


前引:在大模型应用爆发的当下,AI 能力的工程化集成正成为开发者绕不开的课题 —— 繁琐的鉴权配置、格式严苛的请求参数、反复的调试迭代,往往让 “调用一个 API” 的简单需求变得耗时耗力。而当我尝试通过 Trae 工具,以 API KEY 方式对接豆包 1.6 大模型时,却切实感受到了 “工具赋能开发” 的具象化:从代码生成到问题排障,从参数调优到流程闭环,原本可能耗费数小时的集成工作,在 Trae 的辅助下变得流畅且高效。接下来,我将以这次实践为锚点,拆解其中的关键环节与体验思考!
目录
【一】Trae介绍
【二】技术架构与创新
【三】Trae版本下载与安装
【四】火山引擎API调用
(1)豆包1.6模型介绍
(2)完成大模型调用
(3)结构、功能展示(部分)
【五】调用展示
【六】Trae使用心得
(1)上手快
(2)问题报错
(3)响应体验
Trae 是字节跳动 2025 年推出的 AI 原生集成开发环境(AI IDE),定位为 “真正的 AI 工程师”,支持从需求分析到部署的全流程自动化。其核心功能包括:
Builder 模式:通过自然语言指令自动生成完整项目框架,涵盖代码编写豆包 大模型 教程、依赖安装、环境配置等环节。例如,开发医疗患者管理系统时,可自动对接数据库和 CRM 系统
智能问答与上下文感知:提供侧边栏和内联对话模式,支持代码解释、Bug 修复及实时推荐配置。AI 可理解整个项目上下文,预测开发者下一步操作并主动提示优化建议
多模型协同与工具生态:搭载豆包 1.5-pro、DeepSeek-R1 等模型,动态调度处理不同任务(如逻辑拆解、代码优化)。通过 MCP 协议标准化工具调用,无缝对接 GitHub、Figma 等第三方服务
- 交互层:支持跨终端操作,提供轻量化界面和需求分析模块,将自然语言转化为可执行任务
- 核心功能层:包含 AI 决策中枢,通过多模型协同实现代码生成、测试、部署的闭环,并管理项目快照以确保上下文一致性
- 基础能力层:构建代码知识图谱(CKG),解析代码依赖关系;LLM 适配层兼容多厂商模型,支持负载均衡
- 云端服务层:通过 AI 网关管理模型调用和第三方集成,保障弹性扩展与安全合规
- 关键技术:动态任务分解算法将复杂需求拆解为子任务(如前端生成、数据库设计),多模态模型支持解析设计稿生成代码,上下文理解引擎预测开发步骤并减少冗余操作
首先打开官网:,目前Trae Solo模式需要在官网申请体验码,感兴趣的小伙伴可以去申请!
挑选对应的版本选择下载:
然后我们双击安装:
打开Trae在主页找到登录,然后完成登录即可开始对话:
(1)豆包1.6模型介绍
模型版本 核心定位 上下文长度 核心特点 典型应用场景 关键优势 Doubao-Seed-1.6 综合全能型(All-in-One) 256K 支持深度思考(开启 / 关闭 / 自适应)、多模态理解、图形界面操作 办公纪要生成、PPT 逻辑检测、周报模板创建 能力全面,自适应调节效率 Doubao-Seed1.6-thinking 推理强化型 256K 聚焦代码编写、数学运算、复杂逻辑推理,复杂推理测试达全球前列水平 数学题批改、解题路径生成、代码开发 推理能力突出,超越人类平均水平 Doubao-Seed1.6-flash 极速响应型 256K 低延迟(TOPT 仅 10ms),视觉理解能力媲美友商旗舰模型 智能座舱实时交互、高频实时咨询 延迟极低,适配实时场景
- 版本分类:
- Doubao-Seed-1.6:这是一个 “All-in-One” 的综合模型,也是国内首个支持 256K 上下文的思考模型,具备深度思考、多模态理解以及图形界面操作等多项重要能力。其深度思考模式分为开启、关闭和自适应三种模式,自适应模式可依据任务难度自动判断是否启用深度思考功能,节省时间并减少 token 消耗
- Doubao-Seed1.6-thinking:是豆包大模型 1.6 系列在深度思考方面的强化版本,在代码编写、数学运算、逻辑推理等基础能力上有了进一步的显著提升,同样支持 256K 上下文,在复杂推理测试中表现卓越,已跻身全球前列水平。
- Doubao-Seed1.6-flash:此为豆包大模型 1.6 系列的极速版本,具有低延迟的显著优势,TOPT 仅需 10ms,非常适用于对延迟要求极高的实时交互场景,其视觉理解能力能够与友商的旗舰模型相媲美,也支持 256K 上下文
- 性能表现:
- 推理能力突出:豆包 1.6 首次实现国内大模型 256K 上下文推理能力,可处理超过 30 万字的长文本,较前序版本提升 8 倍。以高考全国新一卷数学为例,Doubao-Seed-1.6-thinking 模型通过多模态协同推理,最终取得 144 分的高分,超越人类考生平均水平
- 技术架构优化:延续稀疏 MoE(混合专家)架构,并引入 UltraMem 技术优化访存效率,使推理成本较传统 MoE 架构降低 83%,在参数激活量相同的情况下,模型效果超越稠密架构
- 价格优势:
- 豆包大模型 1.6 首创按 “输入长度” 区间定价。在企业使用最为频繁的输入区间 0-32K 范围内,价格为输入 0.8 元 / 百万 tokens、输出 8 元 / 百万 tokens,综合成本为 2.6 元 / 百万 Token,相比豆包大模型 1.5・深度思考模型等,综合成本下降了 63%。而且对于输入 32K、输出 200tokens 以内的请求,价格进一步降低至输入 0.8 元 / 百万 tokens、输出 2 元 / 百万 tokens
- 应用场景:
- 办公场景:能自动解析长达 300 页的会议录音并生成带待办事项的纪要,还可生成个性化周报模板、检测 PPT 逻辑漏洞等
- 汽车行业:为智能座舱赋予更强大功能,如车主说 “有点热” 时,能同步调节空调温度、开启座椅通风并播放清凉歌单,还支持跨设备联动
- 教育领域:可实时批改学生作文,精准标注问题并推荐替换案例,针对学生数学薄弱点生成专属解题路径
- 电商场景:能对商品图片进行规范审查,基于多模态能力对同类商品快速比价。
- 自动驾驶领域:可通过分析路采数据更准确识别汽车行驶方向和驾驶意图,为自动驾驶模型训练提供高质量数据支持
(2)完成大模型调用
首先我们打开火山引擎完成登录、认证:
可以选择下面的大模型,双击(以1.6大模型为例):
然后通过API KEY方式完成调用:
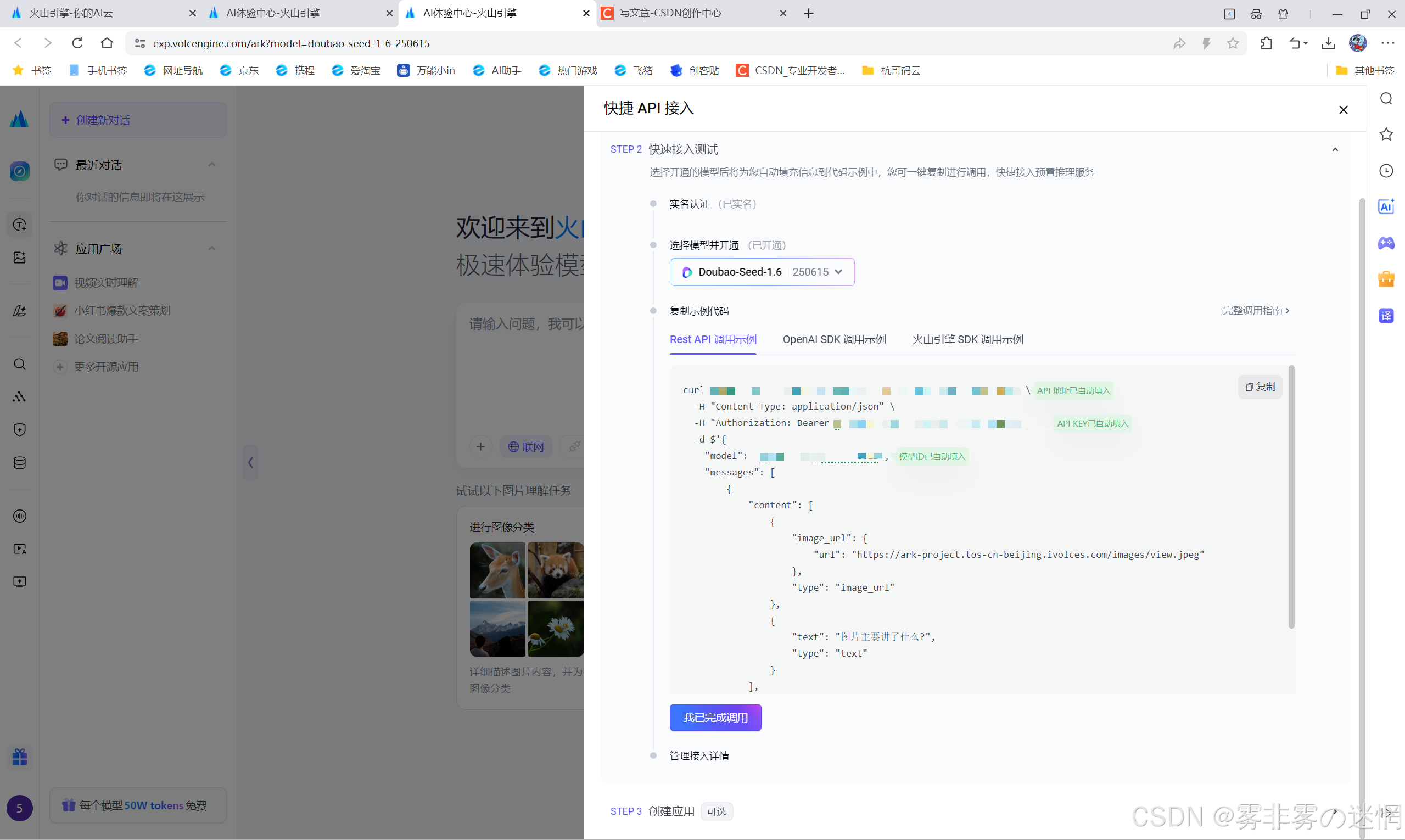
调用示例如下展示(API KEY等敏感信息已经经过修改,以便展示):
(3)结构、功能展示(部分)

(1)现有终端调用效果展示(敏感信息已修改):
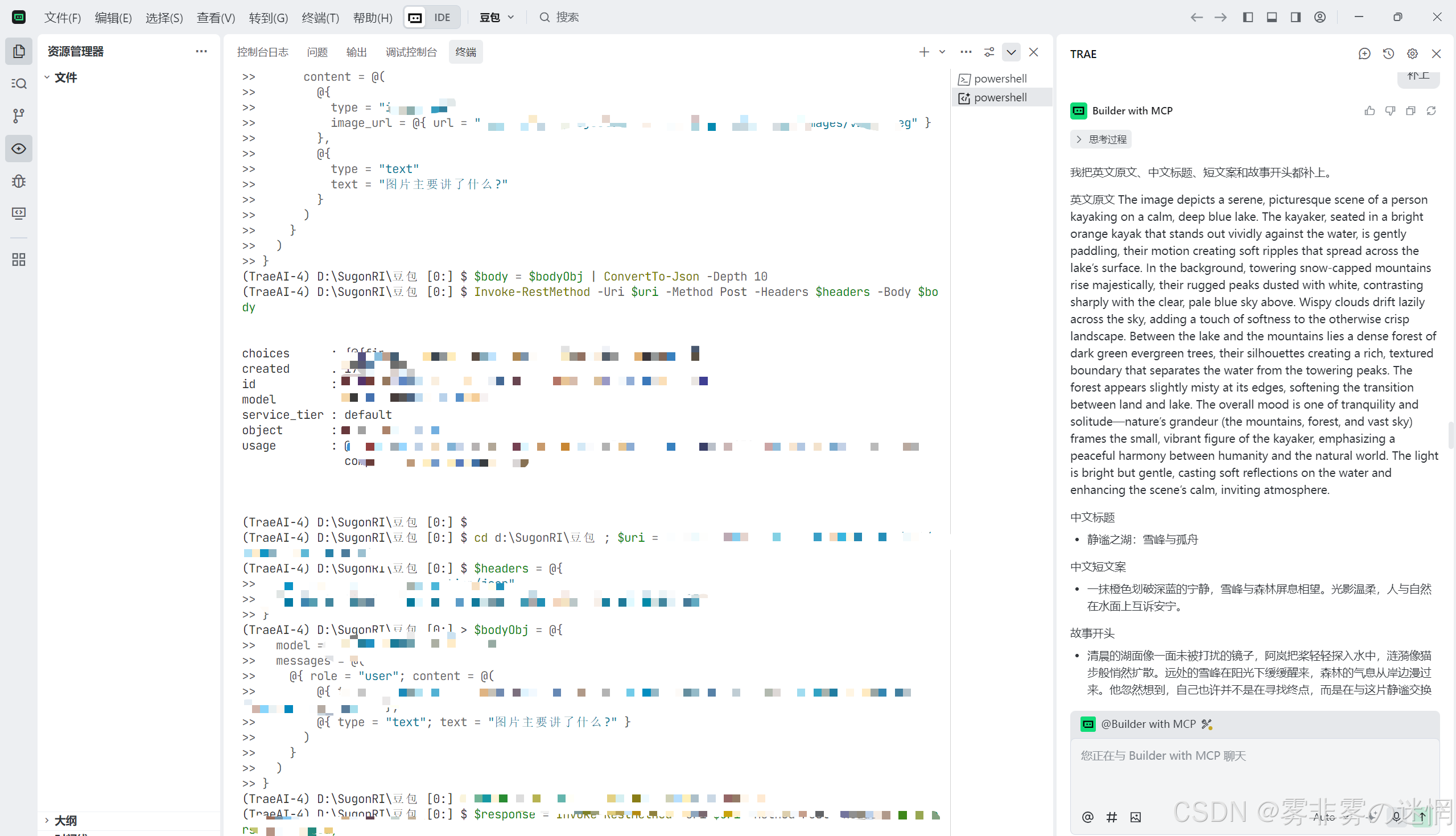
(2)对话框效果展示(含故事情节等信息):
(3)现在我们通过图形化界面来完成对话:
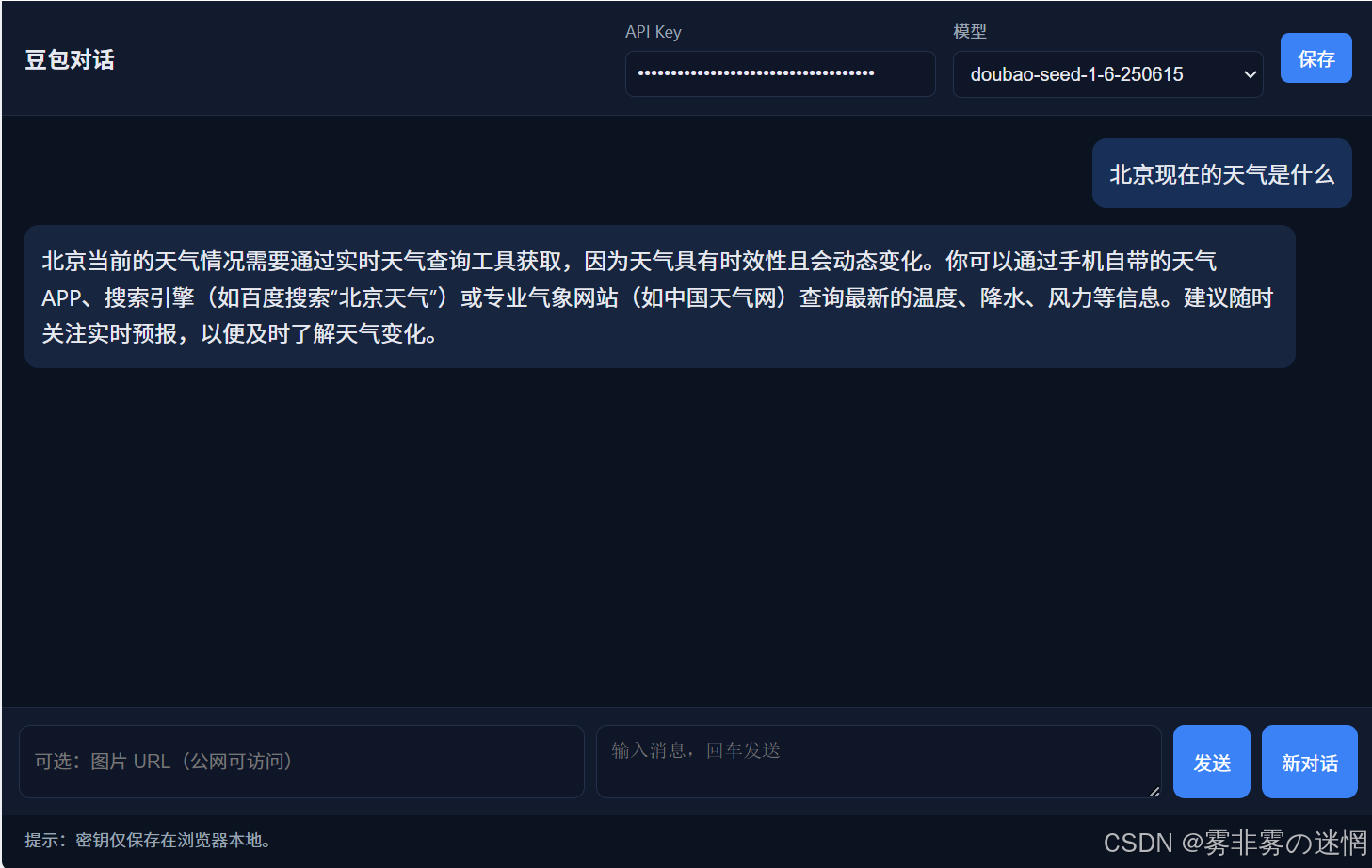
(1)上手快
我直接在 Trae 的 Builder 模式里用自然语言描述需求:接口地址、认证方式和参数。不到 20 秒,完整的 Node.js 代码就生成了,包括请求头、参数示例和基本错误处理
(2)问题报错
第一次运行时遇到 “axios 模块未找到” 的提示,Trae 自动建议安装依赖,我按提示执行就解决了。第二次遇到 “认证失败” 错误,我把报错信息拖进 Trae 的 AI 对话框,它立即指出是 Authorization 头格式问题(缺少 Bearer 与 API KEY 之间的空格)。修正后,调用成功,Trae的对话速度很快!每次可以帮我扩展资源,我想不到的它可以想到!
(3)响应体验
响应速度比预期快,返回内容自动格式化输出
上下文感知功能很实用,第二次继续优化代码时,Trae 能根据历史自动补全!
调试不同参数(如 temperature)非常方便,无需频繁手动修改代码

发布者:Ai探索者,转载请注明出处:https://javaforall.net/271051.html原文链接:https://javaforall.net


