
大家好,又见面了,我是你们的朋友全栈君。
三分钟上手,完全分布式搭建HDFS
一,环境的准备
Linux (观看Linux安装及常用指令)
JDK(观看Linux安装jdk文档)
准备至少3台机器(通过克隆虚拟机;配置好网络JDK 时间 hosts,保证节点间能互ping通)
时间同步
ssh免密钥登陆(两两互通免密钥)
二,开始安装及相关配置文件
我这边三个节点分别为 : node01 node02 node03
node01 上面部署 namenode 和 datanode
node02 上面部署 secondaryNameNode 和 datanode
node03 上面部署 datanode
2.1 下载解压缩 hadoop
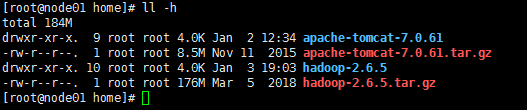

2.2 配置etc/hadoop/hadoop-env.sh
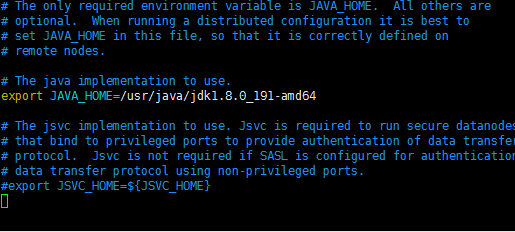
export JAVA_HOME= “你的Jdk安装目录” 如图
2.3 配置core-site.xml
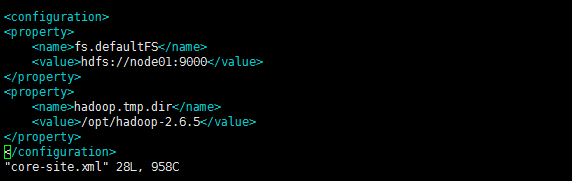
配置解释:
<configuration>
<property>
//配置namenode所在的服务器
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
//hadoop.tmp.dir 是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配 置namenode和datanode的存放位置,默认就放在这个路径中
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.6.5</value>
</property>
</configuration>
2.4 hdfs-site.xml配置
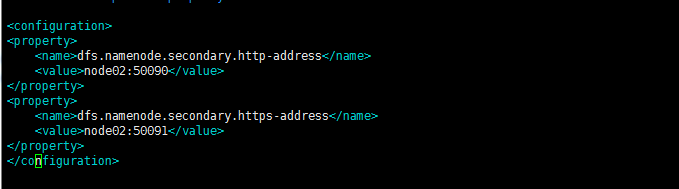
配置解释:
<configuration>
<property>
//block保存的副本数量,不配置默认是3 我这边是没配置
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node02:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>node02:50091</value>
</property>
</configuration>
2.5 写上SNN节点名: node02
在/home/hadoop-2.6.5/etc/hadoop/新建masters文件
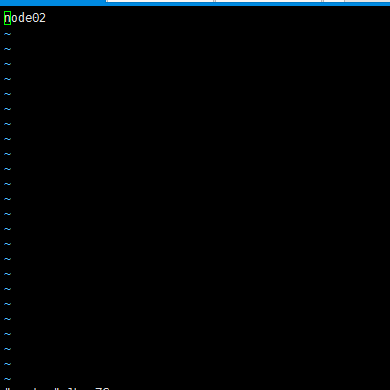
2.6 配置datanode存放服务器
在 slaves 中配置

注意:每行写一个 写成3行
2.7 分发节点
直接把压缩好的 hadoop 发送到node02 node03 节点上

2.8 配置 Hadoop的环境变量
vi ~/.bash_profile
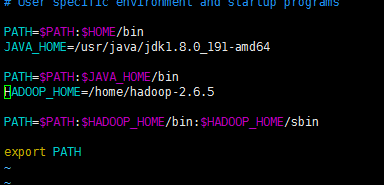
2.9 命令: source ~/.bash_profile
不然你的环境变量不会生效
2.10 格式化 NameNode –> 第一次需要
hdfs namenode -format
2.11 关闭防火墙
service iptables stop
2.12 启动 HDFS
start-dfs.sh
[root@node01 home]# start-dfs.sh
Starting namenodes on [node01]
node01: starting namenode, logging to /home/hadoop-2.6.5/logs/hadoop-root-namenode-node01.out
node03: starting datanode, logging to /home/hadoop-2.6.5/logs/hadoop-root-datanode-node03.out
node02: starting datanode, logging to /home/hadoop-2.6.5/logs/hadoop-root-datanode-node02.out
node01: starting datanode, logging to /home/hadoop-2.6.5/logs/hadoop-root-datanode-node01.out
Starting secondary namenodes [node02]
node02: starting secondarynamenode, logging to /home/hadoop-2.6.5/logs/hadoop-root-secondarynamenode-node02.out
先启动 namenode,再启动 datanode ,最后是 secondaryNameNode
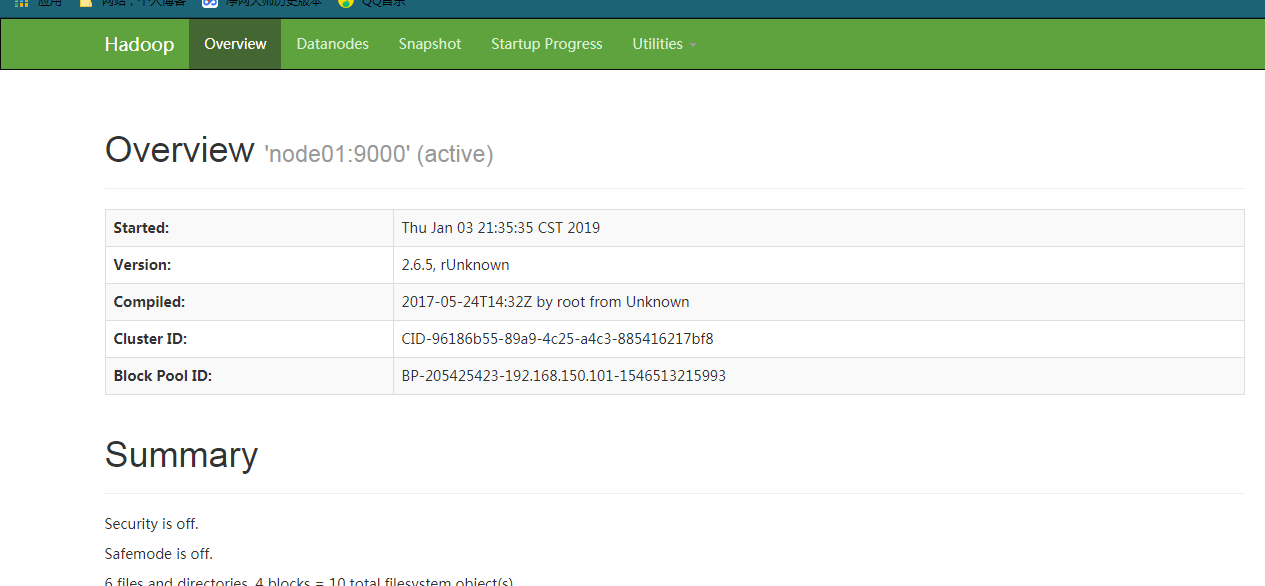
浏览器输入 node01:50070(前提是你在windows配置了 hosts),出现下面界面说明成功
2.13 查看 jps进程
node01:
[root@node01 home]# jps
3617 DataNode
3529 NameNode
3839 Jps
[root@node01 home]#
node02:
[root@node02 hadoop]# jps
2344 Jps
2296 SecondaryNameNode
2205 DataNode
[root@node02 hadoop]#
node03:
[root@node03 subdir0]# jps
1923 Jps
1854 DataNode
[root@node03 subdir0]#
说明你的分布式HDFS搭建成功!!!
三,常用hdfs dfs 命令
3.1 查看hdfs指定目录下的文件
hdfs dfs -ls 路径
3.2 创建文件夹
hdfs dfs -mkdir /data ##创建一个名为data的文件夹
3.3 删除文件夹
hdfs dfs -rm -r /data ##删除在根目录下 名为 data的文件夹
3.4 上传文件到hdfs
hdfs dfs -put 文件路径和名称 /data —>上传文件到hdfs /data文件下
3.5 下载文件到本地
hdfs dfs -get 要下载的文件路径和名称
3.6 复制文件夹到本地
hdfs dfs -copyToLocal 要下载的文件路径和名称
很多命令和Linux中都是大同小异,这里就不过多列举,感兴趣的小伙伴可以自行查看。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/132835.html原文链接:https://javaforall.net


