
大家好,又见面了,我是你们的朋友全栈君。
python爬取豆瓣电影榜单
python爬取豆瓣电影榜单并保存到本地excel中,以后就不愁没片看了。
目标
确定我们想要抓取的电影的相关内容。
- 抓取豆瓣top250电影的排名、电影名、评价(总结很到位)、评分、点评人数及电影的豆瓣页面。
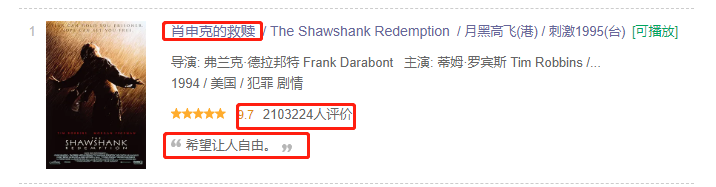

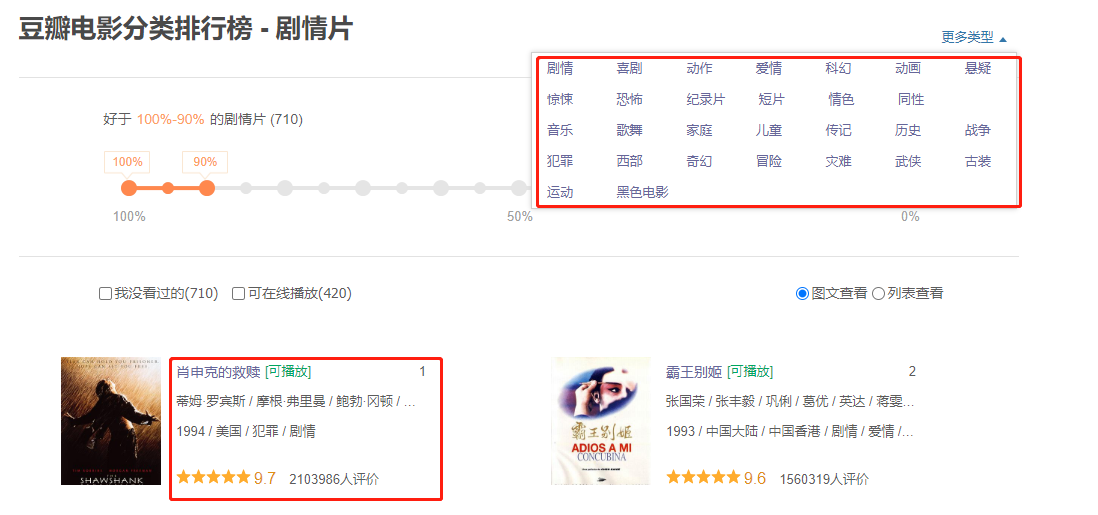
- 抓取各种电影类型的排行榜前100。
编码
省略需求到编码中间的繁文缛节,直接上手编码。(此处是最终编码)
目标一使用BeautifulSoup解析页面查找元素。
目标二调用接口处理返回的json数据。
import requests
import openpyxl
import json
from bs4 import BeautifulSoup
from openpyxl.styles import Color, Font, Alignment
class DouBanMovieList1():
def __init__(self):
self.path = r'D:\Download\豆瓣电影榜单\豆瓣电影.xlsx'
def get_moviedata(self):
data = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
for i in range(10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i*25)
response = requests.get(url=url, headers=headers)
bs = BeautifulSoup(response.text, 'lxml')
ranks = bs.select('em')
titles = bs.find_all('div', class_='hd')
evaluations = []
for j in range(1, 26):
if bs.select_one('#content > div > div.article > ol > li:nth-child(%d) > div > div.info > div.bd > p.quote > span'%(j)):
evaluations.append(bs.select_one('#content > div > div.article > ol > li:nth-child(%d) > div > div.info > div.bd > p.quote > span'%(j)).get_text())
else:
evaluations.append('')
ratings = bs.find_all('span', class_='rating_num')
evaluation_numbers = bs.find_all('div', class_='star')
links = bs.select('ol li div a')
for rank, title, evaluation, rating, evaluation_number, link in zip(ranks, titles, evaluations, ratings, evaluation_numbers, links):
data.append([rank.get_text(), title.get_text().split('\n')[2], evaluation, rating.get_text().strip(), evaluation_number.get_text().split('\n')[4].strip('人评价'), link.get('href')])
return data
def create_excel(self):
wb = openpyxl.Workbook()
ws = wb.active
ws.title = '综合'
font_kai = Font(name='楷体', bold=True)
align_center = Alignment(horizontal='center', vertical='center')
ws.cell(1, 1).value = '豆瓣综合电影榜单250'
ws.cell(1, 1).font = font_kai
ws.cell(1, 1).alignment = align_center
labels = ['排行', '电影', '评价', '评分', '评分人数', '豆瓣链接', '看过']
for i in range(1, len(labels)+1):
ws.cell(2, i).value = labels[i-1]
ws.cell(2, i).font = font_kai
ws.cell(2, i).alignment = align_center
ws.merge_cells('A1:G1')
wb.save(self.path)
def write_excel(self, data):
wb = openpyxl.load_workbook(self.path)
ws = wb['综合']
font_song = Font(name='宋体')
align_center = Alignment(horizontal='center', vertical='center')
row = 3
for i in data:
for column in range(len(i)):
ws.cell(row, column+1).value = i[column]
ws.cell(row, column+1).font = font_song
ws.cell(row, column+1).alignment = align_center
row += 1
ws.column_dimensions['A'].width = 6.0
ws.column_dimensions['B'].width = 20.0
ws.column_dimensions['C'].width = 75.0
ws.column_dimensions['D'].width = 6.0
ws.column_dimensions['E'].width = 10.0
ws.column_dimensions['F'].width = 45.0
ws.column_dimensions['G'].width = 7.0
wb.save(self.path)
class DouBanMovieList2():
def __init__(self):
self.path = r'D:\Download\豆瓣电影榜单\豆瓣电影.xlsx'
self.type_dict = {
11: '剧情', 24: '喜剧', 5: '动作', 13: '爱情', 17: '科幻', 25: '动画', 10: '悬疑', 19: '惊悚', 20: '恐怖',
1: '记录片', 23: '短片', 6: '情色', 26: '同性', 14: '音乐', 7: '歌舞', 28: '家庭', 8: '儿童', 2: '传记',
4: '历史', 22: '战争', 3: '犯罪', 27: '西部', 16: '奇幻', 15: '冒险', 12: '灾难', 29: '武侠', 30: '古装',
18: '运动', 31: '黑色电影'}
def create_excel(self, type, sheetnumber):
wb = openpyxl.load_workbook(self.path)
ws = wb.create_sheet(type, sheetnumber)
font_kai = Font(name='楷体', bold=True)
align_center = Alignment(horizontal='center', vertical='center')
ws.cell(1, 1).value = '豆瓣{}电影榜单100'.format(type)
ws.cell(1, 1).font = font_kai
ws.cell(1, 1).alignment = align_center
labels = ['排行', '电影', '评分', '评分人数', '国家', '日期', '演员', '豆瓣链接', '看过']
for i in range(1, len(labels)+1):
ws.cell(2, i).value = labels[i-1]
ws.cell(2, i).font = font_kai
ws.cell(2, i).alignment = align_center
ws.merge_cells('A1:I1')
wb.save(self.path)
def get_moviedata(self, type_num):
data = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
number = 0
for i in range(10, 1, -1):
url = 'https://movie.douban.com/j/chart/top_list?type={}&interval_id={}%3A{}&action=&start=0&limit=100'.format(type_num, 10*i, 10*(i-1))
response = requests.get(url=url, headers=headers)
for movie in json.loads(response.text):
if [movie['rank'], movie['title'], movie['score'], movie['vote_count'], '&'.join(movie['regions']), movie['release_date'], '/'.join(movie['actors']), movie['url']] not in data:
data.append([movie['rank'], movie['title'], movie['score'], movie['vote_count'], '&'.join(movie['regions']), movie['release_date'], '/'.join(movie['actors']), movie['url']])
if len(data) == 100:
break
elif len(data) > 100:
data = data[0:100]
break
else:
pass
return data
def write_excel(self, type, data):
wb = openpyxl.load_workbook(self.path)
ws = wb[type]
font_song = Font(name='宋体')
align_center = Alignment(horizontal='center', vertical='center')
align_left = Alignment(horizontal='left', vertical='center')
row = 3
for i in data:
for column in range(len(i)):
ws.cell(row, column + 1).value = i[column]
ws.cell(row, column + 1).font = font_song
if column == 4 or column == 6:
ws.cell(row, column + 1).alignment = align_left
else:
ws.cell(row, column + 1).alignment = align_center
row += 1
ws.column_dimensions['A'].width = 6.0
ws.column_dimensions['B'].width = 20.0
ws.column_dimensions['C'].width = 6.0
ws.column_dimensions['D'].width = 10.0
ws.column_dimensions['E'].width = 15.0
ws.column_dimensions['F'].width = 12.0
ws.column_dimensions['G'].width = 35.0
ws.column_dimensions['H'].width = 45.0
ws.column_dimensions['I'].width = 7.0
wb.save(self.path)
if __name__ == '__main__':
movie1 = DouBanMovieList1()
movie1.create_excel()
data = movie1.get_moviedata()
movie1.write_excel(data)
movie2 = DouBanMovieList2()
sheetnumber = 1
for type_num in movie2.type_dict.keys():
type = movie2.type_dict[type_num]
movie2.create_excel(type, sheetnumber)
data = movie2.get_moviedata(type_num)
movie2.write_excel(type, data)
sheetnumber += 1
填坑
需求没分析清楚就直接编码,这种情况不用想直接填坑就行了(坑不是宝儿姐挖的)。
1、说好的top250,为什么不足250?
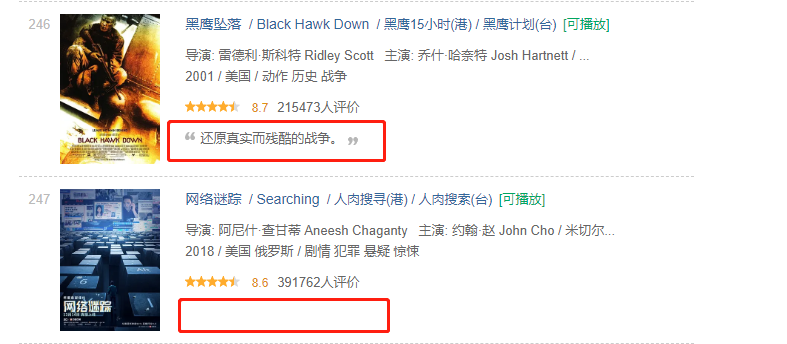
比如这种数据没有评价,是一条不完整的数据;因为代码中使用了zip函数,而zip函数返回列表长度与最短的对象相同,所以每有一条不完整的数据,结果就会少一条数据。
2、说好的榜单100,为什么不足100?
刚开始使用的是https://movie.douban.com/j/chart/top_list?type=26&interval_id=100%3A90&action=&start=0&limit=100这个接口,如果在100-90区间段里的电影不少于100就不会出错,但少于100的话,结果就会不足100。
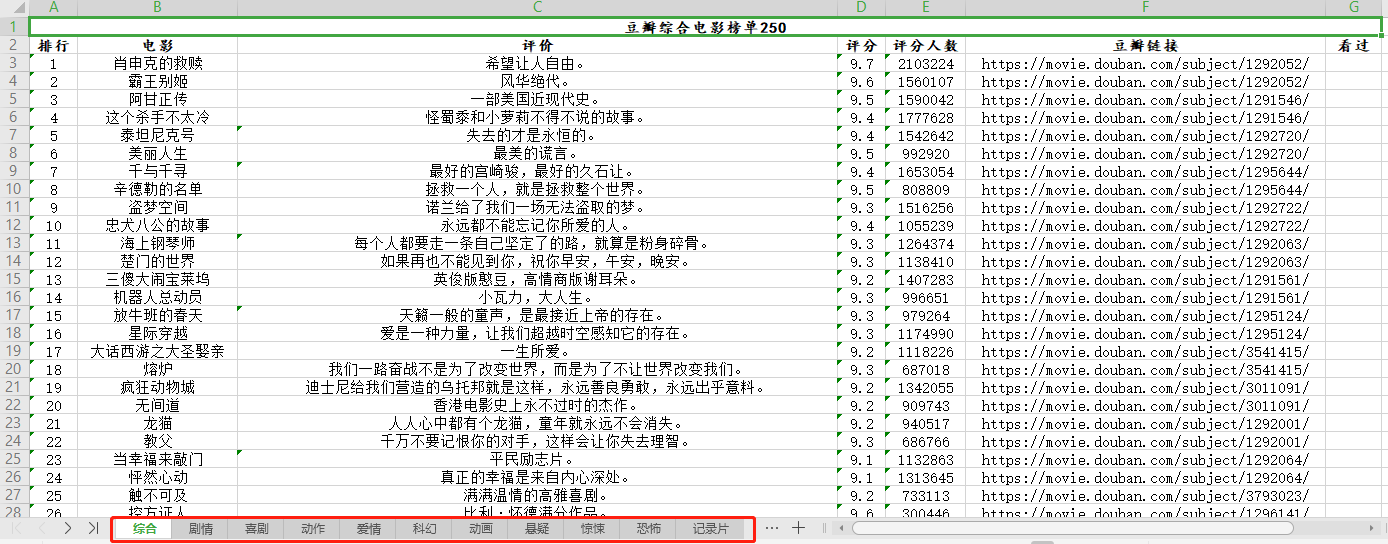
结果
以后每看一部就可以在后面“看过”那一列打✔了。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/140274.html原文链接:https://javaforall.net


