
🌞欢迎来到图解强化学习的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
📆首发时间:🌹2026年3月14日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录
强化学习要素
📝走迷宫获取宝藏
💡 总结一下
马尔可夫决策过程
马尔可夫性
全观测/部分可观测
状态转移矩阵
回报 (Return)和价值函数 (Value Function)
贝尔曼方程
矩阵形式的贝尔曼方程
求解贝尔曼方程
马尔可夫决策过程(MDP)
策略
价值


强化学习要素
📝走迷宫获取宝藏
Agent 主角 / 玩家小机器人
Environment 游戏世界 / 规则迷宫地图
State 处境 / 样子坐标 (2,3)
Action 反应 / 动作向上走一步
Reward 评价 / 反馈金币(+10) / 坑(-100)
吃到金币:+10分(开心!)
掉进陷阱:-50分(好疼!)
漫无目的地走:-1分(为了让它快点走,每浪费一秒都要扣微量分)
Policy 脑筋(大脑) / 攻略见金币就上的本能看到的情况(状态 S)应该做的反应(动作 A)
(1)左边有墙,右边是路往右走前面有金币
(2)脚下没陷阱往前冲
(3)三面都是墙,只有后路往后退

💡 总结一下
你可以把强化学习看作是一个不断循环的“互动游戏”:
小机器人(Agent)睁开眼睛,看到了自己当前的处境(State),然后翻开脑子里的通关秘籍
(Policy),决定往右边走一步(Action)。结果这一步刚好踩中了宝藏,迷宫
(Environment)立刻丢给它一个大大的笑脸加分(Reward),并且小机器人来到了一个新的位
置(新 State)。吃到了甜头的小机器人赶紧在秘籍上记下一笔:“在刚才那个处境下,往右走是大
神操作!”(更新策略)
马尔可夫决策过程
马尔可夫性
智能体未来状态的条件概率分布 仅依赖于当前状态

想象机器人来到了 位置,左边死胡同,右边是金币。 无论它是千辛万苦走过来的,还
是原地“空降”的,它面临的局势都一模一样。它只需做一件事:向右走,吃金币。
全观测/部分可观测
前面我们聊的迷宫,其实默认了一个非常理想的设定:小机器人知道自己在哪,也清楚整个迷
宫的构造。但在强化学习的真实世界里,环境给不给你透底,那是两码事!
模式一:“全观测” (Fully Observable)
迷宫开了“全图视野”。小机器人不仅确切知道自己的坐标位置,还清楚金币和陷阱在哪里,所
有死胡同和通道都尽收眼底。观测 (Observation) = 状态 (State)。小机器人拿到的信息就是迷宫
的真实全貌,没有任何秘密。
模式二:“部分可观测” (Partially Observable)
迷宫停电了,小机器人手里只有一把手电筒,只能照亮眼前半米:“前面是墙,左边是路”。至于
自己到底在整个地图的哪里?不知道。观测 ≠ 状态。迷宫的真实全貌(状态)被隐藏了,小机器人
只能拿到有限的局部信息(观测)。

状态转移矩阵
s 是「迷宫坐标 (2,3)」,
s ′ 是「坐标 (2,4)」,
Pss ′ Agent 智能体就代表你站在 (2,3) 时,下一步走到 (2,4) 的概率。
P这是状态转移矩阵,把所有状态之间的转移概率都打包成一张表。比如第1行就是从状态
s1出发,到所有其他状态的概率。

🍃马尔可夫过程(MP)
“我们可以把马尔可夫过程理解为,只要你设定好了这个人的状态空间(他能干啥)和转移概率
(他有多大可能去干啥),这个过程就会源源不断地产生出一本又一本的‘状态序列日记’。
而每一本这样的日记,我们都叫它一条马尔可夫链。”
状态 State
C1:上第一节课(痛苦面具)
C2:上第二节课(昏昏欲睡)
C3:上第三节课(极限拉扯)
Pass:通过考试(上岸!)
Pub:去酒吧(放纵)
FB:刷 Facebook / 刷朋友圈(摸鱼)
Sleep:睡觉(终止态,到了这儿,美好的一天就结束了)

马尔可夫过程(MP):就是从早上醒来到晚上睡觉,一整天串起来的真实状态序列。

马尔可夫奖励过程(MRP)
一个马尔可夫奖励过程是一个马尔可夫链加上奖励
假设你现在的状态 是 “去酒吧 (Pub)”。 你在酒吧待了一小时,下一秒你会去哪?根据我们之前的
状态转移图,有三种可能:
20% 的概率:你会良心发现,回到 C1 上课。如果你去了 C1:环境给你奖励 -2 分(因为第一节课
太痛苦了)。
40% 的概率:你会稍微清醒点,去上 C2。如果你去了 C2:环境给你奖励 -2 分(还是很枯燥)。
40% 的概率:你会彻底放飞,去上 C3。如果你去了 C3:环境给你奖励 -2 分(同理)。


这是折扣因子。意思是未来的奖励在你眼里是会“缩水”的。这一步的奖励值 100%,下一步就只值
50%,再下一步就只值 25%。
回报 (Return)和价值函数 (Value Function)

回报
轨迹:C1 C2 C3 Pass Sleep

价值
计算 C_1状态下的价值(Value),实际上就是在问:“如果一个学生现在处于 C_1 状态,按照图
中的概率‘混’下去,他这辈子平均能赚多少分?”就是把你刚才算出的所有可能轨迹的回报
C_1的价值其实就是未来所有可能收益的“折现平均值”。
(Return)进行加权平均。

那么轨迹1的概率怎么得到呐?
轨迹:C_1 C_2 C_3 Pass Sleep
第一步:从 C_1 走到 C_2 的概率是 0.5。
第二步:从 C_2 走到 C_3 的概率是 0.8。
第三步:从 C_3 走到 Pass 的概率是 0.6。
第四步:从 Pass 走到 Sleep 的概率是 1.0。
这条轨迹发生的总概率:
手动加权一万条轨迹是不现实的,这就需要贝尔曼方程(Bellman Equation)直接求解
奖励函数 (Reward) VS 回报 (Return)
最直观的方法就是把它们看作是“月薪”与“退休金总额”的区别。
奖励函数关注的是当下。当你从一个格子跳到另一个格子时,环境会立刻给你一个反馈。
回报关注的是全局。它是把从这一刻开始,直到游戏结束(比如睡着了 Sleep)所拿到的所有奖励
全部加起来的总分。
奖励 (Reward) 是你每走一步环境给你的“小费”; 回报 (Return) 是你走完一整条路后,手里攥着
的“所有小费的总和(还得考虑通货膨胀)”。
在强化学习里,小机器人的目标不是为了追求某一瞬间的奖励最大,而是为了让这一辈子最终拿到
的“回报”最大!
贝尔曼方程
“一个状态的价值,等于你现在能拿到的奖励,加上你下一步所在状态价值的折现。”


假设折扣因子等于1,C3的价值就等于,C3的奖励值,加上折扣因子(每个状态选择的概率成语*
所选择状态的价值)。
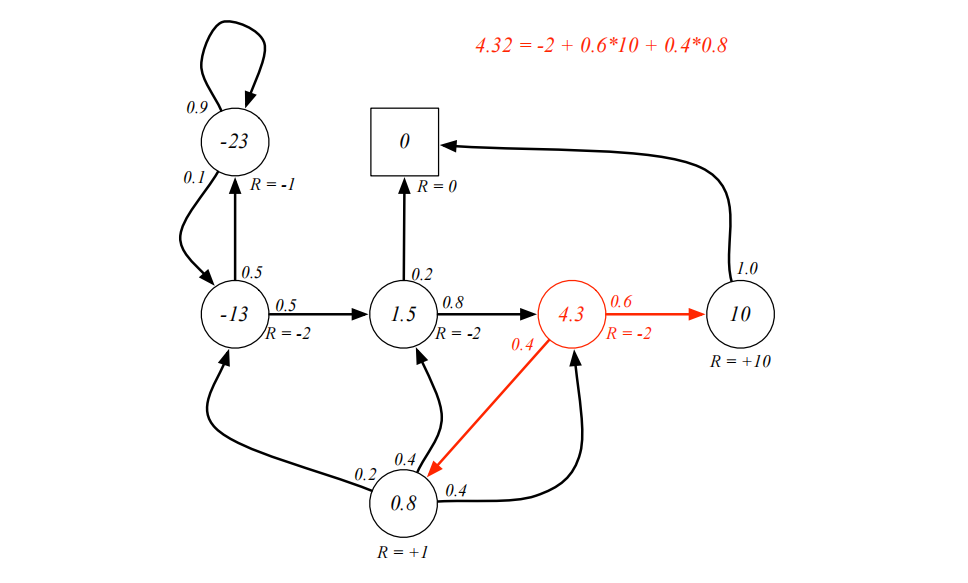
矩阵形式的贝尔曼方程

求解贝尔曼方程
贝尔曼方程是线性方程 ,可以直接求解:

这种方法只适合“小世界”。如果你的迷宫有几百万个格子,算这个矩阵逆的开销会大到让电脑爆
炸。
对于大规模的 MRPs 问题, 可以使用迭代或基于数据的方法,
例如
(1)动态规划
(2)蒙特卡洛估计
(3)时间差分学习
马尔可夫决策过程(MDP)
A 是有限动作集 (Action Space),就是智能体在每个状态下,主观上能做出的选择,在“第一节课
(C1)”这个状态,他的动作集 A 可能是:{认真听讲, 掏出手机, 直接翘课}。
状态转移概率你在状态 s,做出了动作 a,有多大的概率滑到下一个状态 s’。你在 C1,按下了“认
真听讲”这个键。理想情况下,你 100% 会进入 C2(下一节课)。但现实里可能地板太滑,或者老
师讲得太催眠,你可能有 10% 的概率即便想听讲还是睡着了进入了 Sleep 状态。
奖励函数你在状态 s,执行了动作a之后,环境立刻给你的反馈。状态 s = C1,动作 a = “认真听
讲”:老师给你一个赞许的眼神,奖励 +1。
🤖 扫地机器人:
状态空间S(机器人在哪?):这个世界只有 7 个格子。机器人的处境(状态)就是它此时踩在哪
个格子上。
奖励函数 (金币和废纸在哪?)S_1 是充电站(奖励 +1),S_7 是废纸(奖励 +10),其余为
0。
动作空间 A(“手柄怎么操作?”):可以选择“向左”或“向右”。
状态转移概率(理想与现实的打滑”):你的指令(动作a)并不能 100% 决定结果。智能体必须把
“意外”考虑进去。
如果你按了“向右”,因为机器精度(比如地砖太滑):
80% 的概率:成功向右走(执行正确)。
10% 的概率:原地打转(保持不动)。
10% 的概率:居然向左滑了(反方向移动)。
边界处理 (“撞墙了怎么办?”)如果你在 S_1 还要向左,或者在 S_7 还要向右:
90% 的概率:撞墙后停在边界。
10% 的概率:反弹回来。


当你处于迷宫中间(不是两头)时:
0.8 (理想情况):如果你按左 (A_left) 真的到了左边 (s-1),或者按右 (A_right) 真的到了右边
(s+1)。这种情况占 80%,说明机器人大部分时间还是听话的。
0.1 (原地踏步):不管你按左还是按右,机器人纹丝不动 (s’ = s)。占 10%,可能是轮子空转了。
0.1 (反向打滑):最倒霉的情况。按左反而去了右边,按右反而去了左边。占 10%,这地砖真的很
滑!
左边界的“撞墙法则” (s = S_1)
S_1是充电站,也是最左边的墙角。
当你按“向左” (A_left):
0.9 的概率你会撞墙留原地
0.1 的概率你居然反弹回了
当你按“向右”
0.8 的概率正常去 S_2。
0.2 的概率还是没动,留在了 S_1(这对应了规则 4 里的原地不动和规则 5 的边界概率叠加)。
右边界的“捡纸法则” (s = S_7)
S_7 是废纸所在地,也是最右边的墙角。
当你按“向左” (A_left):
0.8 的概率正常回 S_6。
0.2 的概率没动,留在了 S_7。
当你按“向右” (A_right):
0.9 的概率撞墙留原地(留在 S_7)。
0.1 的概率反弹回了 S_6。

策略
概率揉合公式:在策略 下,从 s飞到 s’ 的总概率.
你在 s 选动作 a 的概率
乘上 选了 a 之后滑到 s’ 的物理概率(打滑法则 P)。
把所有可能的动作 a(左、右、停)全部加起来。
奖励揉合公式:
在策略下,站在状态 s的平均工资。把每个动作拿到的即时奖励,按照你选那个动作的概率加权平
均。:如果你 90% 的时间在学习(奖励 -2),10% 的时间在摸鱼(奖励 -1),那你在“学生”这个
状态的平均日薪就是 -2 * 0.9 + (-1) * 0.1 = -1.9。

价值
状态价值函数
它在问:如果你现在处于状态 s,并且一直遵守策略混下去,你这辈子平均能拿多少总分?
假设机器人在 S_6(废纸旁边)。如果它的策略pi是“永远向右”,那么 V_pi(S_6) 就会非常高,因
为它马上就能拿到 +10 分。
动作价值函数
先强行执行动作 a(不管策略pi 怎么说,就先任性这一步),
从下一步开

你现在站在状态 s,然后完全听从你既定的策略(攻略)pi,第一步动作 a_t 是根据策略 pi 随机按
比例选出来的。如果你在 S_4,你的策略是“50%向左,50%向右”。那么在计算 V 的时候,你会模
拟很多次:一半次数往左走,一半次数往右走,最后算出一个平均得分。
你现在站在状态 s,但是你突然想试一试:“如果我现在强行执行动作 a,结果会怎样?”第一步动
作不是“摇骰子”选的,而是指定死必须是 a。但是,从第二步(时刻 t+1)开始,你又变回了那个
听话的好孩子,继续按照策略 pi 走。你还是在 S_4。你想计算 Q(S_4, 向右)。哪怕你的策略 pi 告
诉你应该向左,在这个公式里,你也会强行先往右走一步,看看这一步带来的即时奖励和后续身
价。





发布者:Ai探索者,转载请注明出处:https://javaforall.net/283234.html原文链接:https://javaforall.net


