
动机
航空业的庞大规模让人有理由关心它:它不仅直接影响数百万人(传单,飞行员,工程师等),而且数百万人因间接影响其经济实力而间接影响数百万人。
尽管北美航空业强劲,但为了保持持续增长以及作为跨地区行业领导者的持续地位,必须时刻保持警惕,以跟上客户需求。当然,在这方面的成功要求航空公司首先了解客户关心的是什么。发现航空公司客户喜欢和不喜欢他们的飞行体验是该项目的起点。
数据
为了更准确地了解飞机的哪些方面影响了客户的意见, 该网站收集客户编写的几乎每家运营航空公司的航班评论。典型的评论如下:


包含在这个中的变量是:
航空公司:
评论作者给出的整体航空公司评分(满分10分)
作者:评论作者的名字
日期:撰写评论的日期
customer_review:客户评论的文本
飞机:飞机类别/类型(可能性太多,无法列出;例如:波音737)
traveller_type:旅行者类型(商务,情侣休闲,家庭休闲,独奏休闲)
客舱:评论作家飞行的机舱类型(商务舱,经济舱,头等舱,特级经济舱)
航线:航班起点和目的地(例如:芝加哥至波士顿)
问题1
在座位舒适度,座舱服务,食品和饮料,娱乐和地面服务方面,飞行的哪个方面对客户的整体评价影响最大?
这是一个经典的机器学习问题,很容易提出,但难以回答,难点在于预测变量之间潜在的微妙相互作用。
我使用R包“randomForest”中的randomForest()函数,该函数使用非参数Breiman随机森林算法生成回归模型。作为一个侧重点,它可以估计每个预测变量相对于其他预测变量对预测响应变量的重要性。这个输出是我用来确定我的五个变量中哪一个对整个飞行评级最重要的。以下是对我的数据运行时randomForest()函数的变量重要性输出的视觉效果:
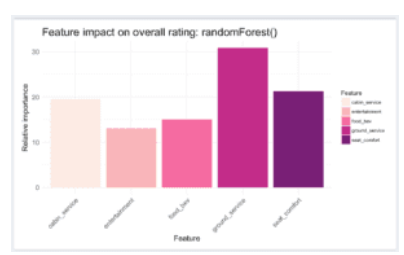
根据Breiman算法,地面服务是预测客户飞行总体评分的最重要变量,其次是座椅舒适度,客舱服务,食品和饮料以及娱乐(按此顺序)。
分析了包含每个变量的评论比例。输入缺失值不可避免地会导致结果偏差,但是消除这些值会为我们带来潜在的宝贵信息。在这种情况下,我相信各方面的失踪倾向于属于“不随意丢失”的范畴,这意味着失踪的原因实际上与所讨论的变量的价值有关; 特别是,我认为,大量缺失的领域对于客户而言可能不那么重要,而缺少缺失的领域则更为重要。为了分析这一点,我绘制了包含每个变量的评论比例:
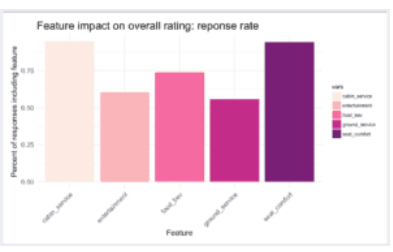
由此我们看到,机舱服务和座椅舒适度几乎包含在每个评论中,而地面服务仅包含在约55%的评论中。
问题2
美国航空公司如何在客户飞行体验的不同方面表现出色?
鉴于我们在问题1中的结果,航空公司现在可能希望将其自身与其他航空公司以及整个行业进行比较,涵盖机舱服务,娱乐,食品和饮料,地面服务和座椅舒适度等变量。为了分析这一点,我对每个航空公司以及整个行业的每个变量给予1,2,3,4,5和NA评级的评论数量进行了统计。对于座椅舒适性评级,我们有以下结果:
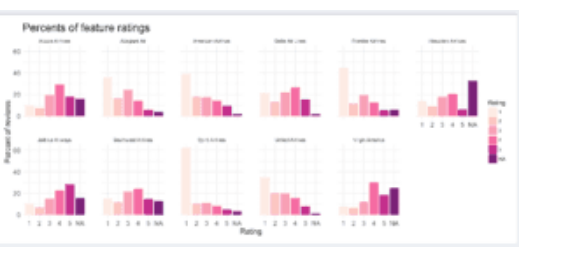
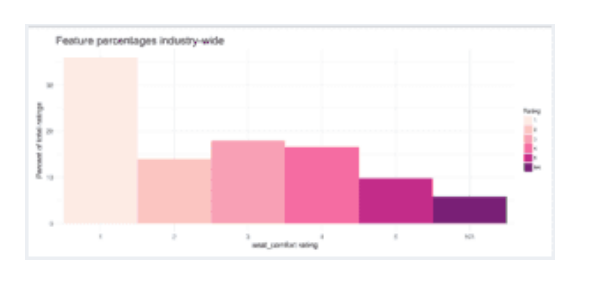
探索了机舱服务,娱乐,食品和饮料,地面服务和座椅舒适性五个变量中的每一个,并且通过所有这些导致以下观察:
捷蓝航空对所有航空公司的座椅舒适度评分最高,因此应推崇自己作为座椅舒适性的行业领导者。同样,阿拉斯加航空公司应该推销自己作为机舱服务的行业领导者。根据问题1的结果,如果客户知道他们在座椅舒适性和客舱服务方面处于领先地位,那么JetBlue和阿拉斯加都可能获得销售增长,因为这些变量是迄今为止研究的五个变量(影响客户对a的总体印象)飞行最多。
Spirit Airlines一直主要收到1份评级,这表明在所有考虑的领域中,客户往往对他们的体验感到不满。然而,Spirit Airlines继续增长。这表明需要更多地探索航空公司客户的需求。
透视:总体而言,美国航空业在机舱服务方面做得最好,在地面服务和座椅舒适度方面表现最差(在这些领域里,比任何其他评级都少了5秒)。另外,娱乐评级也很低。
问题3
正面评论中最常出现的词是什么?负面评论?
之前的问题旨在更好地了解航空公司客户对飞行体验(机舱服务,娱乐,食品和饮料,地面服务,座椅舒适度)五个具体方面的看法,但是由于这五个领域没有考虑到所有可能影响客户整体经验,我想分析他们的评论的实际文字。为此,我使用了由R中的“tm”,“wordcloud”和“memoise”软件包组合生成的词云。我分别分析了单个航空公司和整个行业的正面和负面评论。正面评价总体评分为6/10或更高,负面评价为总评分5/10或更差的评价。
以下是整个行业的正面和负面词云:

在正面和负面评论中,“时间”这个词都是最常用的三个词之一。
尽管如此,“座位”和“服务”这两个字仍然出现在前五个词中,因此对前面问题的分析得到了证实。
精神虽然在问题1和问题2中考虑的五个领域中的几乎每一个领域中都是航空公司中最差的,但它有一个负面词云,与其他负面词云不同。也就是说,Spirit的客户仍然在关于延迟和时间的文本评论中抱怨最多,
透视: 航空公司的客户写的时间比其他任何事都多,其次是服务和座位。鉴于Spirit Airlines的令人惊讶的发现,节省/浪费时间可能是客户整体飞行评级的预测指标。
结论和未来的方向
尽管影响飞行员乘坐飞机体验的因素有很多,但航空公司可以通过关注航班的几个主要方面 – 特别是时间,座位舒适性和机舱服务,来提高客户满意度。
转载于:https://www.cnblogs.com/tecdat/p/11059915.html
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/100853.html原文链接:https://javaforall.net


