
大家好,又见面了,我是你们的朋友全栈君。
前面利用了softmax来对图像进行分类,也可以使用多层感知机的方法对图像进行分类。
多层感知机从零开始实现方法
多层感知机(
multilayer perceptron
,
MLP),在单层神经网络的基础上引入了一到多个隐藏层(hidden layer)。
multilayer perceptron
,
MLP),在单层神经网络的基础上引入了一到多个隐藏层(hidden layer)。
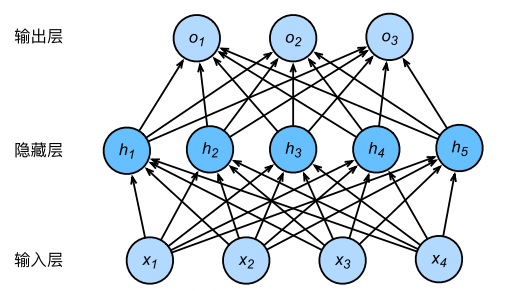

对于图中的感知机来说,
它含有一个隐藏层,该层中有
5个隐藏单元。输入和输出个数分别为
4
和
3
,中间的隐藏层中包含了
5个隐藏单元。由于输入层不涉及计算,图
中的多层感知机的层数为
2
。
它含有一个隐藏层,该层中有
5个隐藏单元。输入和输出个数分别为
4
和
3
,中间的隐藏层中包含了
5个隐藏单元。由于输入层不涉及计算,图
中的多层感知机的层数为
2
。
隐藏层位于输入层和输出层之间。
隐藏层中
的神经元和输入层中各个输入完全连接,输出层中的神经元和隐藏层中的各个神经元也完全连接。因
此,多层感知机中的隐藏层和输出层都是全连接层。
隐藏层中
的神经元和输入层中各个输入完全连接,输出层中的神经元和隐藏层中的各个神经元也完全连接。因
此,多层感知机中的隐藏层和输出层都是全连接层。
1.导入包
import torch
import numpy as np
import sys
sys.path.append("..") # 为了导入上层目录的d2lzh_pytorch
import d2lzh_pytorch as d2l
print(torch.__version__)2.获取和读取数据
使用
Fashion-MNIST
数据集。我们将使用多层感知机对图像进行分类。
Fashion-MNIST
数据集。我们将使用多层感知机对图像进行分类。
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)3.定义模型参数
Fashion-MNIST
数据集中图像形状为 28×28,类别数为10
。本节中我们依然使用长度为 28×28=784的向量表示每一张图像。因此,输入个数为784
,输出个数为
10
。实验中,我们设超参数隐藏单元个数为
256
。
数据集中图像形状为 28×28,类别数为10
。本节中我们依然使用长度为 28×28=784的向量表示每一张图像。因此,输入个数为784
,输出个数为
10
。实验中,我们设超参数隐藏单元个数为
256
。
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = torch.tensor(np.random.normal(0, 0.01, (num_inputs, num_hiddens)), dtype=torch.float)
b1 = torch.zeros(num_hiddens, dtype=torch.float)
W2 = torch.tensor(np.random.normal(0, 0.01, (num_hiddens, num_outputs)), dtype=torch.float)
b2 = torch.zeros(num_outputs, dtype=torch.float)
params = [W1, b1, W2, b2]
for param in params:
param.requires_grad_(requires_grad=True)4.定义激活函数
使用基础的
max
函数来实现
ReLU
,而非直接调用
relu
函数。
max
函数来实现
ReLU
,而非直接调用
relu
函数。
def relu(X):
return torch.max(input=X, other=torch.tensor(0.0))5.定义模型
通过
view
函数将每张原始图像改成长度为
num_inputs
的向量。然后我们实现上一节中多层感知机的计算表达式。
view
函数将每张原始图像改成长度为
num_inputs
的向量。然后我们实现上一节中多层感知机的计算表达式。
def net(X):
X = X.view((-1, num_inputs))
H = relu(torch.matmul(X, W1) + b1)
return torch.matmul(H, W2) + b26.定义损失函数
直接使用
PyTorch
提供的包括
softmax运算和交叉熵损失计算的函数。
PyTorch
提供的包括
softmax运算和交叉熵损失计算的函数。
loss = torch.nn.CrossEntropyLoss()7.训练模型
num_epochs, lr = 5, 100.0
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params, lr)
简洁实现的方法:
1.定义模型
num_inputs, num_outputs, num_hiddens = 784, 10, 256
net = nn.Sequential(
d2l.FlattenLayer(),
nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.Linear(num_hiddens, num_outputs),
)
for params in net.parameters():
init.normal_(params, mean=0, std=0.01)2.读取数据并训练模型
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.5)
num_epochs = 5
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, None, None, optimizer)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/128148.html原文链接:https://javaforall.net


