


目录
一、模型介绍
二、模型部署
1、创建工作空间
2、下载模型
3、下载依赖
4、下载模型库
5、下载glm4_tokenizer
6、代码编程修改
4 月 26 日,Moonshot AI正式宣布推出Kimi-Audio,一款全新的开源音频基础模型,旨在推动音频理解、生成和交互领域的技术进步。这一发布引发了全球AI社区的广泛关注,被认为是多模态AI发展的重要里程碑。Kimi-Audio-7B-Instruct基于Qwen2.5-7B架构,并结合Whisper技术,展现了强大的多功能性。
Kimi Audio被设计为一个通用的音频基础模型,能够在一个统一的框架内处理各种音频处理任务。主要功能包括:
通用功能:处理各种任务,如语音识别(ASR)、音频问答(AQA)、音频字幕(AAC)、语音情感识别(SER)智谱 AI GLM 教程;、声音事件/场景分类(SEC/ASC)和端到端语音对话。
最先进的性能:在众多音频基准测试中取得SOTA结果(见评估和技术报告)。
大规模预训练:对超过1300万小时的各种音频数据(语音、音乐、声音)和文本数据进行预训练,实现强大的音频推理和语言理解。
新颖的架构:采用混合音频输入(连续声学+离散语义标记)和具有并行头的LLM核心来生成文本和音频标记。
高效推理:基于流匹配的块流式去标记器,用于低延迟音频生成。
开源:我们发布了代码、用于预训练和指令微调的模型检查点,以及一个全面的评估工具包,以促进社区的研究和开发。
模型地址:https://github.com/MoonshotAI/Kimi-Audio
论文地址:https://github.com/MoonshotAI/Kimi-Audio/blob/master/assets/kimia_report.pdf
模型数据:魔搭社区
模型架构:
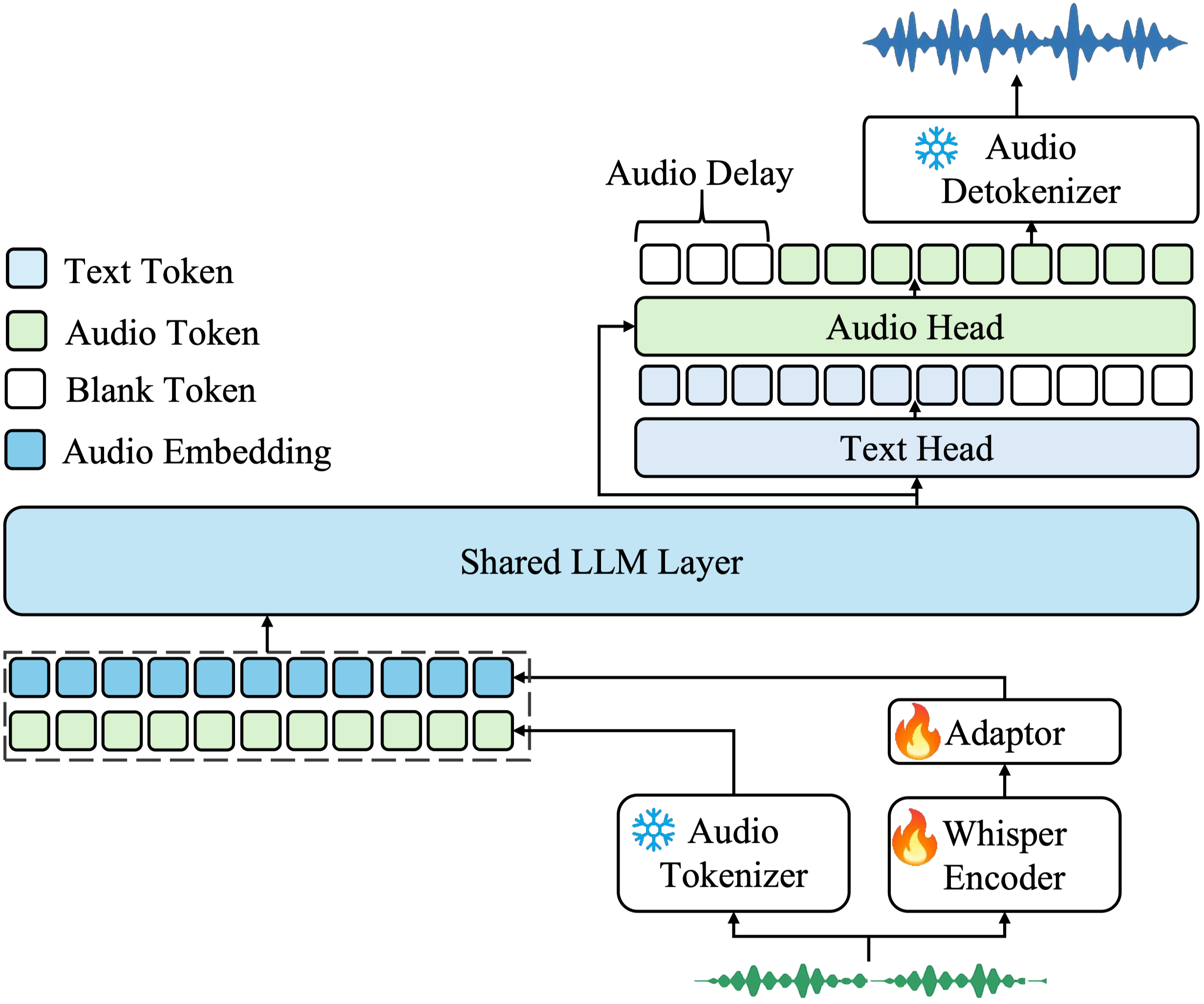
测评结果:
Kimi-Audio与以往音频语言模型在各类基准测试上的表现对比
语音识别方面,LibriSpeech英文测试集,Kimi-Audio的错误率(WER)只有1.28%,比Qwen2.5-Omni的2.37%还低一截。AISHELL-1中文:WER 0.60%,比上一代模型低一半。此外多场景、多语种、多环境,Kimi-Audio基本都是榜首。
音频理解方面,Kimi-Audio在MMAU、MELD、VocalSound、TUT2017等公开集上,分数都是最高。比如MMAU的“声音理解”类,Kimi-Audio得分73.27,超过其它竞品。
音频对话&音频聊天方面,VoiceBench的多项任务,Kimi-Audio都是第一,平均得分76.93。
Kimi-Audio的卓越性能得益于其庞大的训练数据集。据官方披露,该模型在超过1300万小时的多样化音频数据上进行训练,涵盖语音、音乐、环境音等多种类型。Moonshot AI还开源了Kimi-Audio的训练代码、模型权重以及评估工具包。
环境 :ubuntu22.4 系统、内存32G、GPU 32G 英伟达V100、CPU 16核
Python 3.10.12
Pytorch 2.4.1
CUDA 12.1
前置部署请参照
Ubuntu22.4部署及更新cuda11.8与cuda12.1-CSDN博客
1、创建工作空间
2、下载模型

3、下载依赖
下载flash_attn依赖(这一步很重要,要不然代码程序无法执行)
如果一直无法安装,可直接下载安装文件,然后再安装
以上下载地址可参考:Releases · Dao-AILab/flash-attention · GitHub
4、下载模型库
模型库地址:魔搭社区
在/opt/workspace/Kimi-Audio/中创建文件夹moonshotai
定位到目录
执行如下操作

5、下载glm4_tokenizer
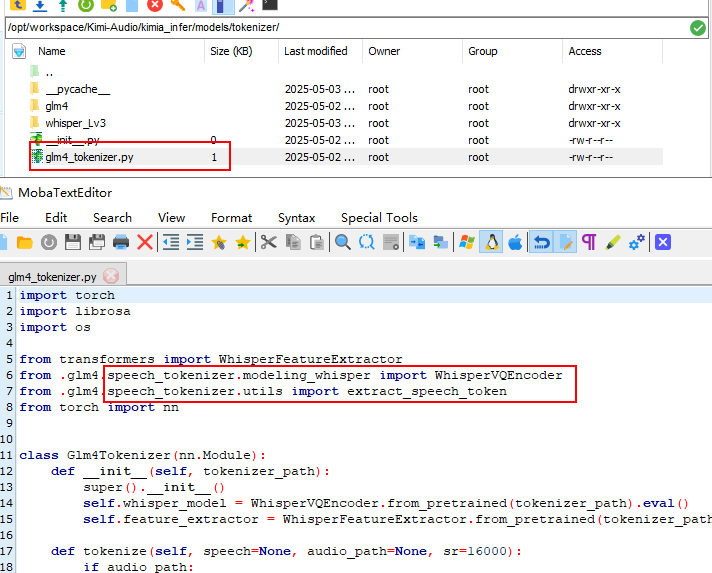
为何要下载gml4,是因为源码中调用,官方代码中没有
查看源码
发现glm4中竟然缺少文件,查看官网发现竟然超链接到GitHub – THUDM/GLM-4-Voice: GLM-4-Voice | 端到端中英语音对话模型
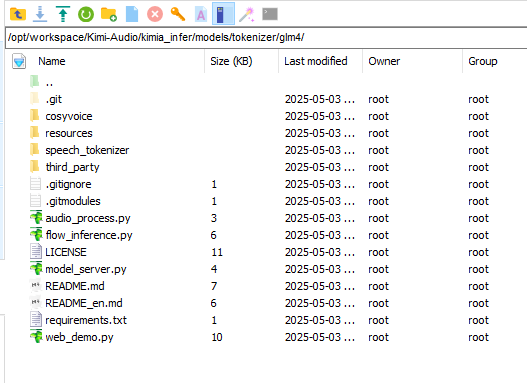
结果如下
6、代码编程修改
将/opt/workspace/Kimi-Audio/infer.py文件中第九行内容moonshotai/Kimi-Audio-7B-Instruct修改为moonshotai/Kimi-Audio-7B
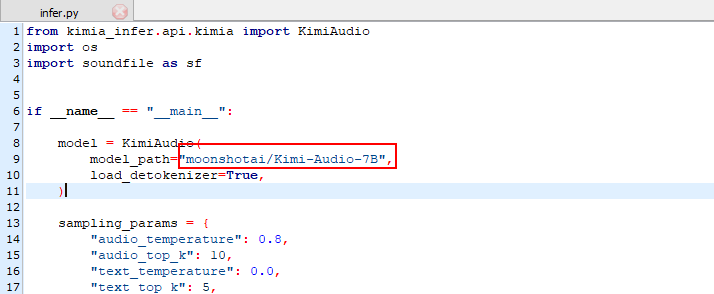
代码如下(已完善注释):
代码展示了如何使用KimiAudio模型进行音频处理任务。我来为您解释一下代码的主要功能:
- 首先导入必要的库:
- KimiAudio:Kimi音频模型的接口
- os:操作系统接口
- soundfile:音频文件读写库
- 主要功能分为两部分:
第一部分 – 语音识别(ASR):
- 加载KimiAudio模型,指定模型路径为”moonshotai/Kimi-Audio-7B-Instruct”
- 设置采样参数,包括音频和文本生成的各种温度、top_k等参数
- 构建消息列表,包含一条文本指令和一条音频输入
- 调用模型生成文本输出(语音转文字)
第二部分 – 音频处理:
- 创建输出目录
- 构建只包含音频输入的消息
- 调用模型同时生成音频和文本输出
- 使用soundfile将生成的音频保存为WAV文件
注意事项:
- 代码中使用了相对路径”test_audios/”下的音频文件,请确保这些文件存在
- 输出音频采样率设为24000Hz
- 模型需要加载detokenizer(load_detokenizer=True)
这个示例展示了KimiAudio模型的两个主要功能:
- 语音识别(将音频转为文字)
- 音频生成/处理(输入音频生成新的音频)
6、代码调试
![]()
![]()
1、代码报错flash_attn未找到
解决方案:检查本地的flash_attn是否与torch版本一致
2、OSError: We couldn’t connect to ‘https://huggingface.co’ to load the files, and couldn’t find them in the cached files. Checkout your internet connection or see how to run the library in offline mode at ‘https://huggingface.co/docs/transformers/installation#offline-mode’
解决方案:上述原因是未找到本地模型地址,重新从远程服务器上获取缓存,而缓存服务器是国外的,检查/opt/workspace/Kimi-Audio/infer.py代码文件中第九行代码中moonshotai/Kimi-Audio-7B路径是否和服务器上一致
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/271290.html原文链接:https://javaforall.net


