
大家好,又见面了,我是全栈君。
利用shared memory计算,并避免bank conflict;通过每个block内部规约,然后再把所有block的计算结果在CPU端累加
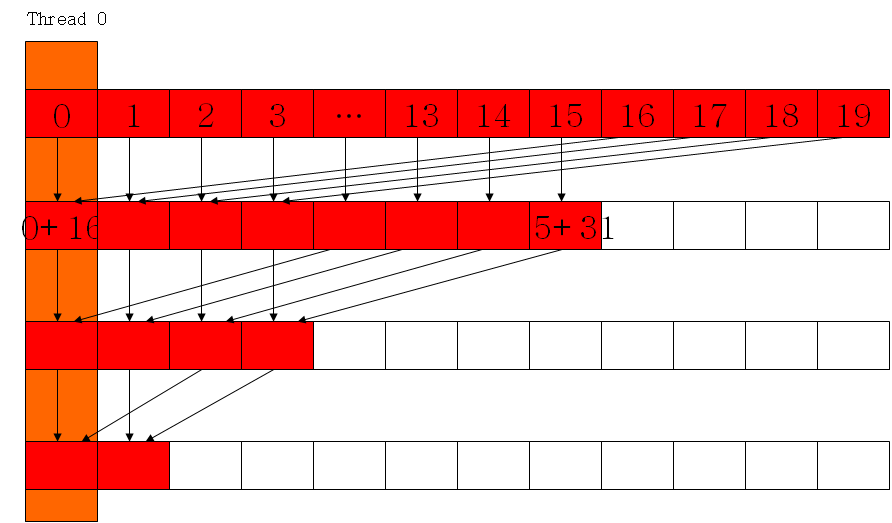

代码:
#include <cuda_runtime.h> #include <device_launch_parameters.h> #include <stdio.h> #include <stdlib.h> #include <memory> #include <iostream> #define DATA_SIZE 128 #define TILE_SIZE 64 __global__ void reductionKernel(float *in, float *out){ int tx = threadIdx.x; int bx = blockIdx.x; __shared__ float data_shm[TILE_SIZE]; data_shm[tx] = in[bx * blockDim.x + tx]; __syncthreads(); for (int i = blockDim.x / 2; i > 0; i >>= 1){ if (tx < i){ data_shm[tx] += data_shm[tx + i]; } __syncthreads(); } if (tx == 0) out[bx] = data_shm[0]; } void reduction(){ int out_size = (DATA_SIZE + TILE_SIZE - 1) / TILE_SIZE; float *in = (float*)malloc(DATA_SIZE * sizeof(float)); float *out = (float*)malloc(out_size*sizeof(float)); for (int i = 0; i < DATA_SIZE; ++i){ in[i] = i; } memset(out, 0, out_size*sizeof(float)); float *d_in, *d_out; cudaMalloc((void**)&d_in, DATA_SIZE * sizeof(float)); cudaMalloc((void**)&d_out, out_size*sizeof(float)); cudaMemcpy(d_in, in, DATA_SIZE * sizeof(float), cudaMemcpyHostToDevice); dim3 block(TILE_SIZE, 1); dim3 grid(out_size, 1); reductionKernel << <grid, block >> >(d_in, d_out); cudaMemcpy(in, d_in, DATA_SIZE * sizeof(float), cudaMemcpyDeviceToHost); cudaMemcpy(out, d_out, out_size * sizeof(float), cudaMemcpyDeviceToHost); float sum = 0; for (int i = 0; i < out_size; ++i){ sum += out[i]; } std::cout << sum << std::endl; // Check on CPU float sum_cpu = 0; for (int i = 0; i < DATA_SIZE; ++i){ sum_cpu += in[i]; } std::cout << sum_cpu << std::endl; }
转载于:https://www.cnblogs.com/haiyang21/p/7795678.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/108053.html原文链接:https://javaforall.net


