
大家好,又见面了,我是你们的朋友全栈君。
此数据是1949 到 1960 一共 12 年,每年 12 个月的航班乘客数据,一共 144 个数据,单位是 1000。我们使用它来进行LSTM时间序列预测的实验。数据如图所示
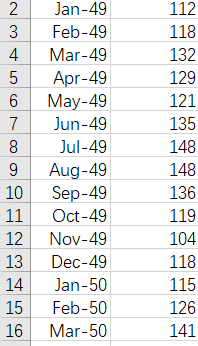

第一列为时间 第二列为数据
编写代码
头文件
import numpy
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
import pandas as pd
import os
from keras.models import Sequential, load_model加载数据
在这里我们设置时序数据的前65%为训练数据 后35%为测试数据
dataframe = pd.read_csv('./international-airline-passengers.csv', usecols=[1], engine='python', skipfooter=3)
dataset = dataframe.values
# 将整型变为float
dataset = dataset.astype('float32')
#归一化 在下一步会讲解
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
train_size = int(len(dataset) * 0.65)
trainlist = dataset[:train_size]
testlist = dataset[train_size:]对数据进行处理
LSTM进行预测需要的是时序数据 根据前timestep步预测后面的数据
假定给一个数据集
{
A,B,C->D
B,C,D->E
C,D,E->F
D,E,F->G
E,F,G->H
}
这时timestep为3,即根据前三个的数据预测后一个数据的值
所以我们需要对数据进行转化
举一个简单的情况 假设一个list为[1,2,3,4,5],timestep = 2
我们转化之后要达到的效果是
| train_X | train_Y |
|---|
即依据前两个值预测下一个值
对数据进行归一化
LSTM可以不进行归一化的操作,但是这样会让训练模型的loss下降很慢。本教程如果不进行归一化,100次迭代后loss还是很高
#上面代码的片段讲解
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)对数据进行处理
def create_dataset(dataset, look_back):
#这里的look_back与timestep相同
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back)]
dataX.append(a)
dataY.append(dataset[i + look_back])
return numpy.array(dataX),numpy.array(dataY)
#训练数据太少 look_back并不能过大
look_back = 1
trainX,trainY = create_dataset(trainlist,look_back)
testX,testY = create_dataset(testlist,look_back)LSTM模型
LSTM的输入为 [samples, timesteps, features]
这里的timesteps为步数,features为维度 这里我们的数据是1维的
trainX = numpy.reshape(trainX, (trainX.shape[0], trainX.shape[1], 1))
testX = numpy.reshape(testX, (testX.shape[0], testX.shape[1] ,1 ))
# create and fit the LSTM network
model = Sequential()
model.add(LSTM(4, input_shape=(None,1)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
model.save(os.path.join("DATA","Test" + ".h5"))
# make predictions进行预测
#model = load_model(os.path.join("DATA","Test" + ".h5"))
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
#反归一化
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform(trainY)
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform(testY)查看结果
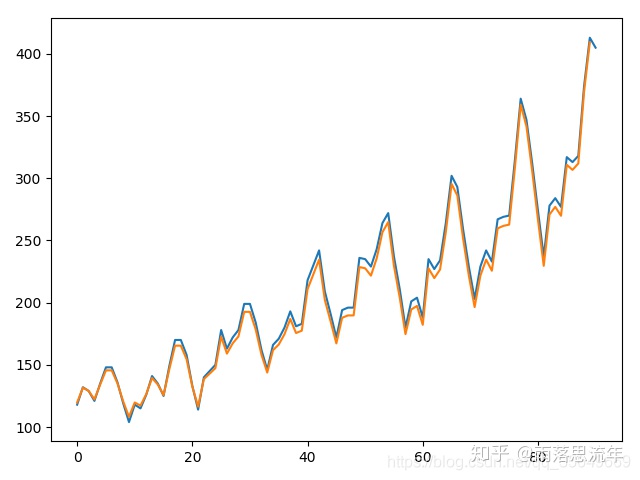
plt.plot(trainY)
plt.plot(trainPredict[1:])
plt.show()
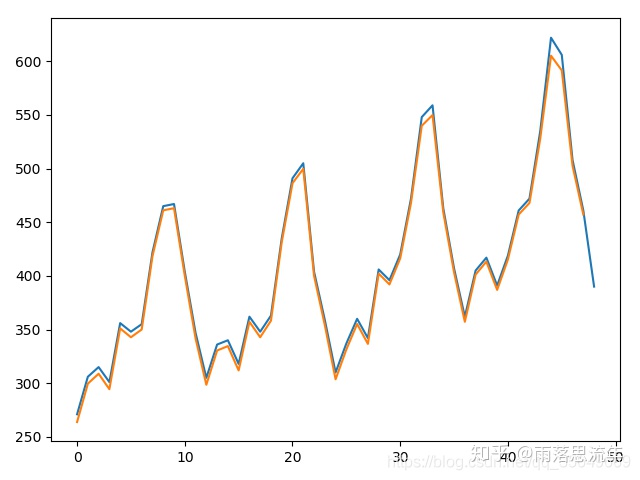
plt.plot(testY)
plt.plot(testPredict[1:])
plt.show()这个时候我们的结果为
参考
用 LSTM 做时间序列预测的一个小例子
Keras中文文档-Sequential model
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/126935.html原文链接:https://javaforall.net


