
大家好,又见面了,我是你们的朋友全栈君。
笔记大纲
1、jvm内存结构图
2、jvm按照线程共享和私有内存区域划分结构图
3、堆和栈在功能、内存大小、线程共享私有进行比较
4、JVM运行结构图
5、线程安全本质时序图
6、jdk6、7、8三个版本内存模型比较
7、jdk1.8为什么将方法区移除到本地内存
8、jvm内存启动参数详解
JVM内存结构图(JDK1.6)
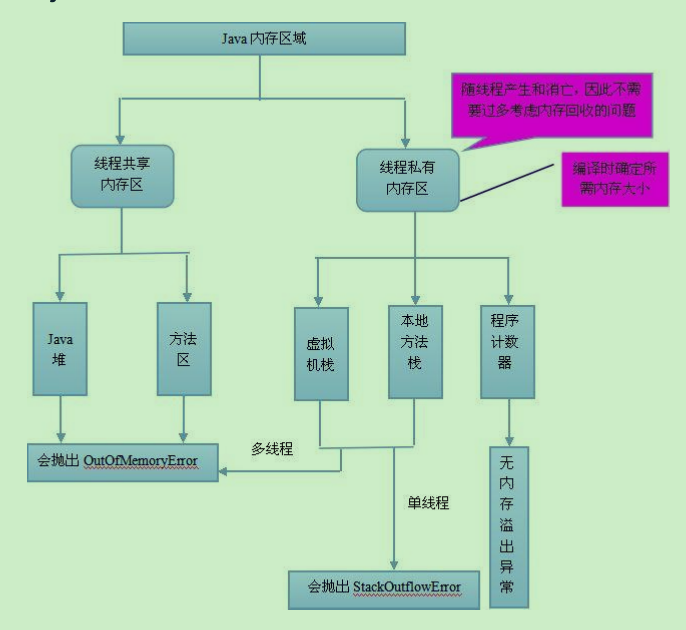
多线程共享内存区域:
方法区、堆。
方法区、堆。
每一个线程独享内存:
java栈、本地方法栈、程序计数器。
java栈、本地方法栈、程序计数器。
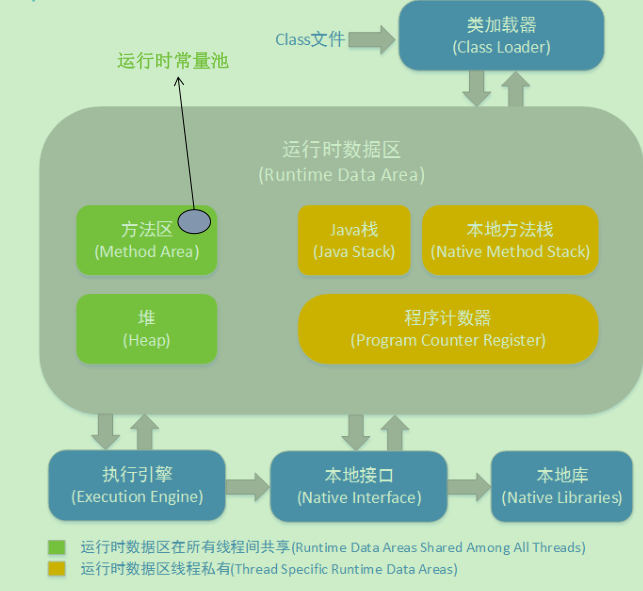

程序计数器:较小的内存空间,
当前线程执行的字节码的行号指示器;各线程之间独立存储,互不影响;
当前线程执行的字节码的行号指示器;各线程之间独立存储,互不影响;
java 栈:线程私有,生命周期和线程,每个方法在执行的同时都会创建一个 栈帧用于
存储局部变量表,操作数栈,动态链接,方法出口等信息。方法的执行就对应着栈帧在虚拟机栈中入栈和出栈的过程;栈里面存放着各种基本数据类型和对象的引用;
存储局部变量表,操作数栈,动态链接,方法出口等信息。方法的执行就对应着栈帧在虚拟机栈中入栈和出栈的过程;栈里面存放着各种基本数据类型和对象的引用;
本地方法栈:本地方法栈保存的是native方法的信息,当一个JVM创建的线程调用native方法后,JVM不再为其在虚拟机栈中创建栈帧,
JVM只是简单地动态链接并直接调用native方法;
JVM只是简单地动态链接并直接调用native方法;
堆:Java堆是程序员需要重点关注的一块区域,因为涉及到内存的分配(new关键字,反射等)与回收(回收算法,收集器等);
方法区:也叫永久区,用于存储已经被虚拟机加载的类信息,常量(“zdy”,”123″等),静态变量(static变量)等数据。
(jdk1.8已经将方法区去掉了,将方法区移动到直接内存)
(jdk1.8已经将方法区去掉了,将方法区移动到直接内存)
运行时常量池:
运行时常量池是方法区的一部分,用于存放编译期生成的各种字面(“zdy”,”123″等)和符号引用。
运行时常量池是方法区的一部分,用于存放编译期生成的各种字面(“zdy”,”123″等)和符号引用。
直接内存:不是虚拟机运行时数据区的一部分,也不是java虚拟机规范中定义的内存区域;
1)如果使用了NIO,这块区域会被频繁使用,在java堆内可以用directByteBuffer对象直接引用并操作;
2) 这块内存不受java堆大小限制,但受本机总内存的限制,可以通过MaxDirectMemorySize来设置(默认与堆内存最大值一样),所以也会出现OOM异常;
JVM内存中按照线程共享和线程私有划分结构图(JDK1.6)
堆和栈的区别
1)堆和栈功能上的区别
以栈帧的方式存储方法调用的过程,并存储方法调用过程中
基本数据类型的变
基本数据类型的变
量(int、short、long、byte、float、double、boolean、char等)以及对象的引
用变量,其内存分配在栈上,
变量出了作用域就会自动释放;
变量出了作用域就会自动释放;
而堆内存用来
存储Java中的对象。无论是成员变量,局部变量,还是类变量,
存储Java中的对象。无论是成员变量,局部变量,还是类变量,
它们指向的对象都存储在堆内存中;
2)堆和栈在线程共享和线程私有区别
栈内存归属于单个线程,每个线程都会有一个栈内存,其存储的变量只能在其所属线程中可见,即栈内存可以理解成
线程的私有内存。
线程的私有内存。
堆内存中的对象对所有线程可见。堆内存中的对象可以被所有线程访问。
3)空间大小
栈的内存要远远小于堆内存,栈的深度是有限制的,如果递归没有及时跳出,很可能发生StackOverFlowError问题。
你可以通过-Xss选项设置栈内存的大小(
这个参数是设定单个线程的栈空间)。-Xms选项可以设置堆的开始时的大小,-Xmx选项可以设置堆的最大值
这个参数是设定单个线程的栈空间)。-Xms选项可以设置堆的开始时的大小,-Xmx选项可以设置堆的最大值
JVM内存运行时结构图
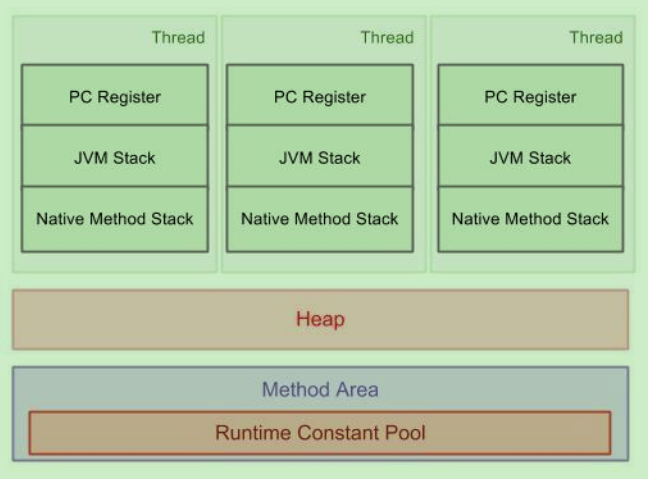
每一个线程独享的内存区域有:程序计数器、java栈、本地方法栈
线程共享区域:堆内存、方法区(JDK1.8已经去掉了方法区)
线程安全本质
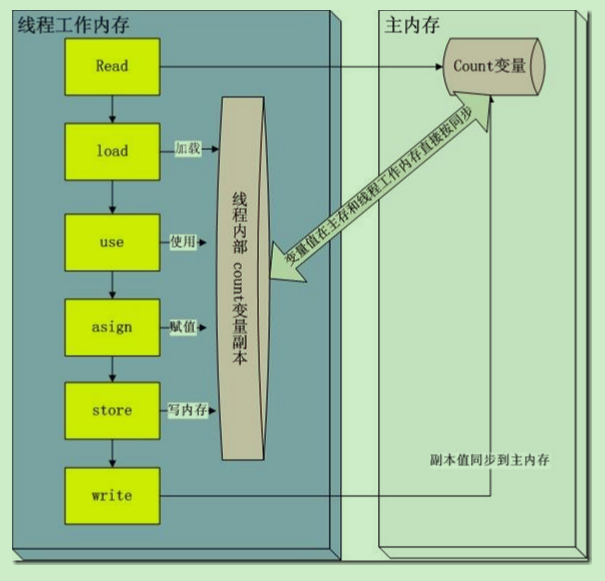
线程安全本质是由于多个线程对同一个堆内存中的Count变量操作的时候,每一个线程会在线程内部创建这个堆内存Count变量的副本,线程内所有的操作都是对这个Count副本进行操作。这时如果其他线程操作这个堆内存Count变量,改变了Count值对这个线程是不可见的。当前线程操作完Count变量将值从副本空间写到主内存(堆内存)的时候就会覆盖其他线程操作Count变量的结果,引发线程不安全问题。
JDK1.6,JDK1.7,JDK1.8不同版本JVM内存模型区别
相对于jdk1.6,jDK1.7将运行时常量池从方法区移除到堆内存。
相对于JDK1.6,JDK1.8直接
将方法区去掉,在本地内存中新增
元数据空间。运行时常量池仍然在堆中。元数据区存放类加载信息。
将方法区去掉,在本地内存中新增
元数据空间。运行时常量池仍然在堆中。元数据区存放类加载信息。
JDK1.8为什么要移除方法区
1)永久代来存储类信息、常量、静态变量等数据不是个好主意, 很容易遇到内存溢出的问题.JDK8的实现中将类的元数据放入 native memory, 将字符串池和类的静态变量放入java堆中. 可以使用MaxMetaspaceSize对元数据区大小进行调整;
2)对永久代进行调优是很困难的,同时将元空间与堆的垃圾回收进行了隔离,避免永久代引发的Full GC和OOM等问题;
JVM内存参数设定
-Xms 初始堆内存大小
-Xmx 最大堆内存大小
-Xss 单个线程栈大小
-XX:NewSize 初始新生代堆大小
-XX:MaxNewSize 生代最大堆大小
-XX:PermSize 方法区初始大小(JDK1.7及以前)
-XX:MaxPermSize 方法区最大大小(JDK1.7及以前)
-XX:MetaspaceSize 元数据区初始值(JDK1.8)
-XX:MaxMetaspaceSize 元数据区最大值(JDK1.8)
参数设置示例
jdk1.7 windows设置tomcat的catalina.bat
set JAVA_OPTS=-Xms1024m -Xmx1024m -Xss1m -XX:PermSize=128m -XX:MaxPermSize=256m -XX:NewSize=256m -XX:MaxNewSize=256m
jdk1.8 windows设置tomcat的catalina.bat
set JAVA_OPTS=-Xms1024m -Xmx1024m -Xss1m -XX:MetaspaceSize=128m -XX:MAXMetaspaceSize=256m -XX:NewSize=256m -XX:MaxNewSize=256m
jdk1.7 linux设置tomcat的catalina.sh
JAVA_OPTS=-Xms1024m -Xmx1024m -Xss1m -XX:PermSize=128m -XX:MaxPermSize=256m -XX:NewSize=256m -XX:MaxNewSize=256m
jdk1.8 linux设置tomcat的catalina.sh
JAVA_OPTS=-Xms1024m -Xmx1024m -Xss1m -XX:MetaspaceSize=128m -XX:MAXMetaspaceSize=256m -XX:NewSize=256m -XX:MaxNewSize=256m
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/135665.html原文链接:https://javaforall.net


