
大家好,又见面了,我是你们的朋友全栈君。
扩容机制
什么时候需要扩容:
当hashmap中的元素个数超过数组大小 * loadFactor(负载因子)时,就会进行数组扩容,loadFactor的默认值(DEFAULT_LOAD_FACTOR)是0.75这是一个折中的取值,也就是说,默认情况下数组大小为16,那么当hashmap中的元素个数超过16*0.75 = 12 (阈值或者边界值的时候)就把数组的大小扩展为2 * 16 = 32,然后重新计算出每个元素在数组中的位置,而这是一个非常耗性能的操作,所以我们最好能够提前预知并设置元素的个数。
注意:
当hashmap中的其中一个链表的对象个数达到了8个,此时如果数组长度没有达到64,那么hashmap会先扩容解决,如果达到了64,就会变成红黑树,节点类型由Node变成TreeNode类型,当然如果映射关系被移除后,下次执行resize()方法时会判断树的节点个数低于6也会再把树转换为链表
什么是扩容:
-
进行扩容,会伴随着一次新的hash分配,并且会遍历hash表中所有的元素,是非常耗时的,在编写程序的过程中,要尽量避免resize()
-
每次扩容都是翻倍的与原来的 (n-1)& hash 结果相比,只是多了一个bit位,所以节点要么就在原来的位置,要么就会被分配到 “原位置+旧容量”这个位置


原数组长度 : 16 n = n - 1 ---> 15
(n - 1) & hash
0000 0000 0000 0000 0000 0000 0001 0000 16
0000 0000 0000 0000 0000 0000 0000 1111 15 n - 1
hash1 (key1):1111 1111 1111 1111 0000 1111 0000 0101
----------------------------------------------------------------
0000 0000 0000 0000 0000 0000 0000 1111 索引 5
0000 0000 0000 0000 0000 0000 0000 1111 15 n - 1
hash2 (key2):1111 1111 1111 1111 0000 1111 0000 0101
----------------------------------------------------------------
0000 0000 0000 0000 0000 0000 0000 1111 索引 5
================================================================
数组长度扩容 ——> 16 * 32 n - 1 ---> 31
(n - 1) & hash
0000 0000 0000 0000 0000 0000 0010 0000 32
0000 0000 0000 0000 0000 0000 0001 1111 31 n - 1
hash1(key1): 1111 1111 1111 1111 0000 1111 0000 0101
----------------------------------------------------------------
0000 0000 0000 0000 0000 0000 0000 0101 索引 5
0000 0000 0000 0000 0000 0000 0001 1111 31 n - 1
hash2 (key2):1111 1111 1111 1111 0000 1111 0000 0101
----------------------------------------------------------------
0000 0000 0000 0000 0000 0000 0001 0101 索引 5 + 16
因此元素在重新计算hash之后,因为N变为2倍,那么n-1的标记范围在高位多1bit 因此新的index就会发生这样的变化
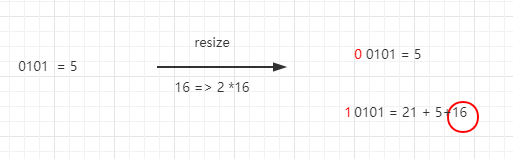
原位置 = 原位置 + oldCap
说明: 5是假设计算出来的原来的索引值,这样就验证了函数所描述的,扩容之后所以节点要么就在原来的位置,要么就是被分配到了‘原位置 +旧容量’位置
因此我们在扩容hashmap的时候,不需要重新计算hash值,只需要看看原来的hash值新增的那个bit是1还是0就可以了,
(0表示索引没有变化,1表示原索引 + 旧容量)
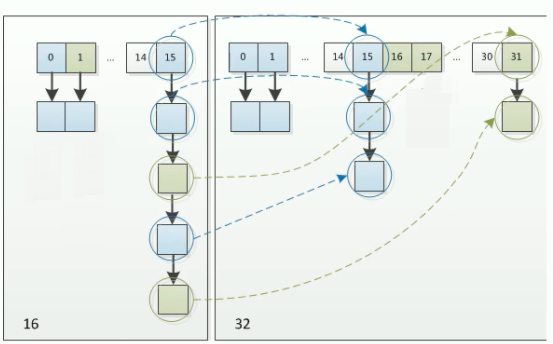
正是因为这种巧妙的rehash方式,既省去了重新计算hash值的时间,而且同时,由于新增的1bit 是 0还是1
这是随机的,在reszie的过程中保证了rehash之后的每个桶上的结点数一定小于等于原来桶上的节点数,保证了rehash之后不会出现更加严重的hash冲突,均匀的把之前的冲突的节点分散到新的桶中了。
初始化map注意:
HashMap 的扩容机制,就是当达到扩容条件时会进行扩容。HashMap 的扩容条件就是当 HashMap 中的元素个数(size)超过临界值(threshold)时就会自动扩容。所以,如果我们没有设置初始容量大小,随着元素的不断增加,HashMap 会有可能发生多次扩容,而 HashMap 中的扩容机制决定了每次扩容都需要重建 hash 表,是非常影响性能的。
关于设置 HashMap 的初始化容量大小:
可以认为,当我们明确知道 HashMap 中元素的个数的时候,把默认容量设置成 initialCapacity/ 0.75F + 1.0F 是一个在性能上相对好的选择,但是,同时也会牺牲些内存。
而 Jdk 并不会直接拿用户传进来的数字当做默认容量,而是会进行一番运算,最终得到一个 2 的幂。
实例:
-
initalCapacity = (需要存储的元素的个数 / 负载因子) + 1
-
负载因子默认是 0.75 ,建议暂时无法确定大小则一般设置为16
-
如果不一开始指定初始化因子。需要放置1024个元素的时候,随着元素的不断增加,就需要扩容7次,重新建立hash表,严重的影响性能。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/150159.html原文链接:https://javaforall.net


