
大家好,又见面了,我是你们的朋友全栈君。
一.使用步骤
1 //将一个字符串创建成token流,第一个参数---fiedName,是一种标志性参数,可以写空字符串,不建议用null,因为null对于IKAnalyzer会包错
2 TokenStream tokenStream = new IKAnalyzer().tokenStream("keywords",new StringReader("思想者")); 3 //添加单词信息到AttributeSource的map中
4 CharTermAttribute attribute = tokenStream.addAttribute(CharTermAttribute.class); 5 //重置,设置tokenstream的初始信息
6 tokenStream.reset(); 7 while(tokenStream.incrementToken()) {//判断是否还有下一个Token
8 System.out.println(attribute); 9 } 10 tokenStream.end(); 11 tokenStream.close();
二.代码与原理分析
TokenStream用于访问token(词汇,单词,最小的索引单位),可以看做token的迭代器
1.如何获得TokenStream流 —->对应第一行代码
先获得TokenStreamComponents,从他获得TokenStream(TokenStreamComponents内部封装了一个TokenStream以及一个Tokenizer,关于Tokenizer下面会具体讲)
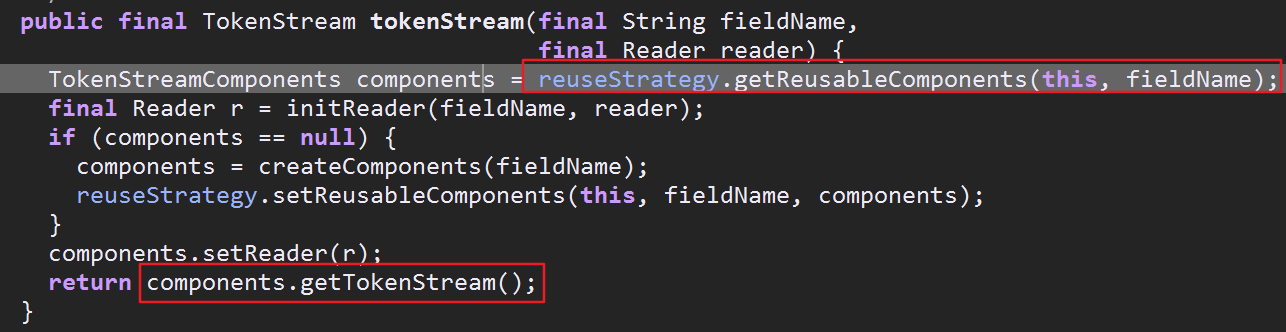

可以看到主要是通过reuseStrategy对象获得TokenStreamComponents,然后通过components对象获得所需的TokenStream流.reuseStrategy对象即为”复用策略对象”,但是如何获得此对象?
通过下面这两张图可以看到在Analyzer的构造器中通过传入GLOBAL_REUSE_STRATEGY对象完成了reuseStrategy对象的初始化.
ReuseStrategy是Analyzer的一个静态内部类,同时他也是一个抽象类,其子类也是Analyzer的内部类,上面提到了GLOBAL_REUSE_STRATEGY,这个对象是通过匿名类的方式继承了ReuseStrategy获得
的(第三张图)


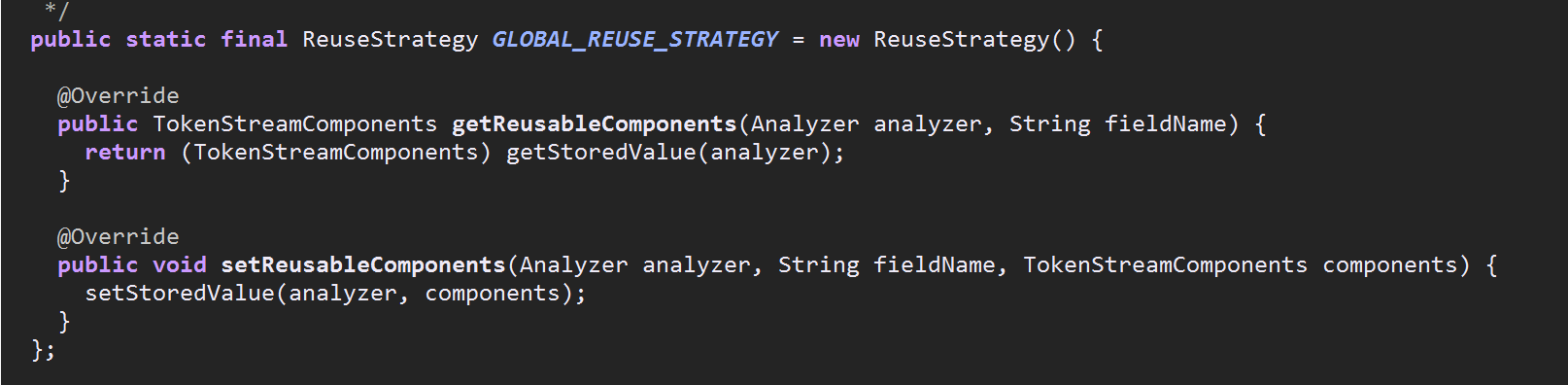
当然你会说Analyzer不是抽象类吗?他的构造器怎么被调用?因为我们用到的各种分词器,如IKAnalyzer,StandAnalyzer都是Analyzer的子类或间接子类,new一个分词器对象时会调用父类分词器的构造器
接下来就是 reuseStrategy.getReusableComponents(this, fieldName);通过上面的分析,发现调用的getReusableComponents方法就是调用GLOBAL_REUSE_STRATEGY对象里的getReusableComponents
这个方法又把我们传入的分词器对象传递给ReuseStrategy类里的getStoredValue方法,最后通过storedValue(老版本里叫做tokenStreams)获得TokenStreamComponents对象(储存在ThreadLocal中)
可以看到查找的时候根本没用到fieldname,这也是为什么说new xxxAnalyzer().tokenStream()时第一个参数filedname可以写空字符串的原因
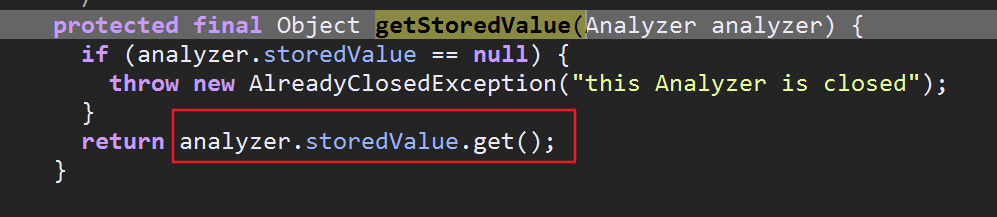
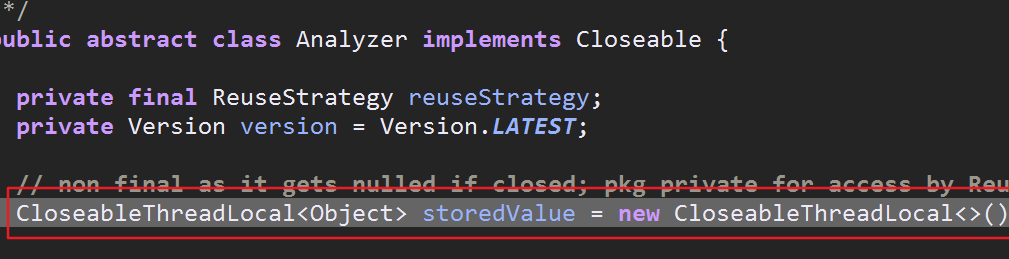
关于CloseableThreadLocal做个简略的说明:
CloseableThreadLocal是lucene对java自带的的ThreadLocal的优化,解决了jdk中定期执行无效对象回收的问题
请参考:https://www.cnblogs.com/jcli/p/talk_about_threadlocal.html
既然获得了TokenStreamComponents对象,接下来初始化Reader对象,事实上这个初始化就是把你传入的reader对象返回过来,


接着往下走判断components对象是否为空?为null则新创建一个components对象,Analyezer的createComponents是个抽象方法,我们以其子类IKAnalyzer中的此方法作为解析

这里又出现了一个新的类Tokenizer,Tokenizer说白了也是一个TokenStream,但是其input是一个Reader,这意味着Tokenizer是对字符操作,换句话说由Tokenizer来进行分词,即生成token
TokenStream还有一个重要的子类叫做TokenFilter,其input是TokenStream,也就是说他负责对token进行过滤,如去除标点,大小写转换等,从上面贴的IKAnalyzer的createComponents方法看不到TokenFilter的影子
贴下标准分词器里的代码
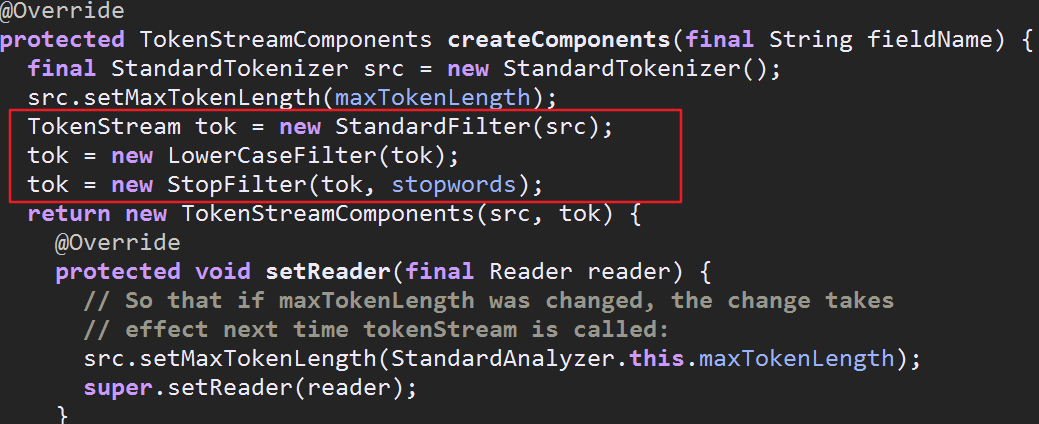
到这TokenStreamComponents对象创建完成了,大体的流程是先检查复用策略对象里有没有现成的components对象可用,有的话直接拿过来用,没有的话再去创建,创建完成
后加入复用策略对象里,以便下次使用.获得了TokenStreamComponents就可以获得TokenStream对象
组合不同的Tokenizer和TkoenFilter就变成了不同的Analyzer
2.AttributeImpl与AttributeSource ——–>对应第二行代码
AttributeImpl是Attribute接口的实现类,简单的说AttributeImpl用来存储token的属性,主要包括token的文本,位置,偏移量.位置增量等信息,比如CharTermAttribute保存文本
OffsetAttribute保存偏移量,PositionIncrementAttribute用于保存位置增量,而AttributeSource又包含了一系列的AttributeImpl,换句话说AttributeSource是token的属性集合,
AttributeSource内部有两个map.分别定义了从xxxAttribute—->AttributeImpl,xxxAttributeImpl—–>AttributeImpl两种映射关系,这样保证了xxxAttributeImpl对于同一个AttributeSource只有一个实例

所以需要什么信息,就用tokenStream.addAttribute(xxx.Class)即可
//添加单词信息到AttributeSource的两个map中
CharTermAttribute attribute = tokenStream.addAttribute(CharTermAttribute.class);
3.reset
lucene各个版本的API变化很大,网上好多的资料都有些过时了,比如 TokenStream contract violation: reset()/close() call missing这个异常是
因为在调用incrementToken()方法前没有调用reset()方法,一些老版本不需要调用,然而现在高版本的lucene必须先调用reset()把used属性设置为
false后才能执行incrementToken()
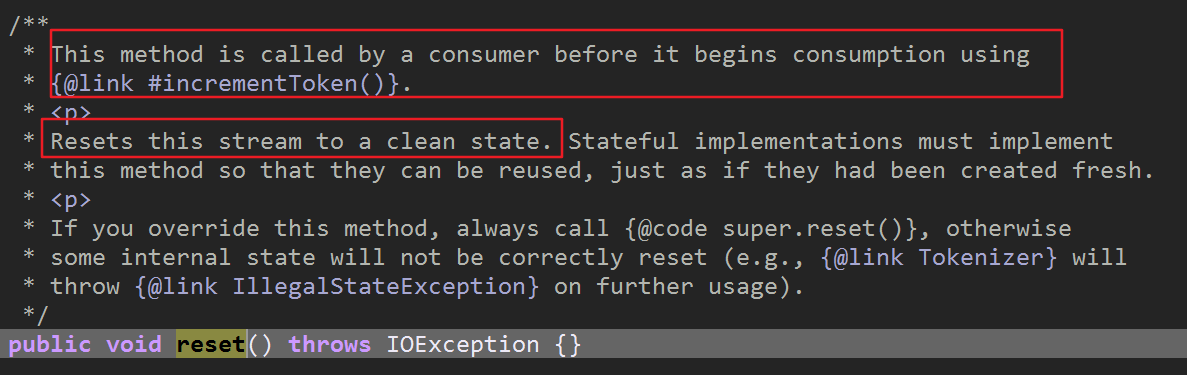
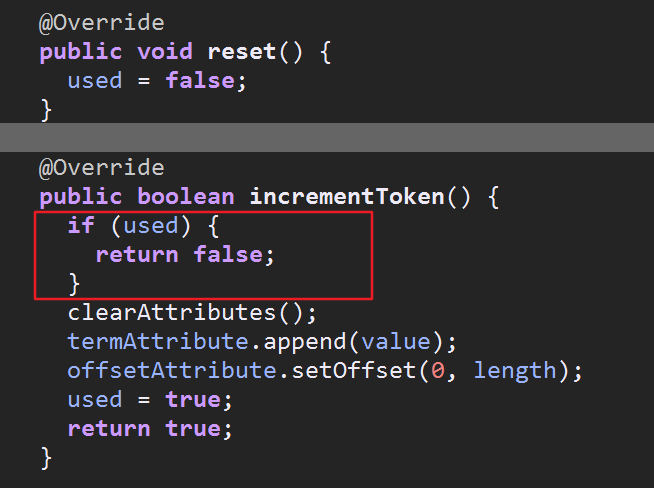
重置的目的是为了让告诉incrementToken(),此流未被使用过,要从流的开始处返回词汇
4.incrementToken()
是否还有下一个词汇
5.end()与close()
end()调用endAttribute(),把termlength设置为0,意思是没有词汇了为close()做准备
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/154984.html原文链接:https://javaforall.net

![ES[7.6.x]学习笔记(七)IK中文分词器](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
