
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
insert into太慢
insert into太慢?Roger 带你找真凶
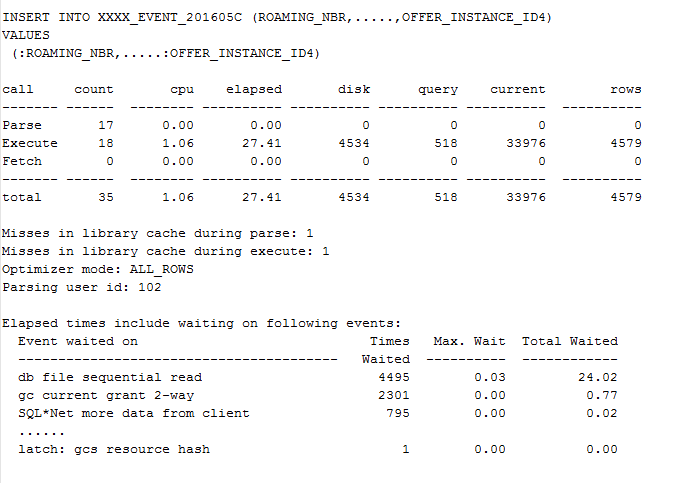
运营商客户的计费库反应其入库程序很慢,应用方通过监控程序发现主要慢在对于几个表的insert操作上。按照我们的通常理解,insert应该是极快的,为什么会很慢呢?而且反应之前挺好的。这有点让我百思不得其解。通过检查event也并没有发现什么奇怪的地方,于是我通过10046 跟踪了应用的入库程序,如下应用方反应比较慢的表的insert操作,确实非常慢,如下所示:

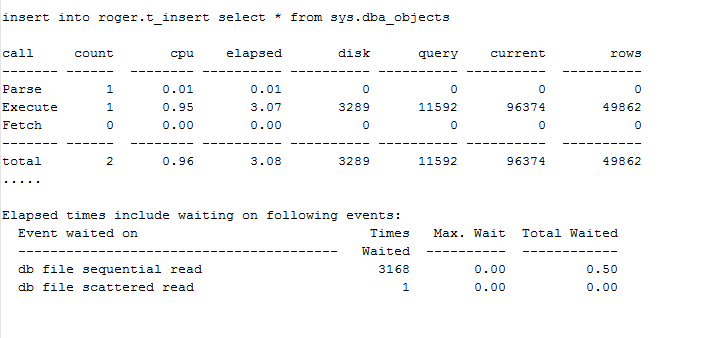
*我们可以发现,insert了4579条数据,一共花了27.41秒;其中有24.02秒是处于等待的状态。而且等待事件为顺序读.很明显这通常是索引的读取操作,实际上检查10046 trace 裸文件,发现等待的对象确实是该表上的2个index。
同时我们从上面10046 trace可以看出,该SQL执行之所以很慢,主要是因为存在了大量的物理读,其中4579条数据的insert,物理读为4534;这说明什么问题呢? 这说明,每插入一条数据大概产生一个物理读,而且都是index block的读取。很明显,通过将该index cache到keep 池可以解决该问题。 实际上也确实如此,通过cache后,应用反馈程序快了很多。
那么对该问题,这里其实有几个疑问,为什么这里的SQL insert时物理读如此之高? oracle的keep pool对于缓存对象的清理机制是如何的?
下面我们通过一个简单的实验来进行说明。
首先我们创建2个测试表,并创建好相应的index,如下所示:
创建表和索引并插入数据
从前面的信息我们可以看出,object_name上的index其实聚簇因子比较高,说明其数据分布比较离散。
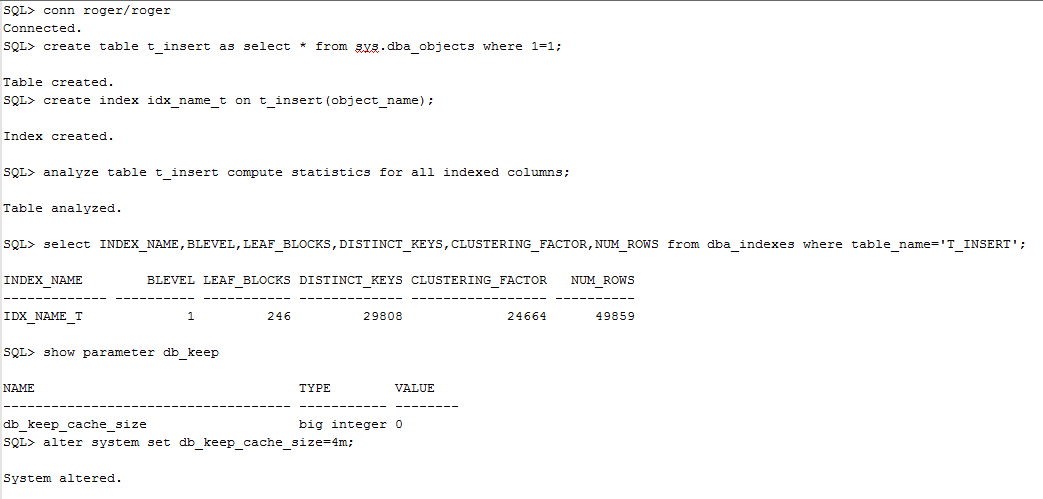

接着我们现在将index都cache 到keep 池中,如下:
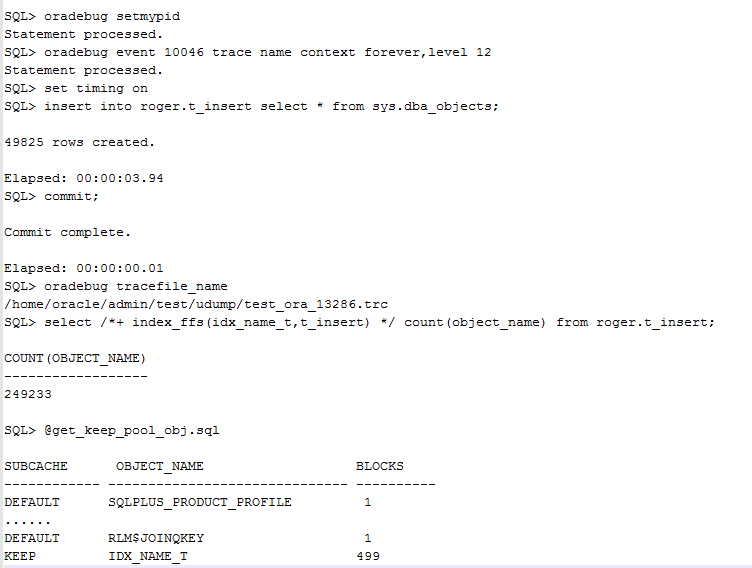
这里需要注意的是,仅仅执行alter 命令是不够的,我们还需要手工将index block读取到keep池中,如下:
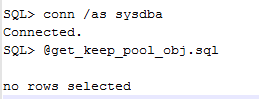
第一次读取并检查
第二次读取并检查
第三次读取并检查
我们可以大致看出,db keep pool 也是存在LRU的,而且对于block的清除机制是先进先出原则。那么为什么前面的问题中,insert会突然变慢呢?




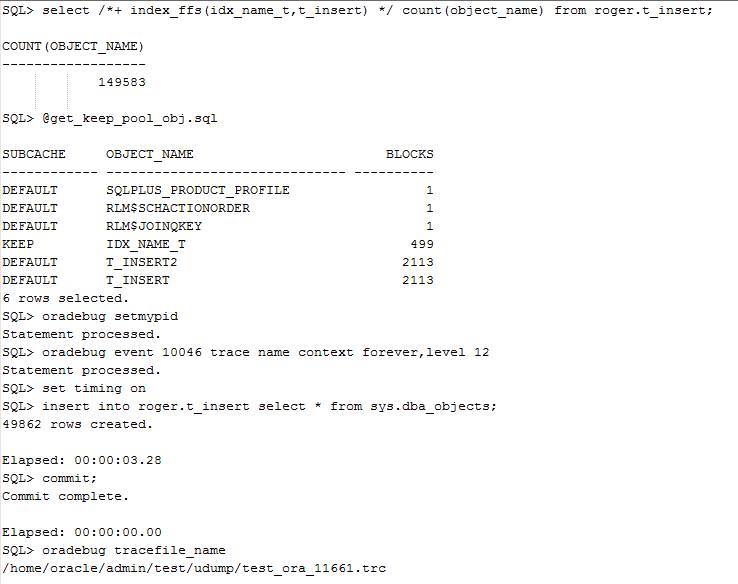
下面我们来进行3次insert 测试。
第一次
使用10046事件跟踪
第二次
第三次
使用10046事件跟踪
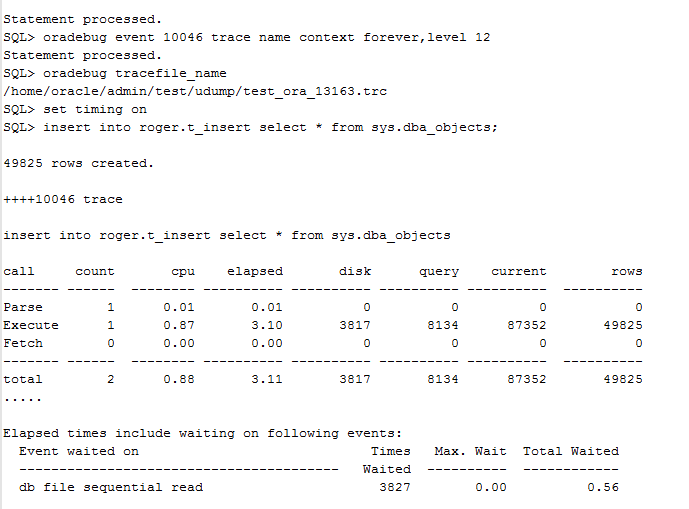
从测试来看,随着表的数据越来越大,insert的效率会越来越低,也其实主要在于index的问题。我们可以发现,3次测试过程中,物理读越来越大,而且db file sequential read的等待时间分别从0.5秒,增加到0.56秒,最后增加到1.07秒。 为什么会出现这样的情况呢?

随着表数据的日益增加,导致表上的index也不断增大,同时index的离散度比较高,这样就导致每次insert时,oracle在进行index block读取时,可能在buffer cache中都无法命中相应的block;这样就会导致每次读取需要的index block时,可能都要进行物理读,这势必会导致性能问题的出现。同时默认的default buffer cache pool虽然也可以缓存index 块,但是也要同时缓存其他的数据块,这样很容易导致相关的index block被从buffer cache pool中移走。所以这也是前面为什么需要将index cache到keep 池的原因。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/160951.html原文链接:https://javaforall.net

![矩阵向量中两两间欧式距离计算[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
