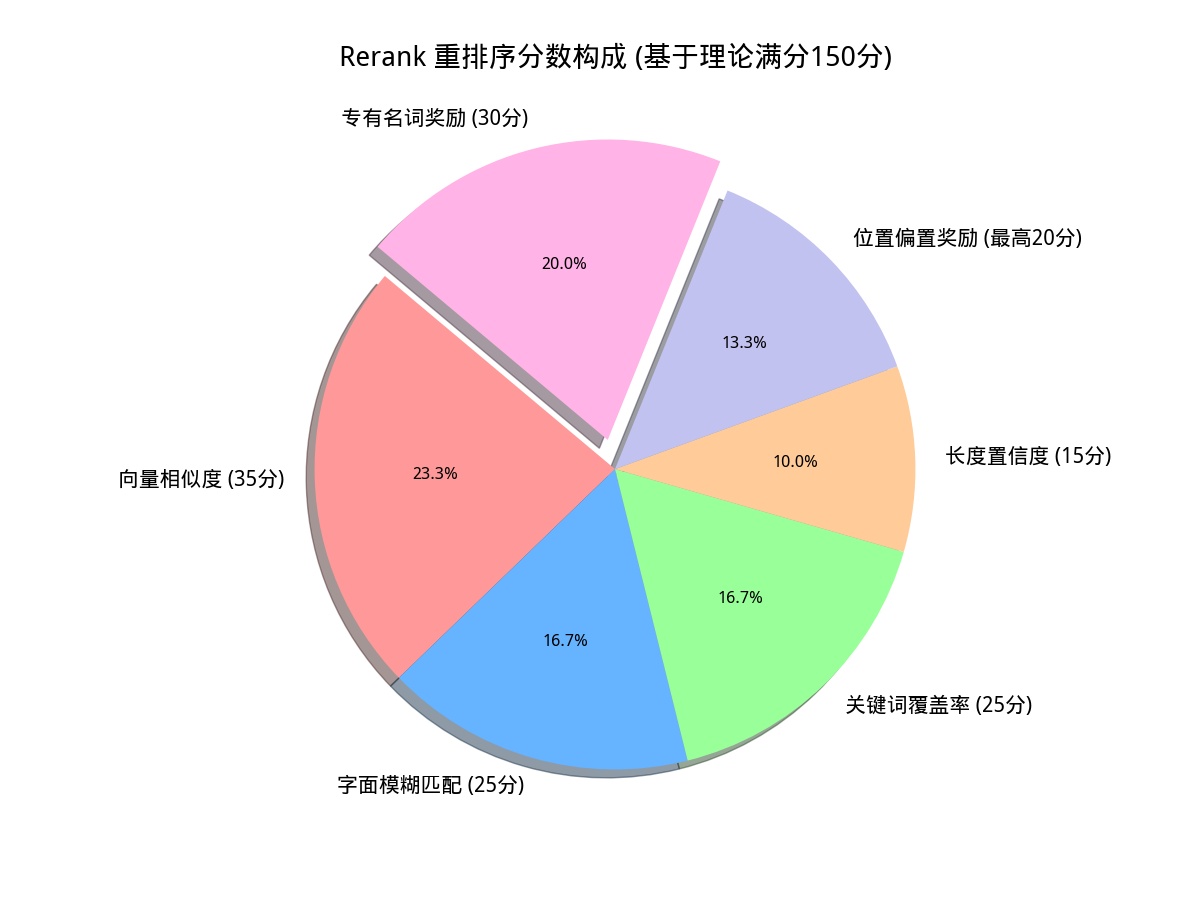
检索回来的片段(Chunks)需要进一步精排。在 中,设计了一套综合打分算法。 评分维度包括:
- 模糊匹配(Fuzzy Score):使用 计算 Query 与 Content 的字面重合度。
- 关键词覆盖率(Keyword Coverage):计算 Query 中的核心词在文档片段中的出现比例。
- 语义相似度:来自 Milvus 的原始向量距离。
- 长度惩罚与位置偏置:对过短的片段进行惩罚,对 Milvus 召回的排名靠前的片段给予位置奖励。
- 专有名词:
- 英文(看“大小写”特征): 使用正则 ,专门匹配首字母大写的单词(如 “Milvus”)或全大写的缩写(如 “RAG”),因为在英文中这些通常代表专有名词。
- 中文(看“连续性”特征): 由于中文没有大小写,策略变成了 “文心一言 ERNIE Bot 教程切分+长度”:使用非中文字符作为分隔符切断句子,保留所有连续出现 2 个及以上的汉字片段(如“简谐振子”),将其视为潜在实体。
具体的分数占比见下图:
这种基于规则与语义结合的重排序策略,在无训练数据的情况下,比纯黑盒模型更具可解释性。
在调用 LLM 或 Embedding 服务时,偶尔会遇到 。本项目在 中实现了自适应降速机制:
这保证了系统在大批量文档入库时的稳定性。
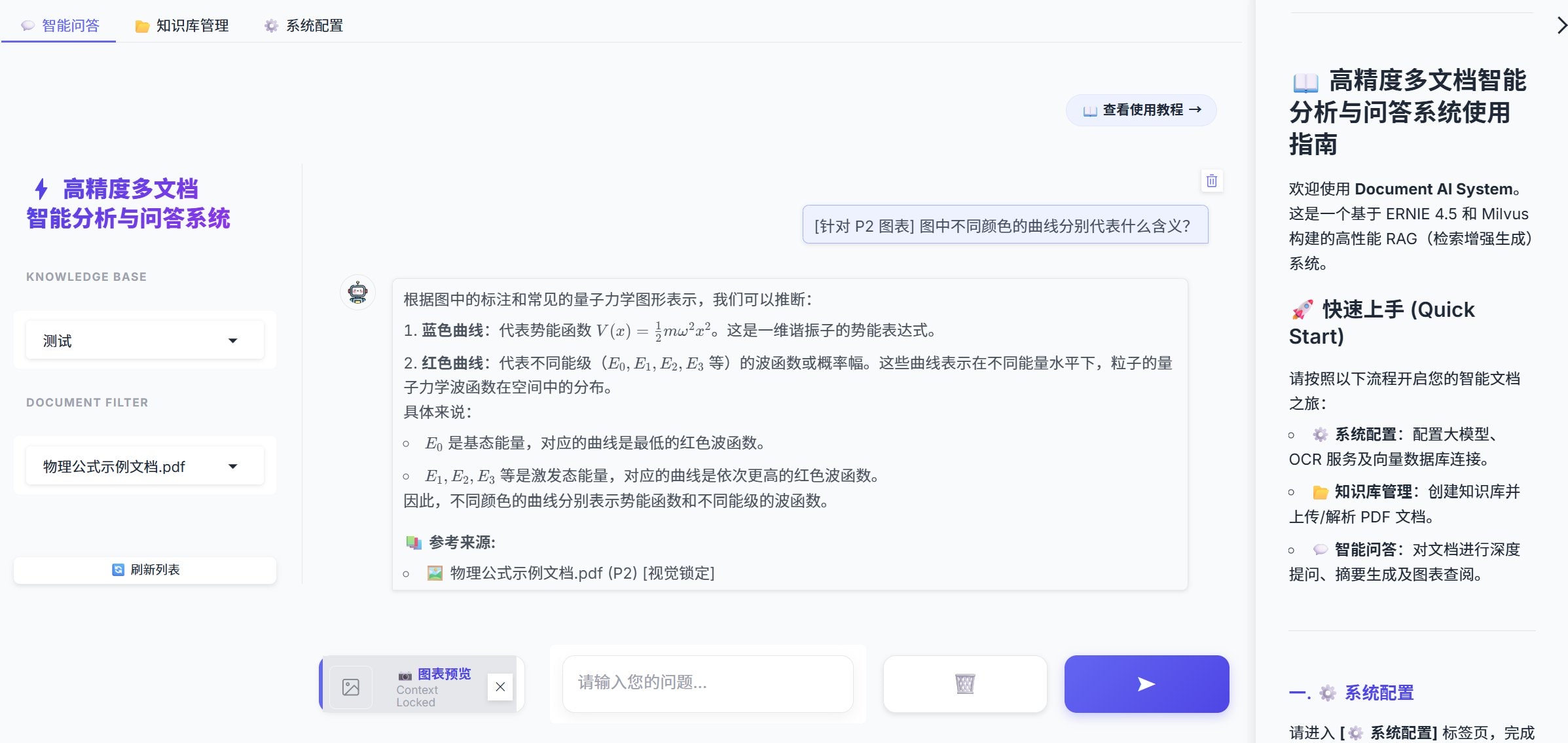
针对科研文档中包含大量关键图表(如实验数据、模型架构)的特点,本系统实现了“图表锁定”问答功能。核心技术实现包含以下三个维度:
- 上下文增强 Prompt 后端在构建请求时,不仅发送图片本身,还检索该图片所在页面的 OCR 文本作为背景信息(Context)。Prompt 结构动态拼装了“图片元数据 + 背景文本 + 用户问题”,有效提升了模型对图表细节与上下文关联的理解能力。
- Vision 接口封装 底层客户端()实现了 OpenAI 兼容的视觉协议。系统自动读取本地图片并转换为 Base64 编码,通过 格式构建多模态消息体,实现了图像数据与文本指令的联合推理。
- 降级策略 为保障系统的高可用性, 中设计了自动回退机制。若多模态接口调用异常(如模型不支持或网络错误),系统将自动捕获异常并无缝切换至标准文本 RAG 通道,利用 OCR 文本继续回答,确保用户对话流程不中断。
前端基于 Gradio 搭建(),采用自定义 CSS () 搭建了美观的 UI 界面。重点改进了输入区域的视觉层级:将默认的灰色背景改为白底圆角卡片,并为发送按钮添加了渐变色与悬浮阴影,使其在视觉上更加现代与聚焦。
为了保证公式在 UI 界面上能正常渲染出来,首先定义一套完整的 LaTeX 识别规则,涵盖行内与行间公式.这套配置被同时配置到对话框(Chatbot)和摘要区(Markdown),确保无论是模型的回答还是文档的摘要,公式都能被渲染:
随后,在实例化组件时将此配置注入:
在实际体验中,为了打破 RAG 系统的“黑盒”属性,本应用在界面中设计了两个维度的评价指标,分别对应微观与宏观视角:
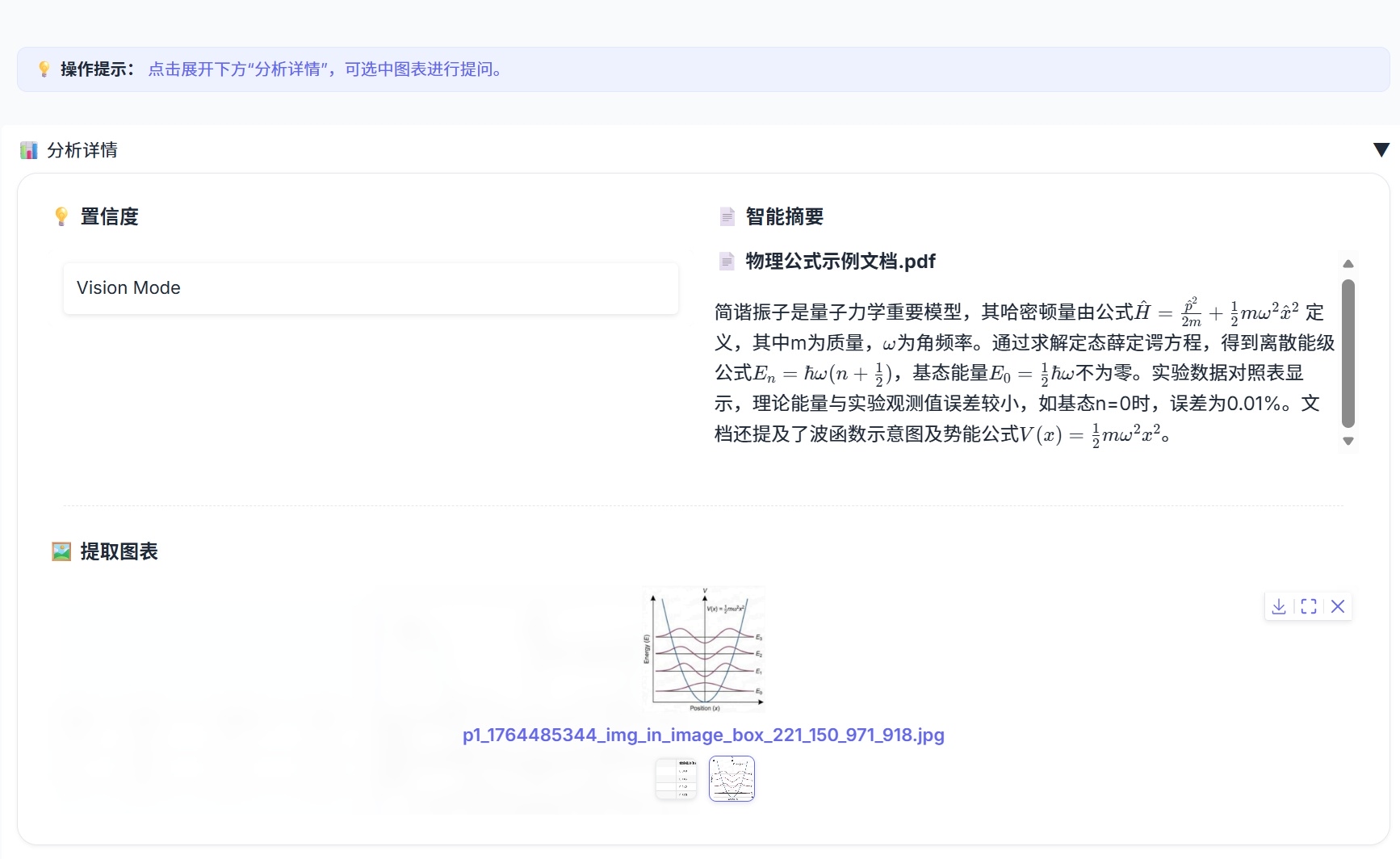
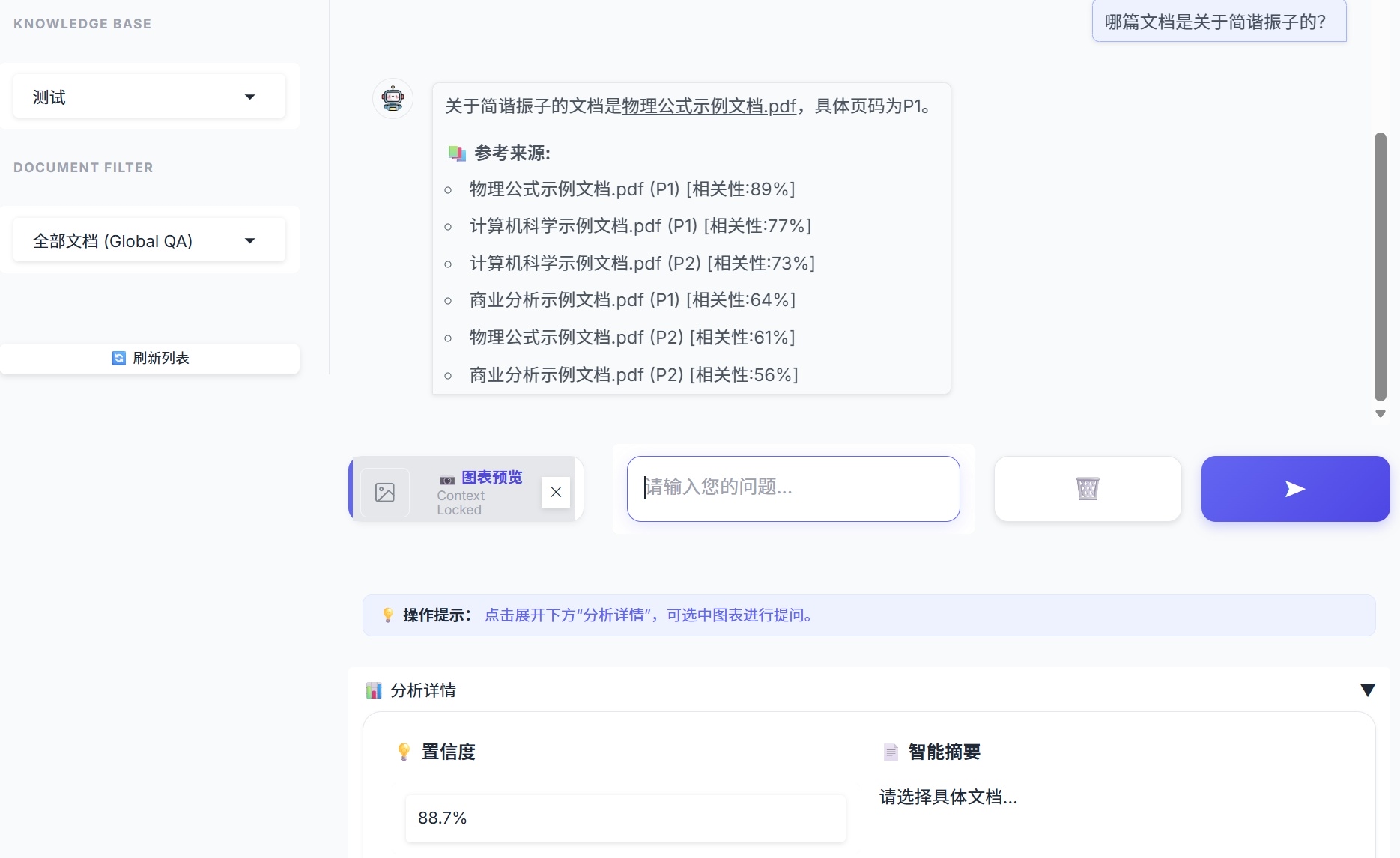
- 相关性 (Relevance):出现在聊天框的【参考来源】列表中。这是一个微观指标,它直接展示了 给每一个具体文档切片打出的 (基于向量+关键词+规则的综合得分)。它的作用是告诉用户:“为什么系统引用了第 3 页这段话,而不是第 5 页那段?”
- 置信度 (Confidence):展示在【分析详情】面板中。这是一个宏观指标,系统提取 Top-1 切片的得分并进行归一化(Capped at 100%)作为本次问答的整体评分。它的作用是预警:“系统对自己生成的答案有多大把握?” 如果置信度低于 60%,即便模型生成的文字再通顺,用户也应警惕可能存在的“幻觉”风险。
实现的 UI 界面效果如下,在回答中显示了相应来源向量的页数和相关性:
- 高精度问答:集成 百度文心一言(ERNIE Bot) 大模型 API,利用 ERNIE 大模型卓越的语义理解与生成能力,配合“向量+关键词”双路混合检索与 RRF 重排序算法,确保回答的精准度与鲁棒性。
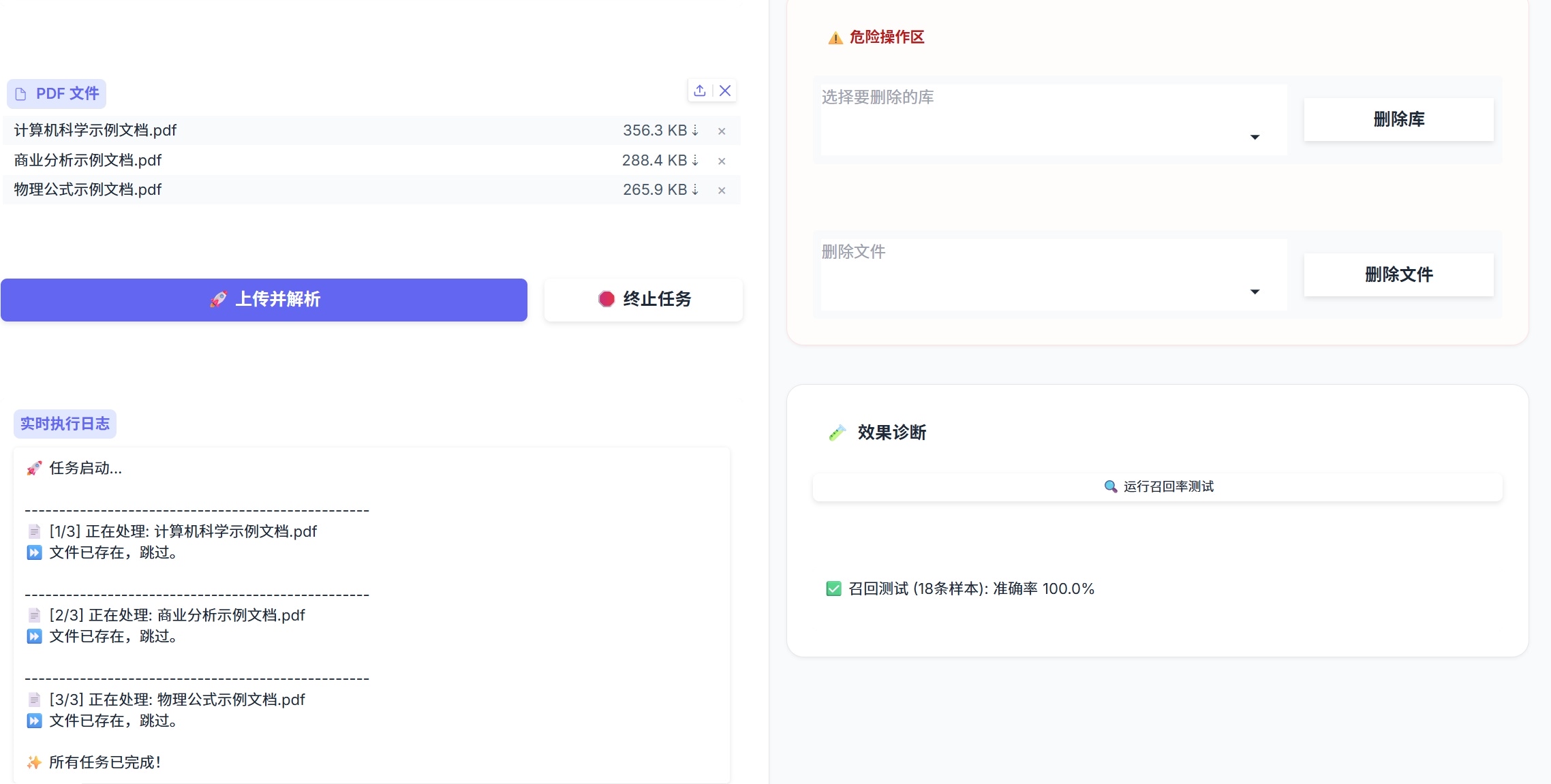
- 多知识库管理:支持动态创建、切换和删除知识库。
- 召回率自测:内置 函数,自动从库中抽取样本验证检索准确率。
- 实时反馈:上传大文件时,通过进度条实时显示 OCR 解析与 Embedding 入库进度。
通过结合 Milvus 的向量能力与传统的关键词匹配技术,并辅以细粒度的重排序策略,本系统在低成本下实现了较高精度的文档问答。未来的优化方向将集中在:
- 引入本地 BGE-Reranker 模型替代规则打分。
- 利用提取的图片信息增强多模态问答能力。
衷心感谢张晶老师帮助我理解项目需要实现的目标,并给予在系统设计与实现细节上的指导,使得我能够完成项目。
感谢杨有志老师在星河社区部署上线过程中的大力支持。
感谢李成龙老师在 Milvus 向量检索方面提出的建议。
很荣幸参与启航计划(第 6 期),未来我将持续深耕,为开源社区贡献更多力量。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/268515.html原文链接:https://javaforall.net


