
大家好,又见面了,我是你们的朋友全栈君。
写在前面:之前我对于groupby一直都小看了,而且感觉理解得不彻底,虽然在另外一篇文章中也提到groupby的用法,但是这篇文章想着重地分析一下,并能从自己的角度分析一下groupby这个好东西~
OUTLINE
- 根据表本身的某一列或多列内容进行分组聚合
- 通过字典或者Series进行分组
根据表本身的某一列或多列内容进行分组聚合
这个是groupby的最常见操作,根据某一列的内容分为不同的维度进行拆解,将同一维度的再进行聚合
- 按一列进行聚合
import pandas as pd
import numpy as np
df = pd.DataFrame({
'key1':list('aabba'),
'key2': ['one','two','one','two','one'],
'data1': np.random.randn(5),
'data2': np.random.randn(5)})
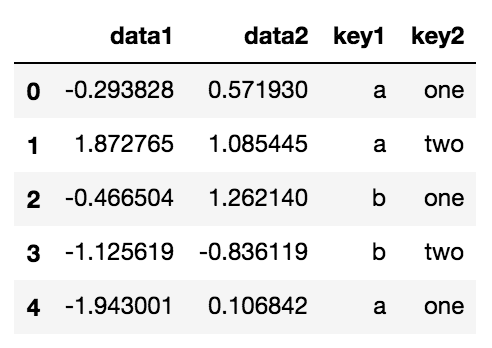
for i in df.groupby('key1'):
print(i)
# 输出:
('a', data1 data2 key1 key2
0 -0.293828 0.571930 a one
1 1.872765 1.085445 a two
4 -1.943001 0.106842 a one)
('b', data1 data2 key1 key2
2 -0.466504 1.262140 b one
3 -1.125619 -0.836119 b two)- 按多列进行聚合,则看的是多列之间维度的笛卡尔积
比如按照key1列,可以分为a和b两个维度,按照key2列可以分为one和two两个维度,最后groupby这两列之后的结果就是四个group。
for i in df.groupby(['key1','key2']):
print(i)
# 输出:
(('a', 'one'), data1 data2 key1 key2
0 -0.293828 0.571930 a one
4 -1.943001 0.106842 a one)
(('a', 'two'), data1 data2 key1 key2
1 1.872765 1.085445 a two)
(('b', 'one'), data1 data2 key1 key2
2 -0.466504 1.26214 b one)
(('b', 'two'), data1 data2 key1 key2
3 -1.125619 -0.836119 b two)通过字典或者Series进行分组
问题情境:一共有5个同学分别对5样东西做了一个评价,0-5表示对该物品的喜爱程度,随着数值的升高,程度也在不断加深。
import pandas as pd
import numpy as np
import random
people=pd.DataFrame(
np.random.randint(low=0,high=6,size=(5,5)),
columns=['香蕉','苹果','橘子','眼影','眼线'],
index=['Joe','Steve','Wes','Jim','Travis']
)
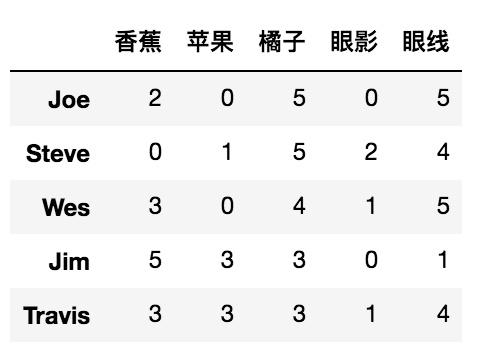
但是可以明显发现这五样物品可以分为两类:“水果”和“化妆品”。
问题:我想知道这五名同学对水果和化妆品的平均喜爱程度是什么样的?
solution1:通过字典分组
mapping = {
'香蕉':'水果','苹果':'水果','橘子':'水果','眼影':'化妆品','眼线':'化妆品'}
data = people.groupby(mapping,axis=1).mean()
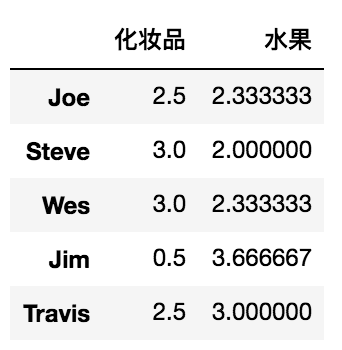
solution2:通过Series分组
mapping2 = pd.Series(mapping)
# mapping2
橘子 水果
眼影 化妆品
眼线 化妆品
苹果 水果
香蕉 水果
dtype: object之后将Series传入
data2 = people.groupby(mapping2,axis=1).mean()无论solution1还是2,本质上,都是找index(Series)或者key(字典)与数据表本身的行或者列之间的对应关系,在groupby之后所使用的聚合函数都是对每个group的操作,聚合函数操作完之后,再将其合并到一个DataFrame中,每一个group最后都变成了一列(或者一行)。
另外一个我容易忽略的点就是,在groupby之后,可以接很多很有意思的函数,apply/transform/其他统计函数等等,都要用起来!
彩蛋~
意外发现这两种不同的语法格式在jupyter notebook上结果是一样的,但是形式有些微区别
df.groupby(['key1','key2'])[['data2']].mean()

df.groupby(['key1','key2'])['data2'].mean()

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/141349.html原文链接:https://javaforall.net


