
python爬虫–异步
基本概念
目的:在爬虫中使用异步实现高性能的数据爬取操作。
异步爬虫的方式:
-
多线程,多进程(不建议) :
- 好处:可以为相关阻塞的操作单独开启线程或者进程,阻塞操作就可以异步执行。
- 弊端:无法无限制的开启多线程或者多进程。
-
线程池、 进程池(适当) :
- 好处:我们可以降低系统对进程或者线程创建和销毁的一个频率,从而很好的降低系统的开销。
- 弊端:池中线程或进程的数量是有上限。
线程池的基本使用
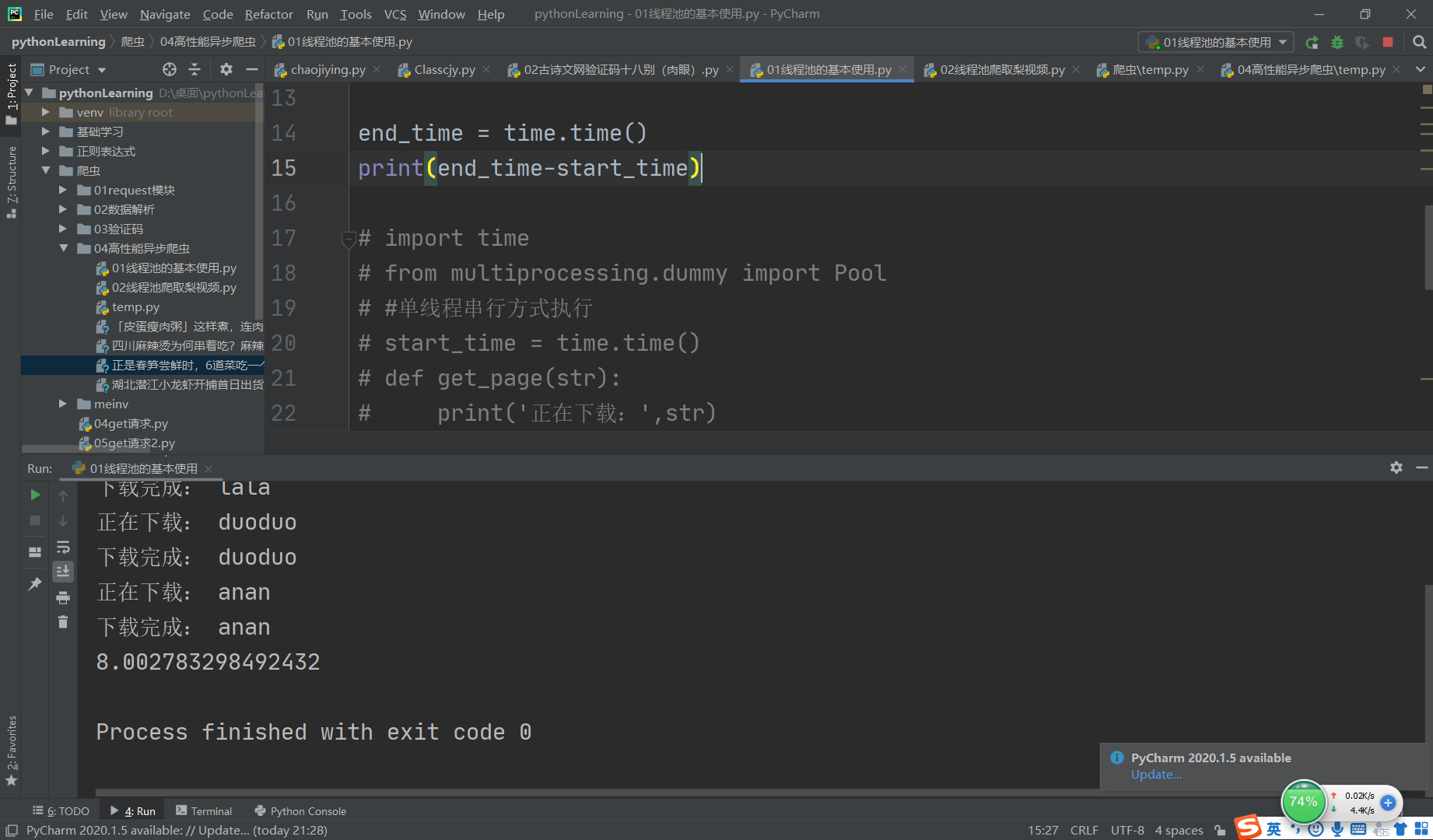
代码粘贴
# import time
# #单线程串行方式执行
# start_time = time.time()
# def get_page(str):
# print('正在下载:',str)
# time.sleep(2)
# print('下载完成:',str)
#
# name_list = ['haha','lala','duoduo','anan']
#
# for i in range(len(name_list)):
# get_page(name_list[i])
#
# end_time = time.time()
# print(end_time-start_time)
import time
from multiprocessing.dummy import Pool
#单线程串行方式执行
start_time = time.time()
def get_page(str):
print('正在下载:',str)
time.sleep(2)
print('下载完成:',str)
name_list = ['haha','lala','duoduo','anan']
pool = Pool(4)
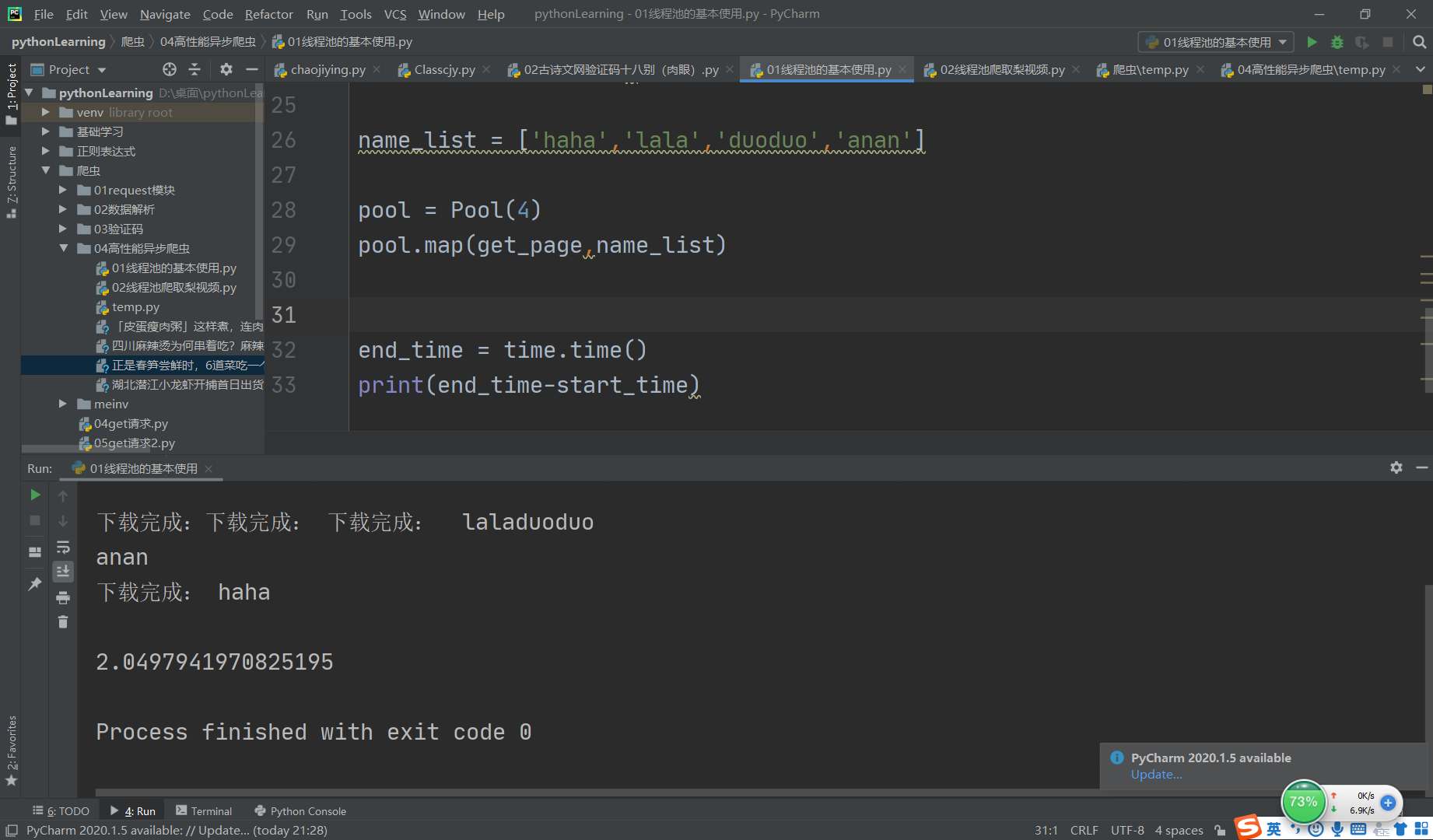
pool.map(get_page,name_list)
end_time = time.time()
print(end_time-start_time)
效果图
单线程串行方式

线程池
https://www.pearvideo.com/category_6
代码粘贴
import requests,re,random
from lxml import etree
from multiprocessing.dummy import Pool
urls = [] #视频地址和视频名称的字典
#获取视频假地址函数
def get_videoadd(detail_url,video_id):
ajks_url = 'https://www.pearvideo.com/videoStatus.jsp'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
'Referer':detail_url
}
params = {
'contId': video_id,
'mrd': str(random.random())
}
video_json = requests.post(headers=header,url=ajks_url,params=params).json()
return video_json['videoInfo']['videos']['srcUrl']
#获取视频数据和持久化存储
def get_videoData(dic):
right_url = dic['url']
print(dic['name'],'start!')
video_data = requests.get(url=right_url,headers=headers).content
with open(dic['name'],'wb') as fp:
fp.write(video_data)
print(dic['name'],'over!')
if __name__ == '__main__':
url = 'https://www.梨video.com/category_6'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="listvideoListUl"]/li')
for li in li_list:
detail_url = 'https://www.pearvideo.com/'+li.xpath('./div/a/@href')[0]
name = li.xpath('./div/a/div[2]/text()')[0]+'.mp4'
#解析视频ID
video_id = detail_url.split('/')[-1].split('_')[-1]
false_url = get_videoadd(detail_url,video_id)
temp = false_url.split('/')[-1].split('-')[0]
#拼接出正确的url
right_url = false_url.replace(temp,'cont-'+str(video_id))
dic = {
'name':name,
'url':right_url
}
urls.append(dic)
#使用线程池
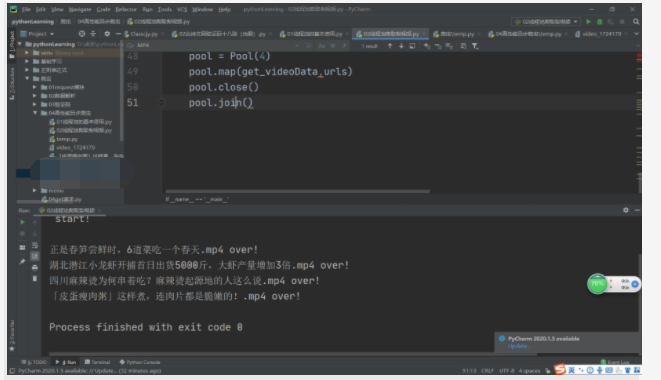
pool = Pool(4)
pool.map(get_videoData,urls)
#子线程结束后关闭
pool.close()
#主线程关闭
pool.join()
效果图
思路
详情页发现ajks请求
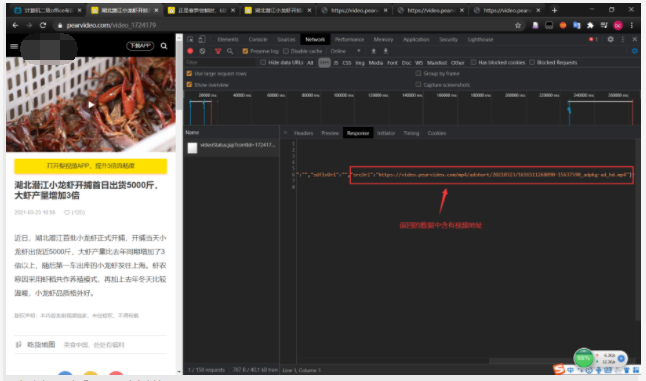
但是,这是假地址
例:
假地址:
真地址
对比之后发现
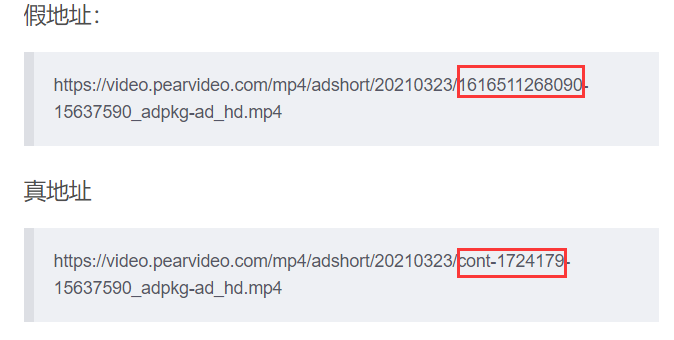
圈中的数字中换为cont-video_id就为真地址
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/100100.html原文链接:https://javaforall.net


