
大家好,又见面了,我是你们的朋友全栈君。
RNN
递归神经网络(RNN)相对于MLP和CNN的主要优点是,它能够处理序列数据,在传统神经网络或卷积神经网络中,样本(sample)输入与输出是没有“顺序”概念的,可以理解为,如果把输入序列和输出序列重新排布,对整体模型的理论性能不会有影响。RNN则不同,它保证了输入和输出至少有一端是有序列特征的。
传统的神经网络结构可以归纳会下图左边的形式,隐藏层h的状态是不保存的,而在RNN中,每一个时间步的隐藏层状态都是由上一层的输入和上一个时间的状态共同计算得到。
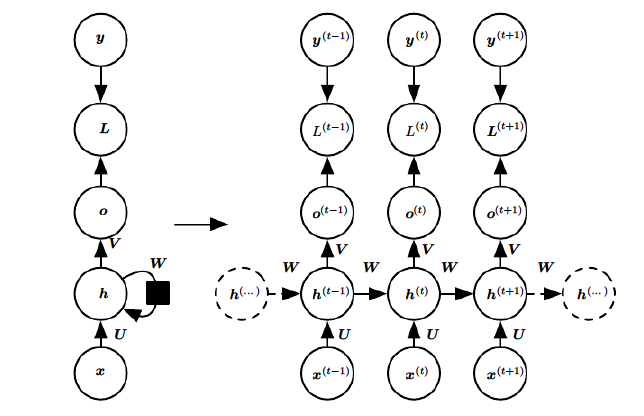

RNN算法的细节这里就不赘述,RNN的缺点在于,误差反向传播时,由于时间步t的梯度是由t时的状态h分别对前面所有时间步的状态求导,再相乘得到,在状态权重的模大于1时,若时间步t较长,梯度就会消失(趋近于0),即长期的依赖很小,相反,在状态权重的模小于1时,若时间步t较短,梯度就会爆炸(很大),即短期的依赖很大。具体分析请[参考文献]。(http://ARXIV.org/pdf/1211.5063.pdf),解决这一问题有两个主要的方法:
- 截断的时间反向传播法(TBPTT):将梯度限制在某个范围,这种做法简单粗暴,却能解决梯度爆炸和消失的问题,但是限制了梯度的传播;
- 长短期记忆(LSTM)
LSTM
LSTM最先是被引入来解决梯度小时问题,LSTM在神经网络中是一个特殊的隐藏层,他将时间步t的隐藏层状态更新结构表示如下:
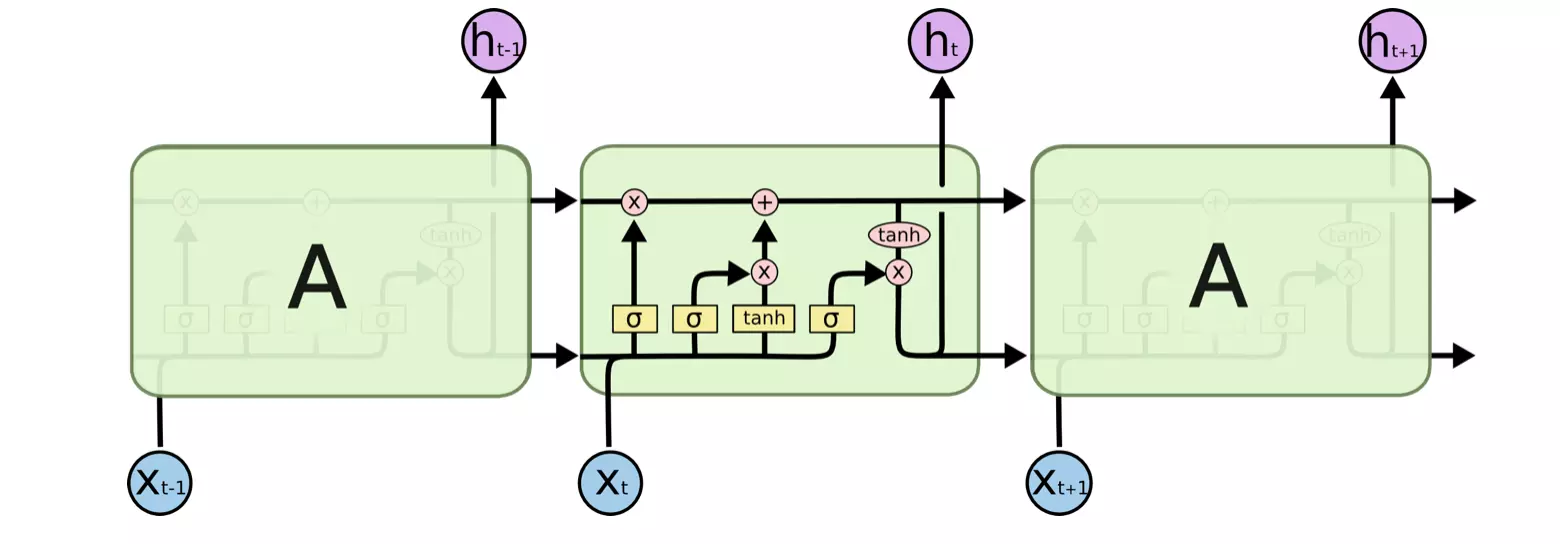
图来源以及LSTM的原理介绍可以参考
LSTM由三个门来控制细胞状态,这三个门分别称为遗忘门、输入门和输出门。
- 遗忘门:允许记忆单元在有限增长的情况下重置信元状态。遗忘门类似于一个过滤器,决定上一个时间步的信元状态C能否通过
- 输入门:负责根据输入值和遗忘门的输出,来更新信元状态C
- 输出们:更新隐藏单元的值
当然,LSTM的形式也是存在很多变式的,不同的变式在大部分任务上效果都差不多,在一些特殊任务上,一些变式要优于标准的LSTM
利用LSTM进行时间序列预测
一般在时间序列预测上,常用的方法主要有ARIMA之类的统计分析,机器学习中经典的回归分析等
- 统计分析中(如ARIMA),将时间序列分为三个部分:趋势,季节性和波动,通过统计学算法将序列分离,得到每个部分的模型再相加,但是模型对于序列的方差、均值平稳性以及自相关性都有很高的要求,否则模型偏差会很大。
- 回归分析注重模型偏差和方差,对特征的要求也很高,回归分析中处理非线性问题是一个很艰难的过程。
这里采用LSTM来进行时间序列预测,结构为:
训练数据生成—>隐藏输入层—>LSTM神经层—>隐藏输出层(全连接层)—>结果
当然,也可以根据任务增加隐藏层,LSTM层以及全连接层的数量。
tensorflow中已经为我们准备好了LSTM层的接口,根据需要配置即可。
这里列举几个重要的注意点:
- 首先要理解什么是序列和序列化数据,比如如果我要预测24小时的天气,那将会有很多种方案,每种方案的序列化都不一样,若模型输出就是24小时的序列,那么输入序列可以是 t-1之前任意长度的序列,输出序列是t > t+23;也可以输入序列为t-24之前的序列来预测t时候的值,进行24次预测;也可以用t-1之前的序列要预测t时,每次预测结果再代入输入中预测t时刻之后的值。总之,每种做法效果不一样,具体问题还需要具体分析;
- TIME_STEPS参数,可以理解为时间步,就是你需要几个时刻的样本来预测,INPUT_SIZE 为每个样本的维度,如果你的样本数据是一个单一序列,没有其他特征的话,则可设置为1;OUTPUT_SIZE 为输出的维度,就是输出序列的长度;如果输出也是一个序列的话,可以将y的维度设置为[None,TIME_STEPS,OUTPUT_SIZE]
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inline
#------------------------------------Generate Data-----------------------------------------------#
TIME_STEPS = 20
BATCH_SIZE = 1
INPUT_SIZE = 1
OUTPUT_SIZE = 1
CELL_SIZE = 50
LEARNING_RATE = 0.001
EPOCH = 100
LAYER_NUM =3
# 参数说明:TIME_STEPS:输入序列的时间步,;
# INPUT_SIZE:输入序列中每个向量的维度
# BATCH_SIZE:训练的批次
# OUTPUT_SIZE:输出序列的向量维度
# CELL_SIZE:LSTM神经层的细胞数,也是LSTM层的输入和输出维度(这两个维度相同),也即为LSTMCell中的num_units参数;
# LEARNING_RATE:tensorflow中optimizer的学习率;
# EPOCH:迭代次数或训练次数;;
# LAYER_NUM:LSTM神经层的层数。
#
#生成训练数据和测试数据
def generate(seq,time_step,output_size):
X = []
Y = []
for i in range(len(seq)-time_step-output_size):
X.append(seq[i:i+time_step])
Y.append(seq[i+time_step:i+time_step+output_size])
return np.array(X,dtype =np.float32),np.array(Y,dtype = np.float32)
seq = np.sin(np.linspace(0,100,10000,dtype=np.float32)/np.pi)
# seq_y = data_day.values.reshape([-1])
X_train,y_train = generate(seq,TIME_STEPS,OUTPUT_SIZE)
X_test, y_test = generate(seq[:-24*7],TIME_STEPS,OUTPUT_SIZE)
X_train = np.reshape(X_train,newshape=(-1,TIME_STEPS,INPUT_SIZE))
X_test = np.reshape(X_test,newshape=(-1,TIME_STEPS,INPUT_SIZE))
y_train = np.reshape(y_train,newshape=(-1,OUTPUT_SIZE))
y_test = np.reshape(y_test,newshape=(-1,OUTPUT_SIZE))
TRAIN_EXAMPLES = X_train.shape[0]
TEST_EXAMPLES = X_test.shape[0]
def tf_init_state(batch_size,cells):
if isinstance(cells,list):
states = []
for cell in cells:
c_size = cell.state_size.c
h_size = cell.state_size.h
c = tf.Variable(np.zeros([batch_size,c_size],dtype=np.float32),dtype=tf.float32)
h = tf.Variable(np.zeros([batch_size,c_size],dtype=np.float32),dtype=tf.float32)
states.append(tf.nn.rnn_cell.LSTMStateTuple(c=c,h=h))
return tuple(states)
else:
c_size = cells.state_size.c
h_size = cells.state_size.h
c = tf.get_variable('{}/c'.format(cells.name),[batch_size,c_size],dtype=tf.float32,initializer=tf.zeros_initializer(tf.float32))
h = tf.get_variable('{}/h'.format(cells.name),[batch_size,h_size],dtype=tf.float32,initializer=tf.zeros_initializer(tf.float32))
return tf.nn.rnn_cell.LSTMStateTuple(c=c,h=h)
def get_states(statetuple,batch_pre):
if isinstance(statetuple,tuple):
newstate = []
for state in list(statetuple):
c = state[0][:batch_pre,:]
h = state[1][:batch_pre,:]
newstate.append(tf.nn.rnn_cell.LSTMStateTuple(c=c,h=h))
return tuple(newstate)
else:
c = statetuple[0]
h = statetuple[1]
return tf.nn.rnn_cell.LSTMStateTuple(c=c[:batch_pre,:],h=h[:batch_pre,:])
#------定义权重和偏差生成函数
def weight_variable(shape, name='weights'):
initializer = tf.random_normal_initializer(mean=0., stddev=1.,)
return tf.get_variable(name=name, shape=shape, initializer=initializer)
def bias_variable(shape, name='biases'):
initializer = tf.constant_initializer(0.1)
return tf.get_variable(name=name, shape=shape, initializer=initializer)
#定义计算图---------------------------------------------------#
graph = tf.Graph()
with graph.as_default():
with tf.name_scope('inputs'):
x_p = tf.placeholder(dtype=tf.float32,shape=(None,TIME_STEPS,INPUT_SIZE),name='xs')
y_p = tf.placeholder(dtype=tf.float32,shape=(None,OUTPUT_SIZE),name = 'ys')
cell_batch = tf.placeholder(dtype=tf.float32,shape =None,name='batch_size')
#定义输入隐藏层,x_p维度(batch_size,time_steps,input_size),l_in_x维度(batch_size*time_steps,input_size),l_in_y维度(batch_size*time_steps,cell_size)
with tf.variable_scope('in_hidden'):
l_in_x = tf.reshape(x_p,[-1,INPUT_SIZE])
ws_in = weight_variable([INPUT_SIZE,CELL_SIZE],'ws_in')
bs_in = bias_variable([CELL_SIZE,],'bs_in')
l_in_y = tf.matmul(l_in_x,ws_in) + bs_in
#定义lstm神经层,l_cell_x维度(batch_size,time_steps,cell_size),l_cell_y维度(batch_size,time——steps,cell_size)
#-----单层lstm神经层
# lstm_cell = tf.nn.rnn_cell.LSTMCell(num_units=HIDDEN_UNITS)
# lstm_model = lstm_cell
#-----dynamic rnn
# outputs,states=tf.nn.dynamic_rnn(cell=lstm_cell,inputs=x_p,initial_state=init_state,dtype=tf.float32)
# h=outputs[:,-1,:]
# lstm_cell1 = rnn.BasicLSTMCell(num_units=HIDDEN_UNITS)
#-----多层lstm神经层
with tf.variable_scope('Lstm_cell_train'):
l_cell_x= tf.reshape(l_in_y,[-1,TIME_STEPS,CELL_SIZE])
lstm_cell = [tf.nn.rnn_cell.BasicLSTMCell(num_units=CELL_SIZE,state_is_tuple=True) for _ in range(LAYER_NUM)]
lstm_model = tf.contrib.rnn.MultiRNNCell(cells=lstm_cell)
init_state = lstm_model.zero_state(batch_size=BATCH_SIZE,dtype=tf.float32)
l_cell_y,cell_states=tf.nn.dynamic_rnn(cell=lstm_model,inputs=l_cell_x,initial_state=init_state,dtype=tf.float32)
#------这里可以直接用输出状态叠加一个全连接层得到最终结果,全连接层可以用函数定义或者手写
# dnn_out=dnn_stack(outputs[:,-1,:],layers={'layers':[32,16]})
#定义输出隐藏层,这里为手写单层神经层,l_out_x的维度(batch_size,cell_size),l_out_y的维度为(batch_size,ouputsize)
with tf.variable_scope('out_hidden'):
l_out_x = tf.reshape(l_cell_y[:,-1,:],[-1,CELL_SIZE])
ws_out = weight_variable([CELL_SIZE,OUTPUT_SIZE],'ws_out')
bs_out = bias_variable([OUTPUT_SIZE,],'bs_out')
l_out_y = tf.matmul(l_out_x,ws_out) + bs_out
#定义损失函数和优化器,损失函数采用MSE(mean-squared error),优化器有多种选择,基础优化器梯度下降法(GradientDescentOptimizer)
#---------------------------------------------------------------------这里采用的是adam算法(AdamOptimizer),优化器一般在tf.train包中
# def ms_error(labels, logits):
# return tf.square(tf.subtract(labels, logits))
with tf.name_scope('loss_funtion'):
mse = tf.losses.mean_squared_error(labels = y_p,predictions = l_out_y)
# losses = tf.contrib.legacy_seq2seq.sequence_loss_by_example(logits=[tf.reshape(l_out_y,[-1],name='reshaped_pred')],
# targets=[tf.reshape(y_p,[-1],name='reshaped_target')],
# weights = [tf.ones([BATCH_SIZE*TIME_STEPS],dtype=tf.float32)],
# softmax_loss_function=ms_error)
# mse = tf.div(tf.reduce_sum(losses, name='losses_sum'),BATCH_SIZE,name='average_cost')
with tf.name_scope('train'):
optimizer = tf.train.AdamOptimizer(LEARNING_RATE).minimize(loss = mse)
#变量初始化
init = tf.global_variables_initializer()
#计算图对话-----session
# with tf.Session(graph=graph) as sess:
sess = tf.Session(graph = graph)
sess.run(init)
#训练过程
for epoch in range(1,EPOCH+1):
train_losses = []
for j in range(TRAIN_EXAMPLES//BATCH_SIZE):
if epoch==1 and j==0:
feed_dict = {
x_p:X_train[j*BATCH_SIZE:(j+1)*BATCH_SIZE],
y_p:y_train[j*BATCH_SIZE:(j+1)*BATCH_SIZE],
}
else:
feed_dict = {
x_p:X_train[j*BATCH_SIZE:(j+1)*BATCH_SIZE],
y_p:y_train[j*BATCH_SIZE:(j+1)*BATCH_SIZE],
init_state:final_states
}
_,train_loss,final_states = sess.run(
fetches =(optimizer,mse,cell_states),feed_dict = feed_dict)
train_losses.append(train_loss)
if epoch%10 ==0:
print('epoch:',epoch)
print('average training loss:',sum(train_losses)/len(train_losses))
#预测过程
if X_test.shape[0]>=TIME_STEPS:
results = np.zeros(shape=(TEST_EXAMPLES,OUTPUT_SIZE))
test_losses = []
for j in range(TEST_EXAMPLES//BATCH_SIZE):
result,test_loss,wsin,bsin,wsout,bsout=sess.run(
fetches =(l_out_y,mse,ws_in,bs_in,ws_out,bs_out),feed_dict ={
x_p:X_test[j*BATCH_SIZE:(j+1)*BATCH_SIZE],
y_p:y_test[j*BATCH_SIZE:(j+1)*BATCH_SIZE],
init_state:final_states
} )
results[j*BATCH_SIZE:(j+1)*BATCH_SIZE,:]=result
test_losses.append(test_loss)
print('average testing loss:',sum(test_losses)/len(test_losses))
#绘制图形
plt.figure(facecolor ='white',figsize=(20,12))
plt.plot(range(j*BATCH_SIZE),y_test[:j*BATCH_SIZE],'r-',range(j*BATCH_SIZE),results[:j*BATCH_SIZE,:])
plt.show()
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/127339.html原文链接:https://javaforall.net


