
大家好,又见面了,我是你们的朋友全栈君。
1. Request对象
Request(.NET中的内置对象)—从客户端接收消息
获取前端的数据;比如form表单中的内容 ,cookis,表头信息,浏览器种类


2. 集合(对数据的封装)
对象中的集合是一个什么概念?
个人理解:
虽然取名叫做集合,但是我觉得集合其实就是一个方法,参数是前端数据,返回值是也前端的数据。
那么为什么设置这样子的一个方法呢?我觉得原因是可以将数据作为一个整体进行传递。
提供一个集合可以存储这些数据,那么我们主要传递一个集合就可以在服务器端使用这些数据,非常的方便。
当于对数据的一个封装。
做个比喻,对象相当于一个容器,里面放着几个小容器,每个小容器都存放着他自己的物品。
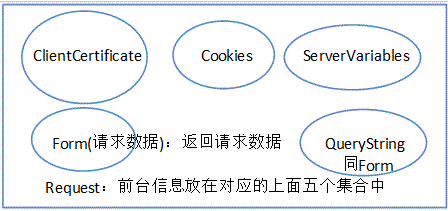
3. 对象向集合存和取数据的规则
向对象中存数据和取数据都有一定的规则。也就是说数据不是乱放的,数据只能够放在他自己的集合中。
1. 存数据:根据不同的提交方式会将数据存放在不同的对象集合中。
- post提交的时候存放在form集合
- get提交的时候存放在qureystring集合(变量和值都在url中显示出来(将表单数据以字符串的方式附加在网址的后面返回服务器))
这两个是比较常用的,那么为什么会区分出不同的集合呢!原因是他们是适合不同的情况。

Form集合中存放的表单值是比较多,比较大的.而QueryString正好相反它存的值是比较简单,比较少的.
2. 取数据:不同集合取数据的形式不同。
Request对象取得集合中数据的方式
1. Request(“”)
无论哪种集合都可以通过此方式取得数据
2. Request.集合
只能取得对应集合的数据
哪种比较好呢?这就要讲到下面的一个问题,对象处理集合中数据的顺序
4. 对象处理集合中数据的顺序
当需要调用集合中的数据,对象在集合中找数据是按照一定的顺序。
Request对象有几个集合来获取客户端提交的数据,一般常用的是QueryString,Form和ServerVariables。上面讲到的两种方式哪一种比较好,我们通过下面一个例子来了解。
如果 Get方式和Post方式提交了同样的一个变量,比如username=pf,那么你用Request(“username”)
取出来的到底是Get过来的数据还是Post过来的数据呢?
这里就提示我们: Request从这几个集合取数据是有顺序的。从前到后 的顺序依次是 QueryString,Form,最后是ServerVariables。Request对象按照这样的顺序依次搜索 这几个集合中的变量,如果有符合的就中止,后面的就不管了。 所以上面的例子Request(“username”)取到的实际是Get方法提交的数据。
所以为了提高效率,减少无谓的搜索时间,同时也是为了程序的规范,建议大家还是用Request.集合的
方式更好一点,比如Request.Form(“username”)。
下面是一个测试例子,提交以后,大家可以直接在地址后面加上 ?username=pf 来测试:
<%
If request(“submit”)<>”” then
Response.Write “直接取:”& Request(“username”) & “<br>”
Response.Write “取Get:” & Request.QueryString(“username”) & “<br>”
Response.Write “取Post:” & Request.Form(“username”) & “<br>”
End if
%>
<form name=form1 action=”” method=post>
<input type=test name=”username” value=”postuser”>
<input type=submit name=”submit” value=”test”>
</form>
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/131308.html原文链接:https://javaforall.net


