
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
Question
输入n,符合要求的序列为:第一个数为n,第二个数不大于n,从第三个数起小于前两个数的差的绝对值,后面以此类推。求有多少种序列?答案取模10000(数据:n最大为1000)
Sample
input:4 / output:7
input:5 / output:14
input:6 / output:26
Hint
n为4时有如下序列:
4 1
4 2
4 3
4 4
4 1 1
4 1 2
4 2 1
故共7种。
这是校赛的一道题,当时用朴素dfs暴力,最大只能算到n为30左右,再后面的便需要等很长很长时间,而这道题n最大为1000。赛后听说是记忆化搜索,便打算等有空再研究一番。时隔多月,终于重新看回这道题。试着用记忆化搜索搞,调试了蛮长时间,终于搞定,这时当n为1000时便可在2s内得出答案,但时限1s,依旧超时,所以还可以进一步的优化。下面结合这道题总结下记忆化搜索。
普通搜索的低效使得很多时候在数据比较大时会导致TLE,一个重要原因是其搜索过程中重复计算了重叠子问题。记忆化搜索以搜索的形式加上动态规划的思想,面对会有很多重复计算的问题时,在搜索过程中记录一些状态的答案,可以减少重复搜索量。记忆化搜索本质上是DP,它们都保存了中间结果,不同点是DP从下往上算,记忆化DFS因为是递归所以从上往下算。
记忆化搜索:
- 递归函数的结果以返回值形式存在,不能以全局变量或参数形式传递。
- 不依赖任何外部变量。
(根据以上两个要求把朴素暴搜dfs写出来后,添加个记忆化数组就ok了) - 记忆化数组一般初始化为-1。在每一状态搜索的开始进行判断,如果该状态已经计算过,则直接返回答案,否则正常搜索。
对于这道题,很明显前2个数共有n种情况,所以我们的dfs以前2个数为参数,搜当前状态有几种情况。可以发现,搜索过程种存在很多重叠子问题,比如n为5时,5 1 3→5 1 3 1→5 1 3 1 1,5 3 1→5 3 1 1,这里便存在重叠的子问题dfs(3,1),对于相同一组参数, dfs 返回值总是相同的 ,所以在前面已求出dfs(3,1)结果后把答案存储到记忆数组dp[3][1]中,后面再遇到直接调用记忆数组就可以了。
如果对记忆化搜索不熟练,可以先写出void型dfs,再转化为有返回值的dfs,最后再加个数组记录已经搜过的状态就是记忆化dfs了。
①void型朴素dfs,代码如下:
def dfs(f,s):
if abs(f-s)<2: return
for i in range(1,n):
if i<abs(f-s):
global num
num+=1
dfs(s,i)
else: return
num=0
while True :
n=int(input())
num=0
for i in range(1,n+1):
dfs(n,i)
print(num+n)
②改成“无需外部变量”的有返回值的朴素dfs,代码如下:
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
ll sum;
ll dfs(int f,int s)
{
if(abs(f-s)<2)return 0;
ll num=0; //注意num不能是全局,必须是在函数内定义的局部变量
for(int i=1;i<abs(f-s);i++)
num+=dfs(s,i)+1;
/* 如果把上面这个for循环改换成下面这个,代码也是对的,但是却无法直接添加记忆化数组改 写成记忆化搜索,因为里面存在有一个外部变量sum for(int i=1;i<abs(f-s);i++){ num++; sum+=dfs(s,i); } */
return num;
}
int main()
{
int n;
while(~scanf("%d",&n)){
sum=0;
for(int i=1;i<=n;i++)
sum+=dfs(n,i);
printf("%lld\n",sum+n);
}
return 0;
}
上述代码dfs函数内的num变量必须在函数内定义ll num=0。如果是在全局定义ll num=0,dfs函数内改为num=0,则是错误的。
每递归调用一次函数,系统就会生成一个新的函数实例。这些函数实例有同名的参数和局部变量,但各自独立,互不干扰。流程执行到哪一层,那一层的变量就起作用,返回上一层,就释放掉低层的同名变量。这个需要深刻理解一下。
③记忆化dfs,添加个dp[f][s]数组记录当前两个数是f和s时有多少种序列,代码如下:
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const ll mod = 10000;
ll dp[1005][1005],sum;
ll dfs(int f,int s)
{
if(dp[f][s]!=-1)
return dp[f][s];
if(abs(f-s)<2)
return dp[f][s]=0;
ll num=0;
for(int i=1;i<abs(f-s);i++)
num+=dfs(s,i)+1;
return dp[f][s]=num; //返回num值前要把num值记录到记忆化数组
//若需取模则改为 return dp[f][s] = num % mod;
}
int main()
{
int n;
while(~scanf("%d",&n)){
sum=n;
memset(dp,-1,sizeof(dp));
for(int i=1;i<=n;i++)
sum+=dfs(n,i); //若需取模则 sum=(sum+dfs(n,i))%mod;
printf("%lld\n",sum);
}
return 0;
}
下面是对普通搜索和记忆化搜索的dfs函数调用次数进行对比:
(左图为记忆化dfs,右图为朴素dfs,答案均无取模)
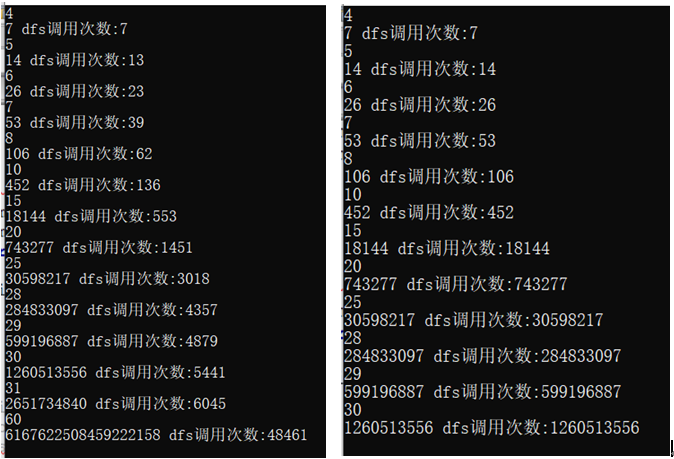

至此在时限1s内可计算到n为800,,对于n为1000,还可进一步优化。
④进一步优化
解空间是N的平方(详细为N*N)表格,但是每次都要循环加总,所以成了N的立方,在同样的解空间下,避免循环加总,即可优化到N的平方
重新考虑状态的转移:
如果我们用f(i,j)表示前一个数是i,当前数是1到j的合法序列的个数;有f(i,j) = 1 + f(i,j-1) + f(j,abs(i-j)-1)即分为两个部分1)i作为前一个数,从1到j-1为当前数的合法序列的个数已经计算好,2)求以j为尾数,后面选择1到abs(i-j)-1的合法序列的个数。
如 f(10,5)=f(10,4)+f(5,4);而不是枚举1到5;这样每次解答树只展开两个节点,相当于减少一层循环,虽然解答树的层次还是很深,但是由于记忆的存在,解空间仍然是N的平方。可在100ms内解决。——摘自https://blog.csdn.net/zhengwei223/article/details/105065435
#include<bits/stdc++.h>
typedef long long LL;
using namespace std;
const int MOD = 10000;
int mem[1001][1000];
int dfs(int pre, int cur) {
if (cur <= 0) return 0;
if (mem[pre][cur] != 0) return mem[pre][cur];
return mem[pre][cur] = (1 + dfs(pre, cur - 1) + dfs(cur, abs(pre - cur) - 1)) % MOD;
}
int main()
{
int N;
cin >> N;
cout << dfs(N, N) << endl;
return 0;
}
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/164455.html原文链接:https://javaforall.net


