
大家好,又见面了,我是你们的朋友全栈君。
前一篇我们已经介绍了MODIS数据的简介、参数以及相关的典型应用。这一篇我们来介绍下MODIS数据的下载方式。当然这边主要是介绍国外网站的下载方式,国内网站的普遍是在地理空间数据云和遥感集市下载。国外网站(NASA官网)下载方式主要介绍两种。本篇主要针对第一种方式,基于完整的一景影像下载的过程(FTP工具)。后面一篇更新的是基于MODIS Web Service的客户端下载的方式(Matlab和R)。
FTP下载工具以及完整影像下载的方法
笔者最早也是参照网上某篇博客学习的下载方式,老规矩,文末贴链接,这里先感谢这位写博客的同学。同时NASA官网最近刚刚改版了网站,新版网站的下载方式暂时没有看到其他人整理,故稍作些整理。
NASA官方遥感影像数据下载网址(里面不止有MODIS,还有ENVISAT,NPP-VIIRS等):

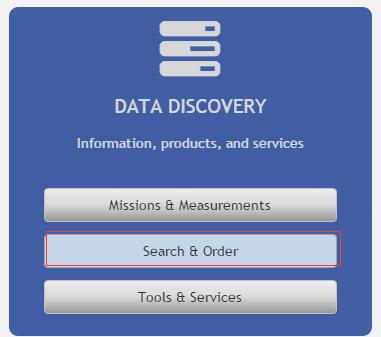
选择DATA DISCOVERY的Search&Order:
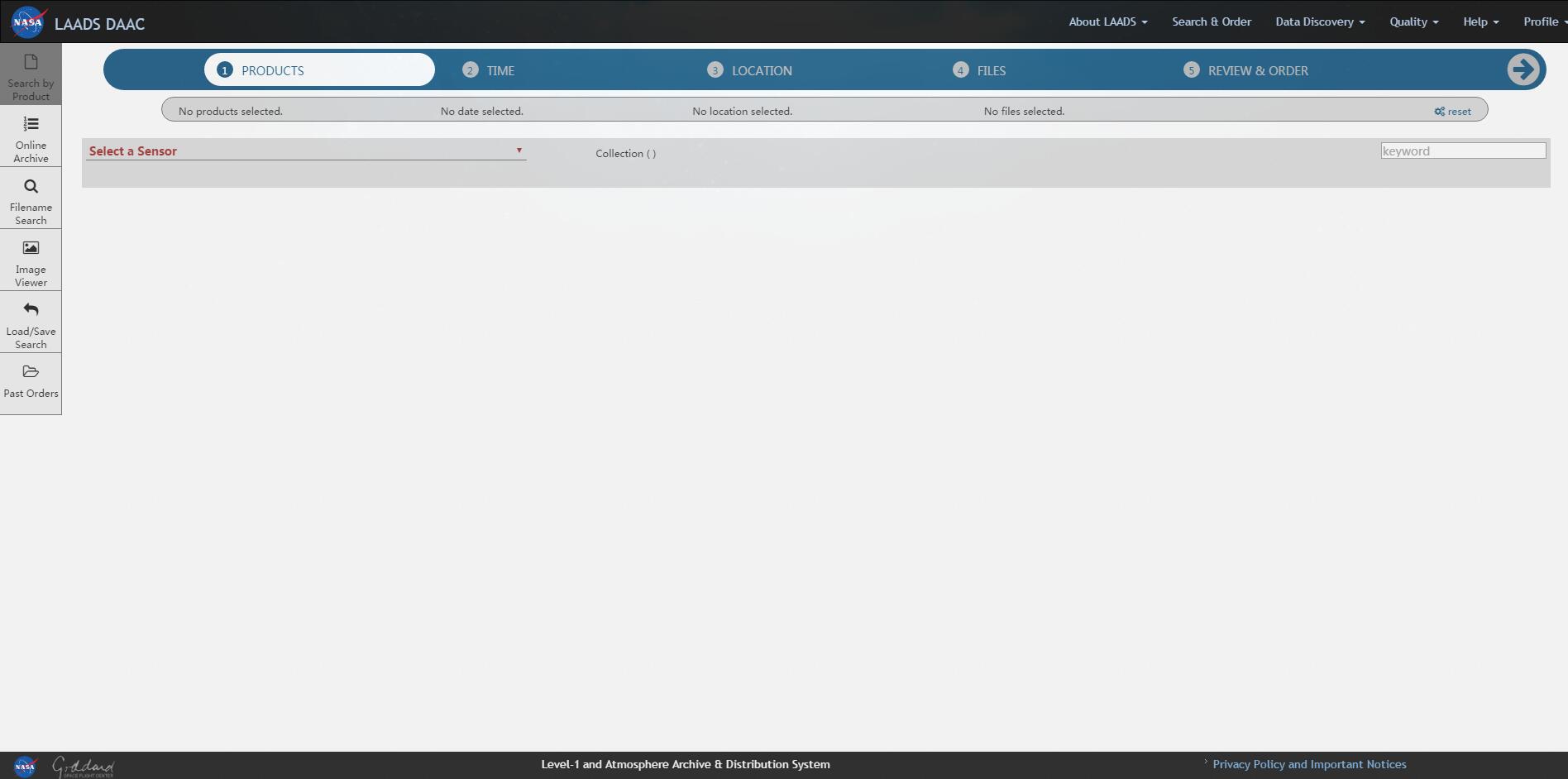
进入这个页面:
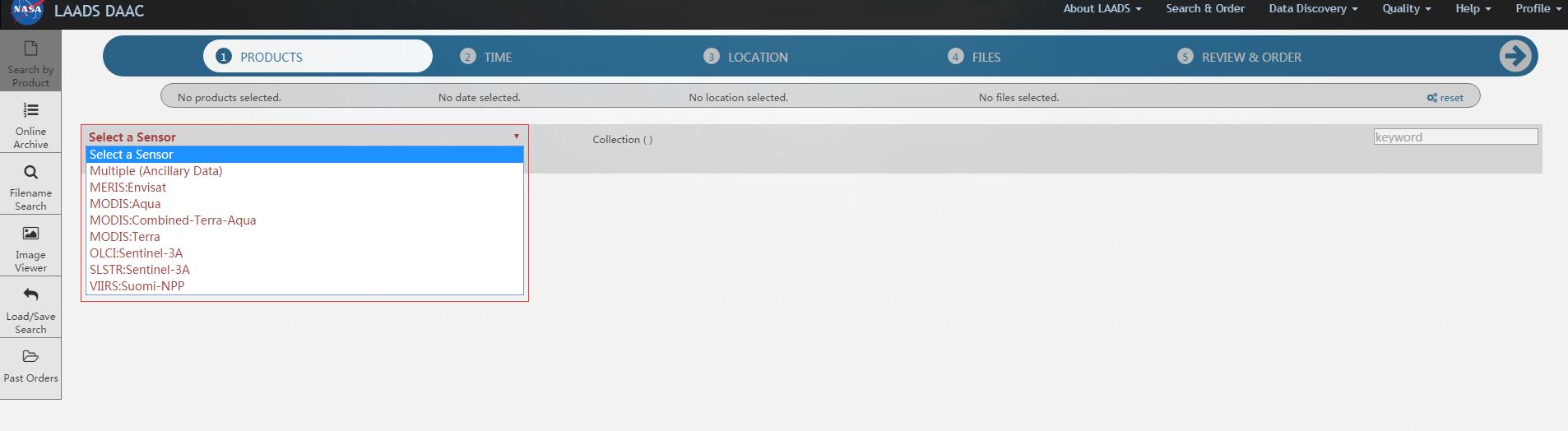
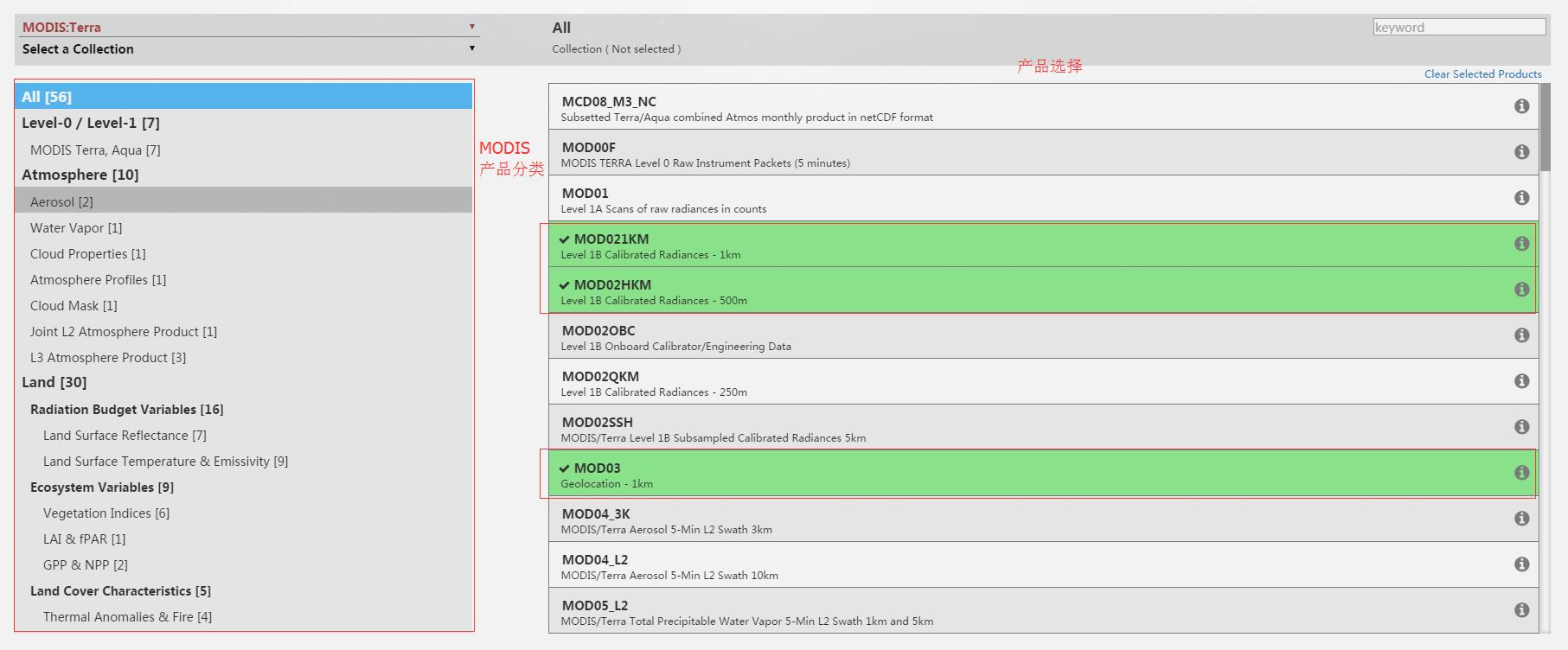
找到你要下载的卫星传感器(这里以Terra星做例子):
选择我们需要的产品(这里选了1 km、500 m的二级产品,以及经纬度校正的产品,具体产品介绍看上一篇博客的表格以及列出的链接):
结束后直接点击
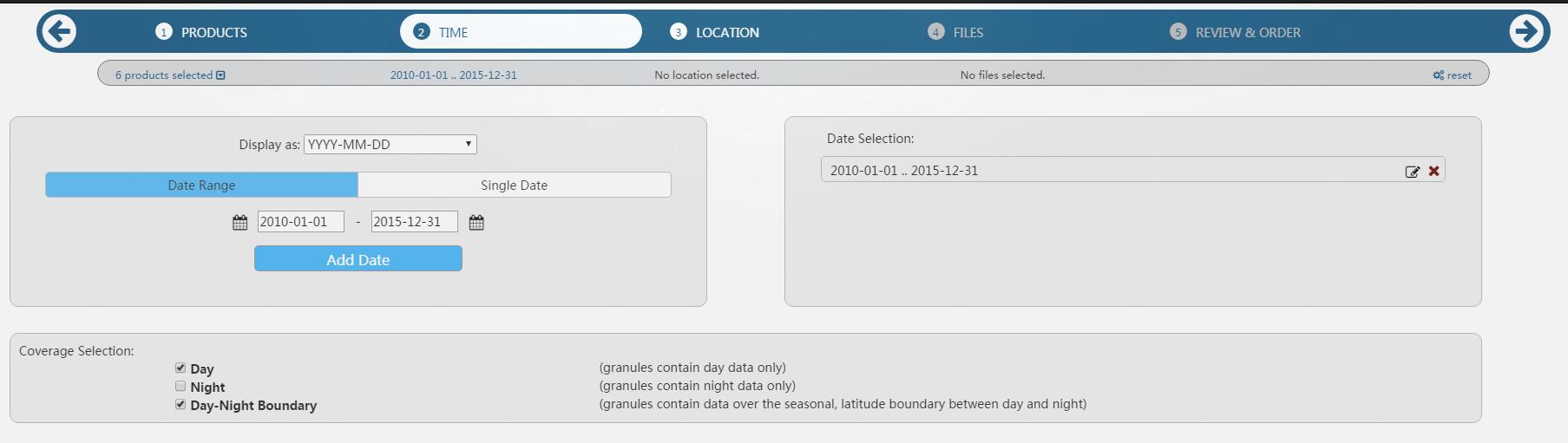
“TIME”,根据需要选择数据的时间跨度。
接着点击下一步,“LOCATION”。
有不同选择需要影像范围的方法。
Country→按国家的行政边界来选择数据
Tiles→按瓦片选择,或者说按照MODIS数据全球逐行逐列划分的格网(也可以说是MODIS观测时的行列号)来选择数据
Validation Sites→按全球分布的验证的观测站点或者生态网络观测站点选择(可以结合观测站点数据做研究)
Draw Custom Box(Classic)→按照用户自定义画出来的框选选择数据(用过老版网站下载的同学会对这个功能比较熟悉)
Enter Coordinates→用经纬度坐标来选择数据(这个也是类似于老版网站的下载功能),其实就是研究区的四至坐标。
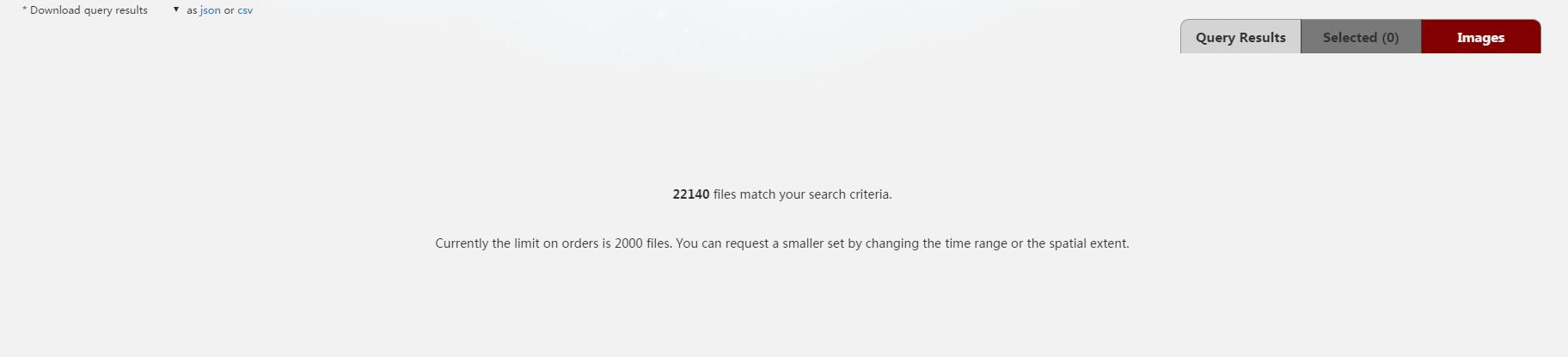
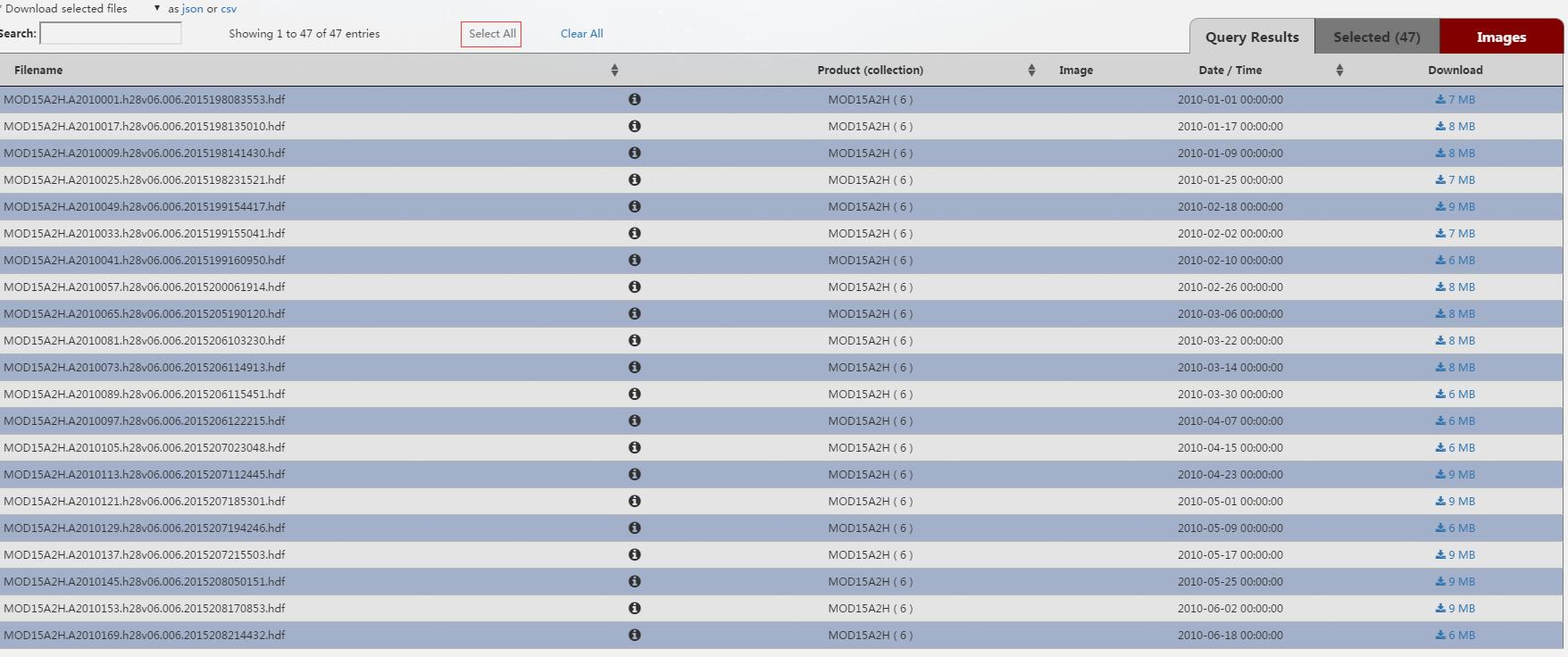
这里选择了按瓦片选择的方式,点击箭头。下一步,“FILES”。这一步会把符合要求的所有数据列出来,但是由于前面搜索的时间跨度太长,web端无法完全显示,所以我们重新修改下相关的需求数据(仅选择2010年的数据,而且选择下载合成产品)。
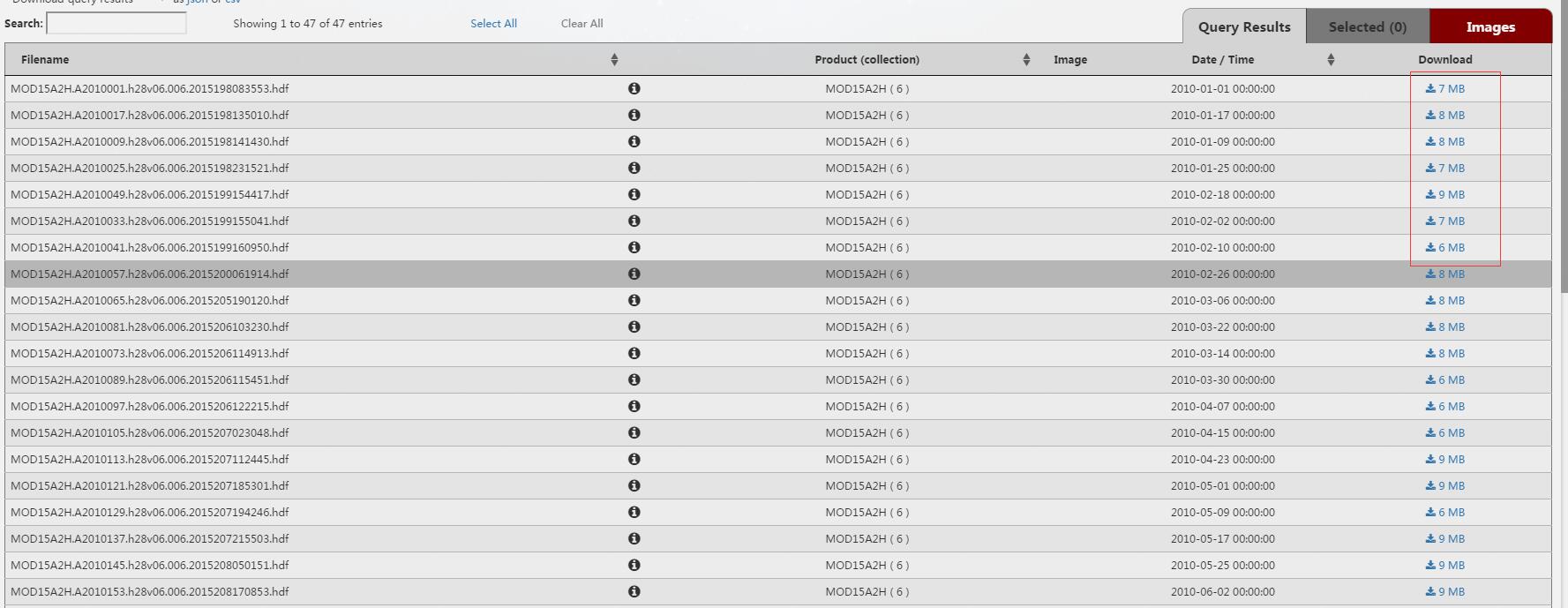
接下来是新版网站的一个比较不同的地方,这里的”FILES“,可以直接下载数据。老版网站一般需要Order,提交订单之后才能下载。这样使用比原来更自由些。
现在选择所有数据,提交订单即可。
不过新版网站现在要求要注册账户。所以在下载数据前,记得先申请一个Earthdata的账户(这也就是比较麻烦的点了,目前笔者测试了163和qq邮箱,都没有办法收到激活邮件。目前只有谷歌邮箱能激活,所以必须去注册一个gmail的邮箱)。
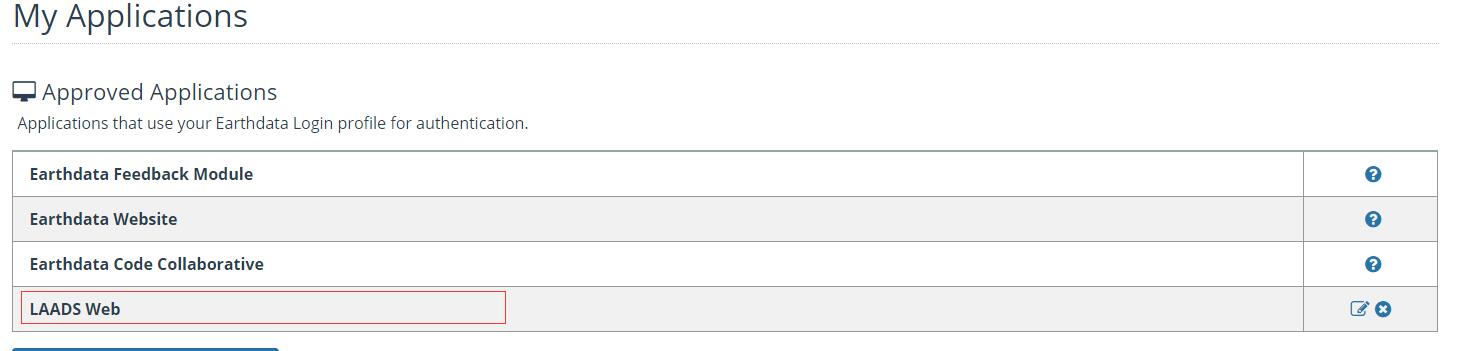
注意,需要在自己的账户中的“My Application”下面启动“LAADS Web”,最后才能提交订单。
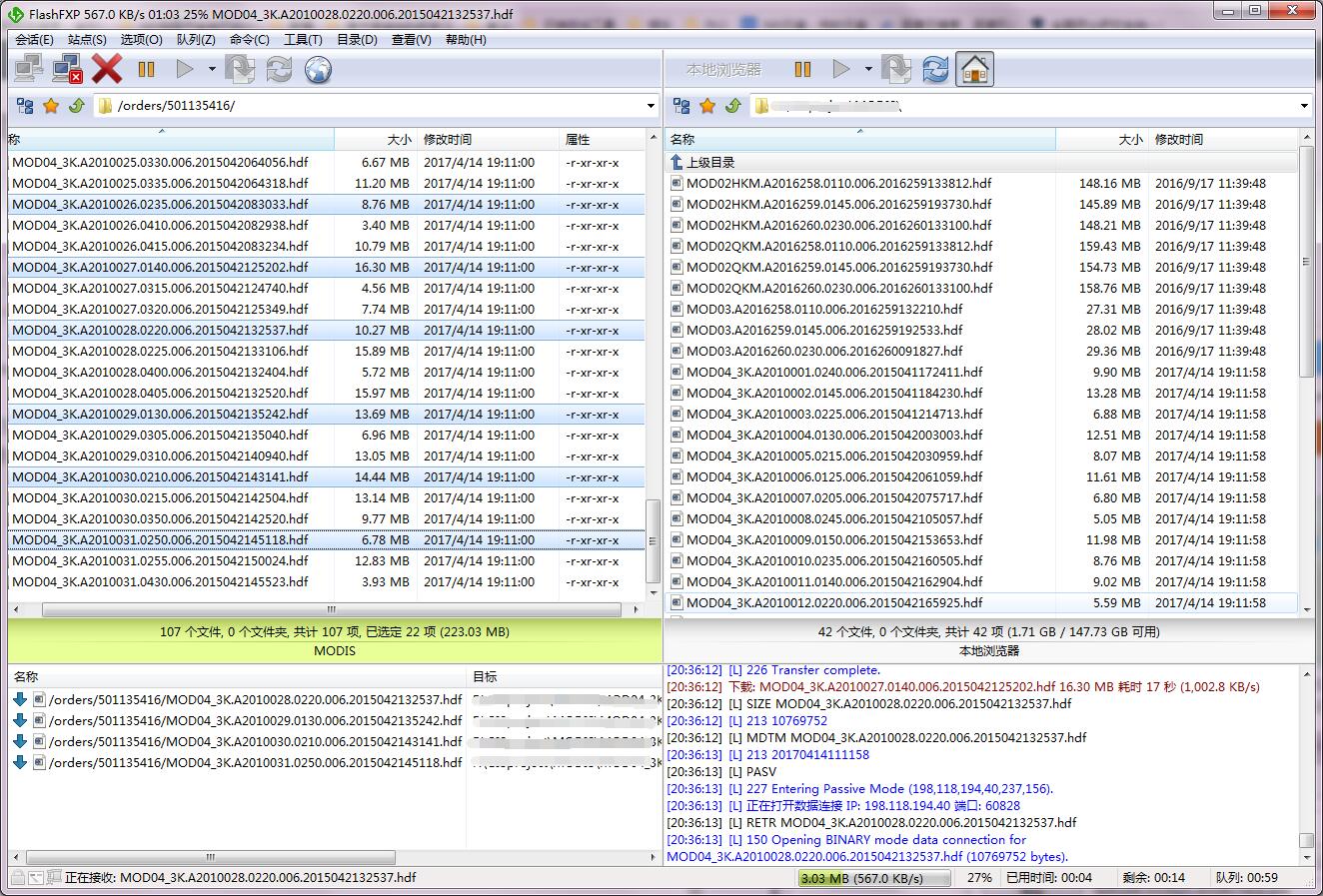
FTP的下载必须等到订单出现availlable,才能下载。官方给出的等待时间是5min到10天左右。一般很快就OK了。
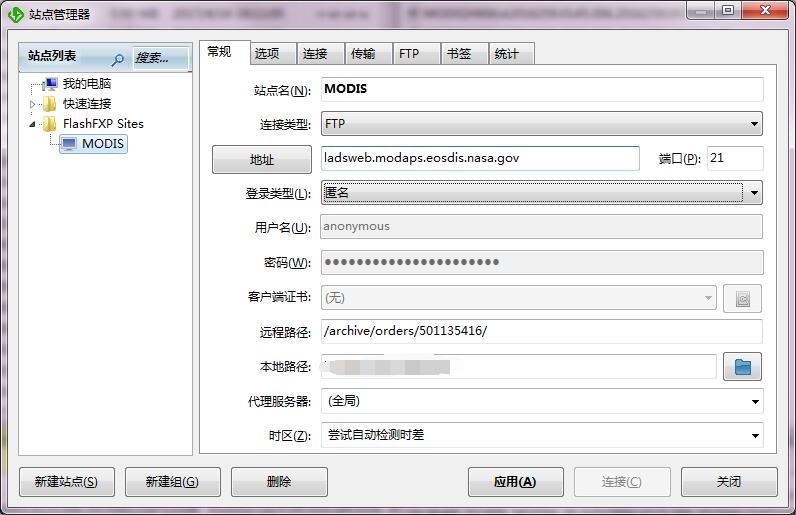
FTP下载方式的话,需要用FlashFXP这类软件来下载,有需要这个软件的可以在评论区留邮箱。


地址根据你的订单来决定。
ftp: ladsweb.modaps.eosdis.nasa.gov
username:anoymous
password:你账户申请用的邮箱(gmail邮箱)
anoymous意为FTP里的匿名传输。接下来只需要简单地拖拽就可以将上面的数据拷贝到本地文件夹了。
这就是关于MODIS数据下载方式(FTP)的内容。
最后附上旧版网站下载方式教程博客网址:
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/139166.html原文链接:https://javaforall.net


