
大家好,又见面了,我是你们的朋友全栈君。
代码:package com.tan.code;
import java.io.IOException;
import java.io.StringReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
import org.apache.lucene.util.Version;
public class TokenStreamDetails {
public void tokeStrem(String text) throws IOException {
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_35);
StringReader reader = new StringReader(text);
TokenStream tokenStream = analyzer.tokenStream("", reader);
// 语汇单元对应的文本
CharTermAttribute charTermAttribute = tokenStream
.addAttribute(CharTermAttribute.class);
// 其实字符和终止字符的偏移量
OffsetAttribute offsetAttribute = tokenStream
.addAttribute(OffsetAttribute.class);
// 位置增量(默认为1)
PositionIncrementAttribute positionIncrementAttribute = tokenStream
.addAttribute(PositionIncrementAttribute.class);
// 语汇单元类型(默认为单词)
TypeAttribute typeAttribute = tokenStream
.addAttribute(TypeAttribute.class);
int position = 0;
// 递归处理所有语汇单元
while (tokenStream.incrementToken()) {
int increment = positionIncrementAttribute.getPositionIncrement();
if (increment > 0) {
// 计算位置信息
System.out.println("position:" + (position += increment));
}
// 打印所有语汇单元详细信息
System.out.println("【Trem:" + charTermAttribute.toString()
+ "】【StartOffset:" + offsetAttribute.startOffset()
+ "】【EndOffset:" + offsetAttribute.endOffset() + "】【Type:"
+ typeAttribute.type()+"】");
}
}
}
测试
@Test
public void testTokenStream() throws IOException {
TokenStreamDetails tokenStreamDetails = new TokenStreamDetails();
String text = "打印所有的TokenStream的詳細信息!Print the TokenStream Data";
tokenStreamDetails.tokeStrem(text);
}
输出:
position:1
【Trem:打】【StartOffset:0】【EndOffset:1】【Type:<IDEOGRAPHIC>】
position:2
【Trem:印】【StartOffset:1】【EndOffset:2】【Type:<IDEOGRAPHIC>】
position:3
【Trem:所】【StartOffset:2】【EndOffset:3】【Type:<IDEOGRAPHIC>】
position:4
【Trem:有】【StartOffset:3】【EndOffset:4】【Type:<IDEOGRAPHIC>】
position:5
【Trem:的】【StartOffset:4】【EndOffset:5】【Type:<IDEOGRAPHIC>】
position:6
【Trem:tokenstream】【StartOffset:5】【EndOffset:16】【Type:<ALPHANUM>】
position:7
【Trem:的】【StartOffset:16】【EndOffset:17】【Type:<IDEOGRAPHIC>】
position:8
【Trem:詳】【StartOffset:17】【EndOffset:18】【Type:<IDEOGRAPHIC>】
position:9
【Trem:細】【StartOffset:18】【EndOffset:19】【Type:<IDEOGRAPHIC>】
position:10
【Trem:信】【StartOffset:19】【EndOffset:20】【Type:<IDEOGRAPHIC>】
position:11
【Trem:息】【StartOffset:20】【EndOffset:21】【Type:<IDEOGRAPHIC>】
position:12
【Trem:print】【StartOffset:22】【EndOffset:27】【Type:<ALPHANUM>】
position:14
【Trem:tokenstream】【StartOffset:32】【EndOffset:43】【Type:<ALPHANUM>】
position:15
【Trem:data】【StartOffset:44】【EndOffset:48】【Type:<ALPHANUM>】
语汇单元的组成【截图】,其中各个属性的作用可以参考《Lucene In Action》:

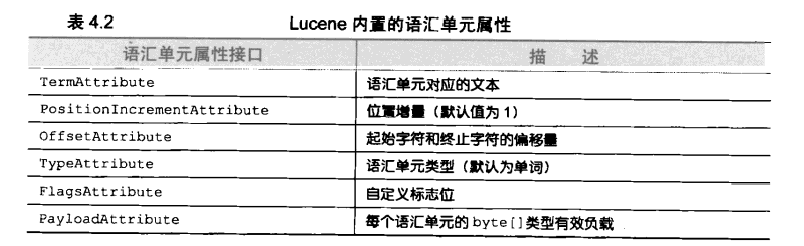
从代码示例中看到,可以通过调用addAttribute(class)来获取这些属性;使用tokenStream.incrementToken()递归访问所有的语汇单元,如果该方法到达下一个新的语汇单元则返回true,若已经对stream处理完毕则返回false。然后就可以与先前获取的属性对象进行交互得到针对每个语汇单元的属性值。当incrementToken返回true时,其中所有的属性都会将内部状态修改为下一个语汇单元
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/163081.html原文链接:https://javaforall.net


