
大家好,又见面了,我是你们的朋友全栈君。
分组后按照分组规则拼接字符串
cla代表学生学习的课程,num代表该学生学习该门课程的次数。
建表语句:
create table st(
id int,
name varchar(50),
cla varchar(50),
num int
);
插入数据:
insert into st values(1,'张三','高数',3);
insert into st values(1,'张三','大学物理',2);
insert into st values(1,'张三','计量经济学',3);
insert into st values(2,'李四四','高数',2);
insert into st values(2,'李四四','计量经济学',4);
insert into st values(3,'王五','高数',3);
insert into st values(3,'王五','大学物理',3);
原表数据:


group by的使用
查询出学习次数的总和
按id或name分类,查询num字段的总和
查询结果如图:
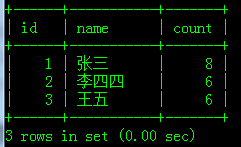
sql语句如下:
select
id,
name,
sum(num) count
from st
group by id,name;
或者
select
id,
max(name) name,
sum(num) count
from st
group by id;
还有个恶心的:
select
s1.id id,
s1.name name,
s2.count1
from st s1
join (select id,sum(num) count1 from st group by id ) s2
on s1.id=s2.id
where s1.id in (select id from st group by id)
group by id,name;
(这篇文章是2018-08-10 09:32:37写的,我2021年5月13日 10点37分看了一下,上面这个sql写的什么玩意。。。日常工作和面试什么的,非常不建议使用这种写法)
group_concat() 的使用
查询学生学习次数的总和以及学习课程
按id或name分类,查询num的总和,同时显示所有的cla
查询结果如图:

要达到这种效果,需要用到group_concat() :
1、功能:将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
2、语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator ‘分隔符’] )
sql如下:
SELECT
id,
name,
group_concat(cla separator '-') cla,
sum(num) num
FROM st
GROUP BY id,name;
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/142725.html原文链接:https://javaforall.net


