
大家好,又见面了,我是你们的朋友全栈君。
注:对代码及思路进行了改进—Java网络爬虫(十一)–重构定时爬取以及IP代理池(多线程+Redis+代码优化)
定点爬取
当我们需要对金融行业的股票信息进行爬取的时候,由于股票的价格是一直在变化的,我们不可能手动的去每天定时定点的运行程序,这个时候我们就需要实现定点爬取了,我们引入第三方库quartz的使用:
package timeutils;
import org.quartz.CronTrigger;
import org.quartz.JobDetail;
import org.quartz.Scheduler;
import org.quartz.SchedulerFactory;
import org.quartz.impl.StdSchedulerFactory;
import java.text.SimpleDateFormat;
import java.util.Date;
import static org.quartz.CronScheduleBuilder.cronSchedule;
import static org.quartz.JobBuilder.newJob;
import static org.quartz.TriggerBuilder.newTrigger;
/** * Created by paranoid on 17-4-13. */
public class TimeUpdate {
public void go() throws Exception {
// 首先,必需要取得一个Scheduler的引用(设置一个工厂)
SchedulerFactory sf = new StdSchedulerFactory();
//从工厂里面拿到一个scheduler实例
Scheduler sched = sf.getScheduler();
//真正执行的任务并不是Job接口的实例,而是用反射的方式实例化的一个JobDetail实例
JobDetail job = newJob(MyTimeJob.class).withIdentity("job1", "group1").build();
// 定义一个触发器,job 1将每隔执行一次
CronTrigger trigger = newTrigger().withIdentity("trigger1", "group1").
withSchedule(cronSchedule("50 47 17 * * ?")).build();
//执行任务和触发器
Date ft = sched.scheduleJob(job, trigger);
//格式化日期显示格式
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSS");
System.out.println(job.getKey() + " 已被安排执行于: " + sdf.format(ft) + "," +
"并且以如下重复规则重复执行: " + trigger.getCronExpression());
sched.start();
}
public static void main(String[] args) throws Exception {
TimeUpdate test = new TimeUpdate();
test.go();
}
}
在上面的代码中,已经详细的给出了实现定时爬取的基本代码:
JobDetail job = newJob(MyTimeJob.class).withIdentity("job1", "group1").build();这句代码中的MyTimeJob.class就是我们要执行的任务代码,它是通过类的反射加载机制进行运行的,之后我们设置它为第一组的第一个任务。
要使用这个第三方库我们需要了解一些cron表达式的概念,网上由于对它的说明很多,我就不再这里进行说明 ,大家可以看到:
cronSchedule("50 47 17 * * ?")我设置的是每天的17:47:50秒运行这个程序。
值得注意的是:我们所要执行的任务必须写在execute方法之中,在下面的代码就是一个实例,也就是我们需要实现的IP代理池。
IP代理池
在网上搜索了很多关于反爬虫的机制,实用的还是IP代理池,我依照网上的思想自己写了一个,大致的思路是这样的:
- 首先我使用本机IP在xici(西刺)代理网站上的高匿IP代理区抓取了第一页的代理IP放入了一个数组之中;
- 然后我使用数组中的IP对要访问的页面进行轮番调用,每访问一个页面就换一个IP;
- 我将得到的IP按链接速度的快慢进行排序,选需速度最快的前100个;
- 我对得到的IP进行测试,如果不能使用就在容器中删除;
- 将最终的IP写入数据库中。
实现IP代理池的主要逻辑代码如下:
package timeutils;
import IPModel.DatabaseMessage;
import IPModel.IPMessage;
import database.DataBaseDemo;
import htmlparse.URLFecter;
import ipfilter.IPFilter;
import ipfilter.IPUtils;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/** * Created by paranoid on 17-4-13. */
public class MyTimeJob implements Job {
public void execute(JobExecutionContext argv) throws JobExecutionException {
List<String> Urls = new ArrayList<>();
List<DatabaseMessage> databaseMessages = new ArrayList<>();
List<IPMessage> list = new ArrayList<>();
List<IPMessage> ipMessages = new ArrayList<>();
String url = "http://www.xicidaili.com/nn/1";
String IPAddress;
String IPPort;
int k, j;
//首先使用本机ip进行爬取
try {
list = URLFecter.urlParse(url, list);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
//对得到的IP进行筛选,选取链接速度前100名的
list = IPFilter.Filter(list);
//构造种子Url
for (int i = 1; i <= 5; i++) {
Urls.add("http://www.xicidaili.com/nn/" + i);
}
//得到所需要的数据
for (k = 0, j = 0; j < Urls.size(); k++) {
url = Urls.get(j);
IPAddress = list.get(k).getIPAddress();
IPPort = list.get(k).getIPPort();
//每次爬取前的大小
int preIPMessSize = ipMessages.size();
try {
ipMessages = URLFecter.urlParse(url, IPAddress, IPPort, ipMessages);
//每次爬取后的大小
int lastIPMessSize = ipMessages.size();
if(preIPMessSize != lastIPMessSize){
j++;
}
//对IP进行轮寻调用
if (k >= list.size()) {
k = 0;
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
//对得到的IP进行筛选,选取链接速度前100名的
ipMessages = IPFilter.Filter(ipMessages);
//对ip进行测试,不可用的从数组中删除
ipMessages = IPUtils.IPIsable(ipMessages);
for(IPMessage ipMessage : ipMessages){
out.println(ipMessage.getIPAddress());
out.println(ipMessage.getIPPort());
out.println(ipMessage.getServerAddress());
out.println(ipMessage.getIPType());
out.println(ipMessage.getIPSpeed());
}
//将得到的IP存储在数据库中(每次先清空数据库)
try {
DataBaseDemo.delete();
DataBaseDemo.add(ipMessages);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
//从数据库中将IP取到
try {
databaseMessages = DataBaseDemo.query();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
for (DatabaseMessage databaseMessage: databaseMessages) {
out.println(databaseMessage.getId());
out.println(databaseMessage.getIPAddress());
out.println(databaseMessage.getIPPort());
out.println(databaseMessage.getServerAddress());
out.println(databaseMessage.getIPType());
out.println(databaseMessage.getIPSpeed());
}
}
}整个IP代理池程序的实现架构如下:

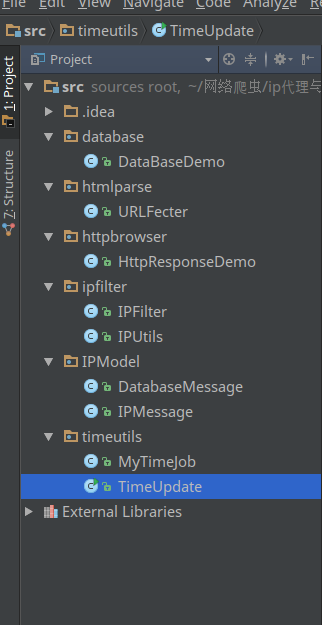
- database包中包装了数据库的各种操作;
- htmlparse包中主要实现了对得到的html页面的解析工作;
- httpbrowser包中主要实现了返回请求Url返回html页面的工作;
- ipfilter包中主要实现了IP的过滤(速度可好)和检测(是否可用);
- ipmodel中主要封装了抓取ip的维度和从数据库中拿到的ip的维度;
- timeutils主要实现了定点爬取和整体逻辑。
源码链接
有兴趣的同学可以前往我的github上查看整个项目的源码,代码量不多而且注释也比较清晰,如果觉得不错的话可以给个星哦~~
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/137544.html原文链接:https://javaforall.net


