
大家好,又见面了,我是你们的朋友全栈君。
一、粒子群算法的概念
粒子群优化算法(PSO:Particle swarm optimization) 是一种进化计算技术(evolutionary computation)。源于对鸟群捕食的行为研究。粒子群优化算法的基本思想:是通过群体中个体之间的协作和信息共享来寻找最优解.
PSO的优势:在于简单容易实现并且没有许多参数的调节。目前已被广泛应用于函数优化、神经网络训练、模糊系统控制以及其他遗传算法的应用领域。
二、粒子群算法分析
1、基本思想
粒子群算法通过设计一种无质量的粒子来模拟鸟群中的鸟,粒子仅具有两个属性:速度和位置,速度代表移动的快慢,位置代表移动的方向。每个粒子在搜索空间中单独的搜寻最优解,并将其记为当前个体极值,并将个体极值与整个粒子群里的其他粒子共享,找到最优的那个个体极值作为整个粒子群的当前全局最优解,粒子群中的所有粒子根据自己找到的当前个体极值和整个粒子群共享的当前全局最优解来调整自己的速度和位置。下面的动图很形象地展示了PSO算法的过程:

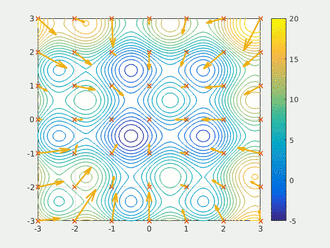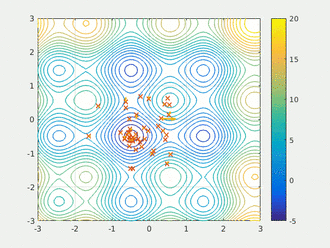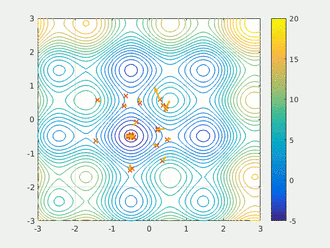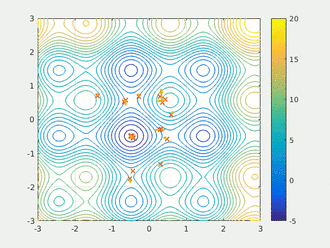
2、更新规则
PSO初始化为一群随机粒子(随机解)。然后通过迭代找到最优解。在每一次的迭代中,粒子通过跟踪两个“极值”(pbest,gbest)来更新自己。在找到这两个最优值后,粒子通过下面的公式来更新自己的速度和位置。
公式(1)的第一部分称为【记忆项】,表示上次速度大小和方向的影响;公式(1)的第二部分称为【自身认知项】,是从当前点指向粒子自身最好点的一个矢量,表示粒子的动作来源于自己经验的部分;公式(1)的第三部分称为【群体认知项】,是一个从当前点指向种群最好点的矢量,反映了粒子间的协同合作和知识共享。粒子就是通过自己的经验和同伴中最好的经验来决定下一步的运动。以上面两个公式为基础,形成了PSO的标准形式。
公式(2)和 公式(3)被视为标准PSO算法。


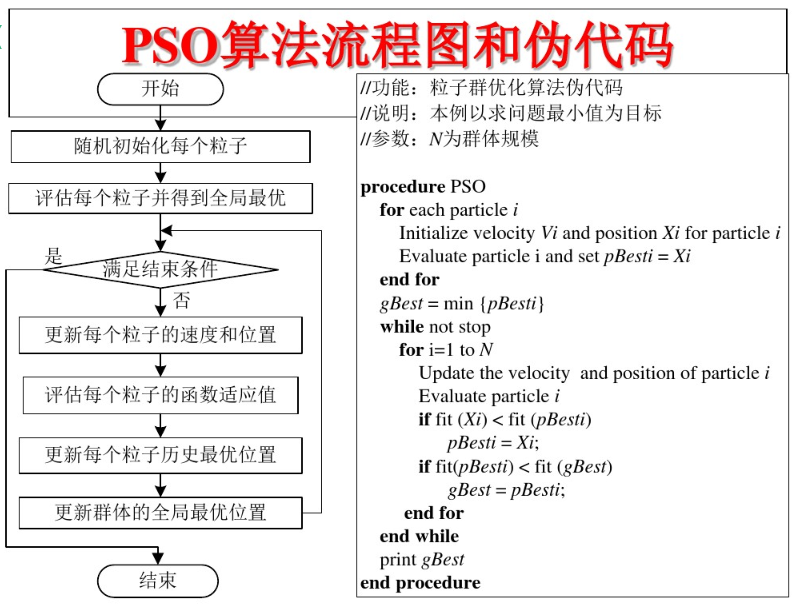
3、PSO算法的流程和伪代码
4、PSO算法举例


5、PSO算法的demo
#include <iostream>
#include <vector>
#include <cmath>
#include <map>
#include <algorithm>
#include <random>
#include <ctime>
#include <Eigen/Dense>
using namespace Eigen;
using namespace std;
const int dim = 1;//维数
const int p_num = 10;//粒子数量
const int iters = 100;//迭代次数
const int inf = 999999;//极大值
const double pi = 3.1415;
//定义粒子的位置和速度的范围
const double v_max = 4;
const double v_min = -2;
const double pos_max = 2;
const double pos_min = -1;
//定义位置向量和速度向量
vector<double> pos;
vector<double> spd;
//定义粒子的历史最优位置和全局最优位置
vector<double> p_best;
double g_best;
//使用eigen库定义函数值矩阵和位置矩阵
Matrix<double, iters, p_num> f_test;
Matrix<double, iters, p_num> pos_mat;
//定义适应度函数
double fun_test(double x)
{
double res = x * x + 1;
return res;
}
//初始化粒子群的位置和速度
void init()
{
//矩阵中所有元素初始化为极大值
f_test.fill(inf);
pos_mat.fill(inf);
//生成范围随机数
static std::mt19937 rng;
static std::uniform_real_distribution<double> distribution1(-1, 2);
static std::uniform_real_distribution<double> distribution2(-2, 4);
for (int i = 0; i < p_num; ++i)
{
pos.push_back(distribution1(rng));
spd.push_back(distribution2(rng));
}
vector<double> vec;
for (int i = 0; i < p_num; ++i)
{
auto temp = fun_test(pos[i]);//计算函数值
//初始化函数值矩阵和位置矩阵
f_test(0, i) = temp;
pos_mat(0, i) = pos[i];
p_best.push_back(pos[i]);//初始化粒子的历史最优位置
}
std::ptrdiff_t minRow, minCol;
f_test.row(0).minCoeff(&minRow, &minCol);//返回函数值矩阵第一行中极小值对应的位置
g_best = pos_mat(minRow, minCol);//初始化全局最优位置
}
void PSO()
{
static std::mt19937 rng;
static std::uniform_real_distribution<double> distribution(0, 1);
for (int step = 1; step < iters; ++step)
{
for (int i = 0; i < p_num; ++i)
{
//更新速度向量和位置向量
spd[i] = 0.5 * spd[i] + 2 * distribution(rng) * (p_best[i] - pos[i]) +
2 * distribution(rng) * (g_best - pos[i]);
pos[i] = pos[i] + spd[i];
//如果越界则取边界值
if (spd[i] < -2 || spd[i] > 4)
spd[i] = 4;
if (pos[i] < -1 || pos[i] > 2)
pos[i] = -1;
//更新位置矩阵
pos_mat(step, i) = pos[i];
}
//更新函数值矩阵
for (int i = 0; i < p_num; ++i)
{
auto temp = fun_test(pos[i]);
f_test(step, i) = temp;
}
for (int i = 0; i < p_num; ++i)
{
MatrixXd temp_test;
temp_test = f_test.col(i);//取函数值矩阵的每一列
std::ptrdiff_t minRow, minCol;
temp_test.minCoeff(&minRow, &minCol);//获取每一列的极小值对应的位置
p_best[i] = pos_mat(minRow, i);//获取每一列的极小值,即每个粒子的历史最优位置
}
g_best = *min_element(p_best.begin(), p_best.end());//获取全局最优位置
}
cout << fun_test(g_best);
}
int main()
{
init();
PSO();
system("pause");
return 0;
}参考:https://blog.csdn.net/myarrow/article/details/51507671
https://blog.csdn.net/google19890102/article/details/30044945
https://wenku.baidu.com/view/65c600b9294ac850ad02de80d4d8d15abe230048.html
https://blog.csdn.net/darin1997/article/details/80675933
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/132684.html原文链接:https://javaforall.net

![SpringBoot集成拦截器[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
