
大家好,又见面了,我是你们的朋友全栈君。
软件安装与路径添加
在涉及到物种或基因组间差异分析的方法中,LEfSe是目前常见的方法。LEfSe实现的方式主要有在线分析和本地分析,在线分析会受到网络及其他因素影响,因而速度可能极慢。本地分析可基于Windows或Linux系统,调参更加灵活。本文以Windows系统为例,向大家展示如何在自己的本本上运行LEfSe,再也不用去求公司了……
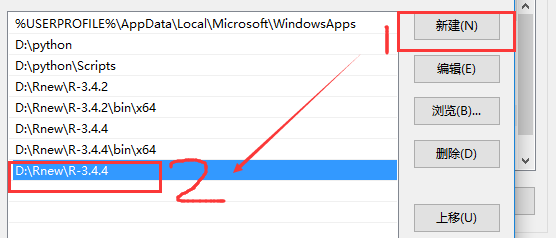
首先,我们要安装好Pyhthon(2.7版本)和R(安装方法不再赘述),然后把软件的安装路径添加到电脑的系统环境变量,如R我是安装在“D:\Rnew\R-3.4.4”,那么我复制这个路径,如下图:

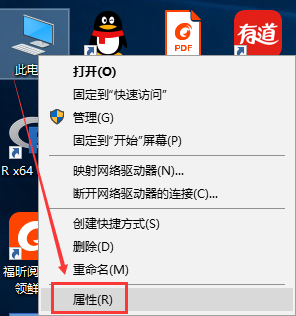
然后鼠标右击“我的电脑”→“属性”
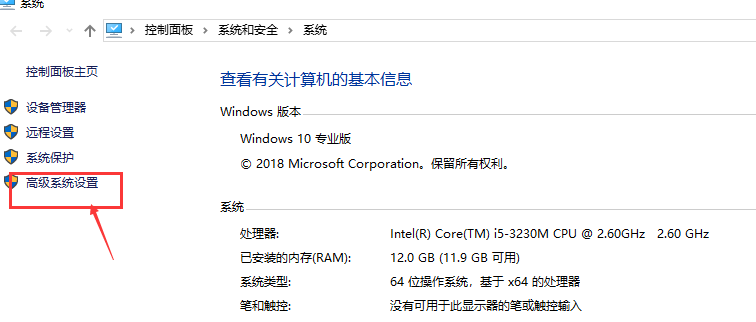
接下来是“高级系统设置”
接下来是双击“环境变量”
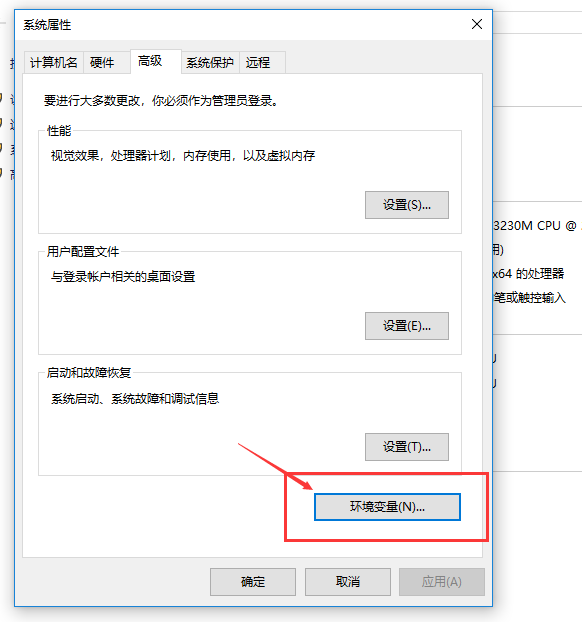
然后双击“环境变量”,我们会看到两个“Path”。
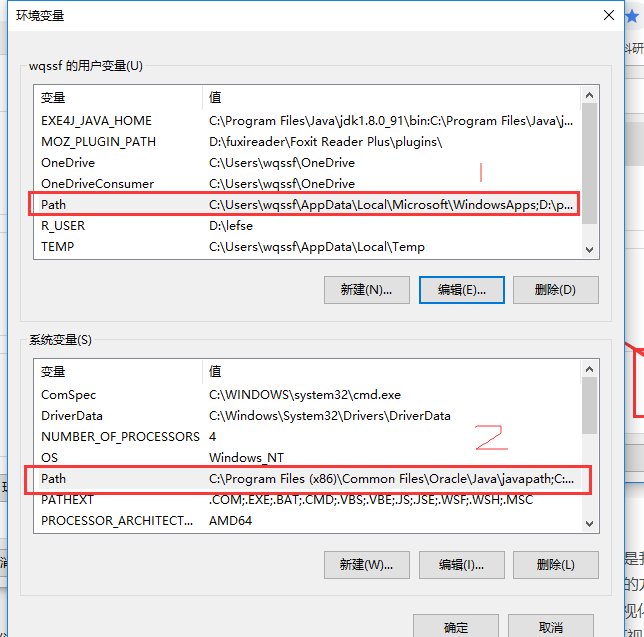
为保证不出意外,我们分别对两个Path进行操作。以上面窗口的Path为例,双击Path,然后“新建”(我的系统为win10,win10以下的系统貌似是直接双击Path就可以操作),然后把R的安装路径粘贴在新建的框内,然后确定,细心的朋友会发现我还把路径“D:\Rnew\R-3.4.4\bin\x64”加入了“环境变量”,是的,我们需要把这两个路径都加入进来。
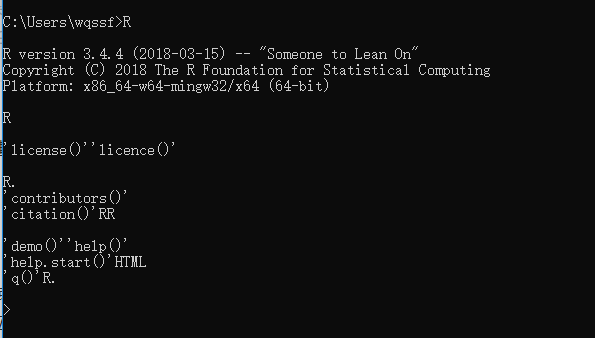
我们检测一下,看R是否成功加入到Path中,我们打开CMD命令行模式,然后输入R→回车键。如下图,说明我们的操作已经成功。
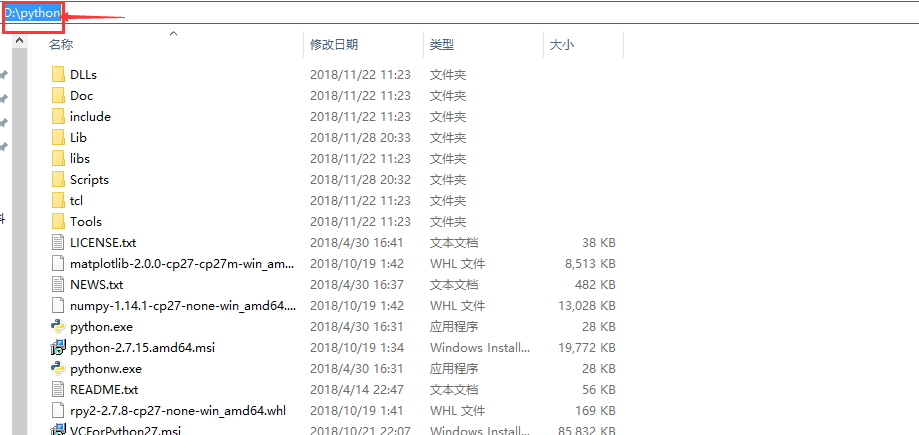
接下来是把Python也加进来,操作方法与R一样,
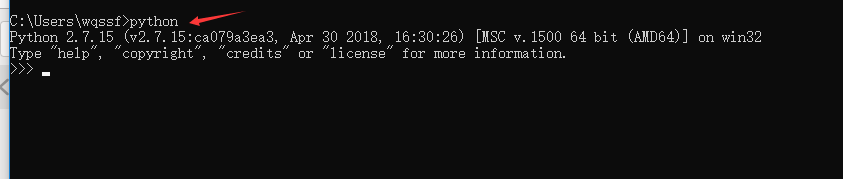
同样的,这里在CMD命令行中输入“python”,然后回车键。如下图,说明python添加到Path成功。
模块与包的安装
上述的操作后,我们已经把Python和R成功加入到Path中,在用这两个做数据分析时,我们要安装别人已经写好的模块与包(packages)。LEfSe主要以Python运行为主,但要调用到R的几个packages。首先,对于python,我们需要安装“numpy”、“rpy2”与“matplotlib”三个模块,在R中需要安装好几个packages,如mvtnorm、coin等。我们先安装Python的模块,在数据分析过程中提示未找到“packages”时,我们再用R安装对应的packages。下面以numpy模块安装为例:在CMD命令行中运行:
pip install D:\python\numpy-1.14.1-cp27-none-win_amd64.whl
等待安装完毕,这里可以分别打开3个CMD,分别安装“numpy”、“rpy2”与“matplotlib”(对于模块的安装,我这里是把模块下载到电脑上,也可以联网安装,农村不仅路滑,网也不好,所以下载→本地安装)。

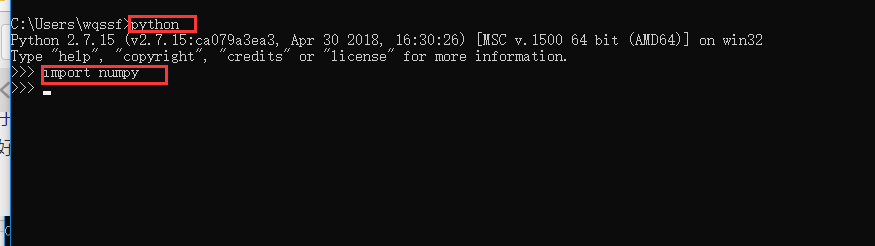
模块安装好后,我们在CMD命令行中输入python,然后回车键,然后输入:
import numpy
回车键。如下图,说明numpy被成功安装,切记还有rpy2与matplotlib也要安装!
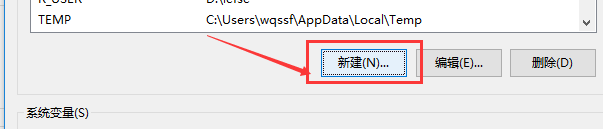
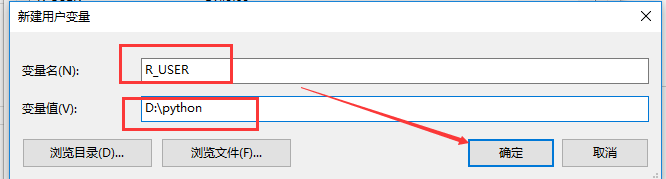
这一步非常重要,我们打开系统环境变量,然后”新建”,变量名为“R_USER”,变量值为某一个路径即可,然后“确定”
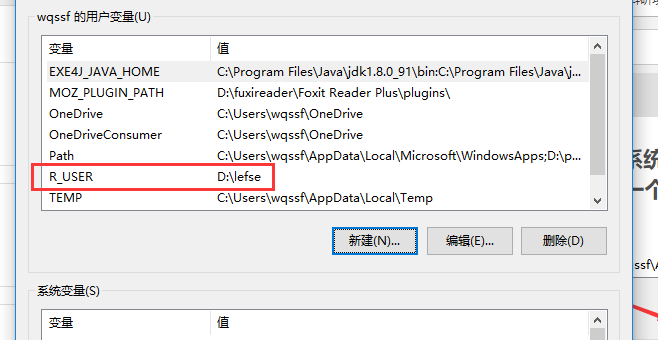
至此,准备就绪,我们需要去下载LEfSe分析的代码:https://bitbucket.org/nsegata/metaphlan/wiki/MetaPhlAn_Pipelines_Tutorial

然后解压如下图的代码:
得到如下文件:
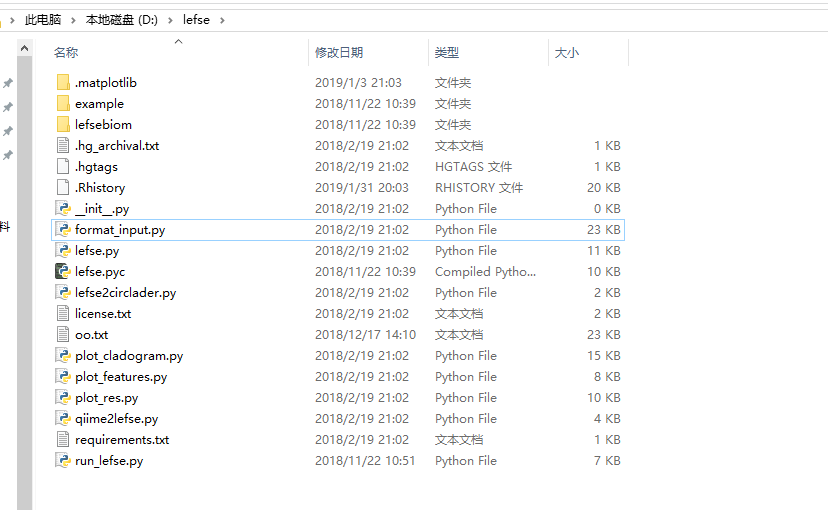
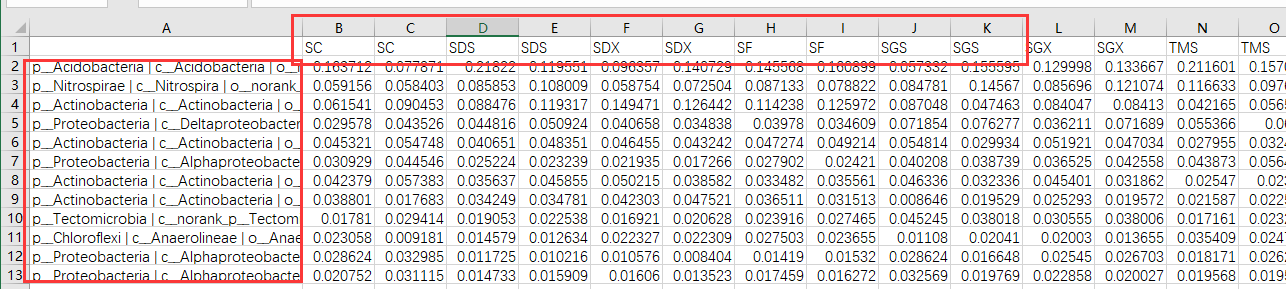
到这里前期工作准备得差不多了,我们需要对物种或者基因的数据进行格式整理:第一列为物种名字,第一行为样本重复(切记要灵活运用、操作):
开始做分析
打开CMD,把运行路径切换到待分析数据所在路径:我的数据在“D:\yingyong”,
D:
cd D:\yingyong
具体操作如下图。
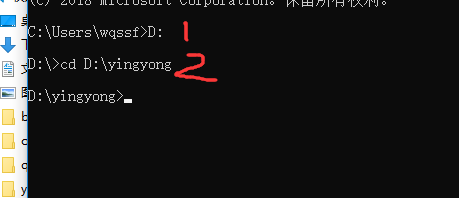
代码路径为“D:\lefse”,第一步:
D:\lefse\format_input.py hh.txt lefse.in.txt -c 1 -o 100000
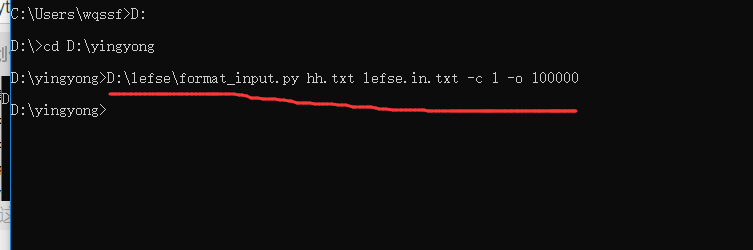
第二步:
D:\lefse\run_lefse.py lefse.in.txt lefse.out.txt -l 3
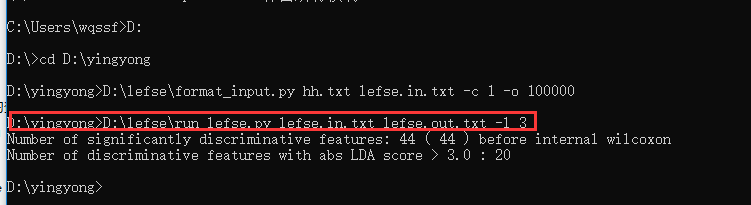
第三步:开始画图,
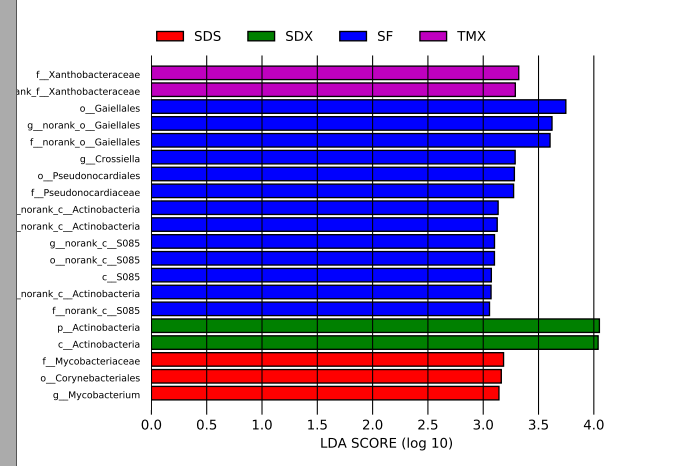
D:\lefse\plot_res.py lefse.out.txt lda.pdf --format pdf
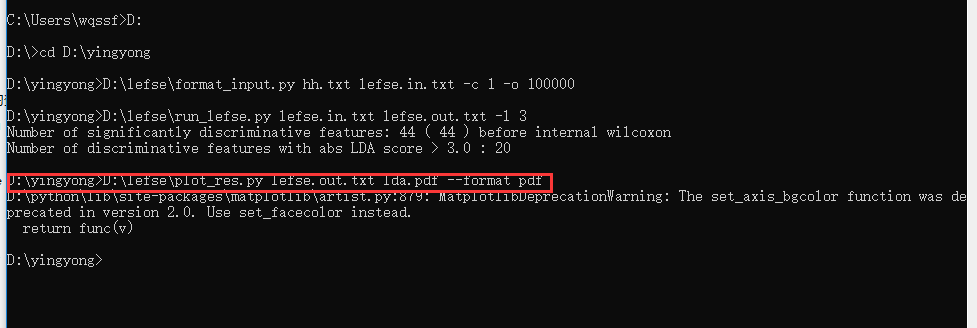
第四步:还是图,
D:\lefse\plot_cladogram.py lefse.out.txt yuan.pdf --format pdf --labeled_start_lev 1

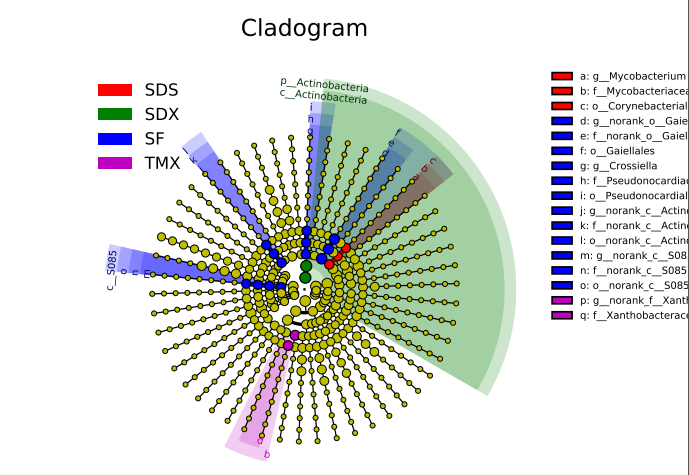
那么,LEfSe分析的常见图已经出来,对于biomarker在每个组中的相对丰度,这里不再演示,算是留个悬念,有需要的朋友可以自行探索或加入文后的QQ群→讨论。
对于上面的图,我们会发现物种名没有完全显示,这里我们推荐用AI软件(Adobe Illustrator)进行调整(是调整,不是修改!),对于LEfSe分析操作,需要自己灵活操作,照猫画虎绝对是不行的。对于图的解读可以参考已经发表的诸多papers。为加快初学者分析数据、绘图的速度,我们创建了一个QQ群:335774366。欢迎有兴趣的朋友加入→指导。
2019年了,祝各位朋友:“猪”事顺利→做一只特立独行的猪?。
声明:以上内容仅为作者个人理解,有不对的地方,欢迎指正。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/131286.html原文链接:https://javaforall.net


