
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
前言
python的使用者都知道Cpython解释器有一个弊端,真正执行时同一时间只会有一个线程执行,这是由于设计者当初设计的一个缺陷,里面有个叫GIL锁的,但他到底是什么?我们只知道因为他导致python使用多线程执行时,其实一直是单线程,但是原理却不知道,那么接下来我们就认识一下GIL锁
什么是GIL锁
GIL(Global Interpreter Lock)不是Python独有的特性,它只是在实现CPython(Python解释器)时,引入的一个概念。在官方网站中定义如下:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
由定义可知,GIL是一个互斥锁(mutex)。它阻止了多个线程同时执行Python字节码,毫无疑问,这降低了执行效率。理解GIL的必要性,需要了解CPython对于线程安全的内存管理机制。
CPython对线程安全的内存管理机制
Python使用引用计数来进行内存管理,在Python中创建的对象都会有引用计数,来记录有多少个指针指向它。当引用计数的值为0时,就会自动释放内存
我们来看一个小例子,来解释引用计数的原理
>>> import sys
>>> a = []
>>> b = a
>>> sys.getrefcount(a)
3
可以看到,a 的引用计数值为 3,因为有 a、b 和作为参数传递的 getrefcount 都引用了一个空列表。
如果有2个python线程同时引用a,那么2个线程都会尝试对其进行数据操作,多个线程同时对一个数据进行增加或减少的操作,如果发生这种情况,则可能导致内存泄漏
GIL锁的产生
由于多个线程同时对数据进行操作,会引发数据不一致,导致内存泄漏,我们可以对其进行加锁,所以Cpython就创建了GIL锁
但是既然有了锁,一个对象就需要一把锁,那么多个对象就会有多把锁,可能会给我们带来2个问题
- 1.死锁(线程之间互相争抢锁的资源)
- 2.反复获取和释放锁而导致性能降低。
为了保证单线程情况下python的正常执行和效率,GIL锁(单一锁)由此产生了,它添加了一个规则,即任何Python字节码的执行都需要获取解释器锁。这样可以防止死锁(因为只有一个锁),并且不会带来太多的性能开销。但这实际上使所有受CPU约束的Python程序(指的是CPU密集型程序)都是单线程的。
GIL锁的底层原理
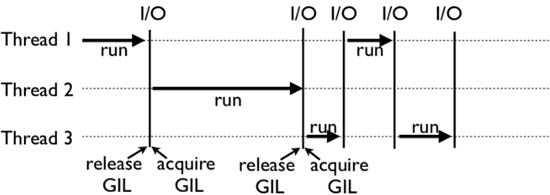

上面这张图,就是 GIL 在 Python 程序的工作示例。其中,Thread 1、2、3 轮流执行,每一个线程在开始执行时,都会锁住 GIL,以阻止别的线程执行;同样的,每一个线程执行完一段后,会释放 GIL,以允许别的线程开始利用资源。
线程释放GIL锁有两种情况,一是遇到IO操作,二是Time Tick到期。IO操作很好理解,比如发出一个http请求,等待响应。那么Time Tick到期是什么呢?Time Tick规定了线程的最长执行时间,超过时间后自动释放GIL锁。Python 3 以后,间隔时间大致为15毫秒。
虽然都是释放GIL锁,但这两种情况是不一样的。比如,Thread1遇到IO操作释放GIL,由Thread2和Thread3来竞争这个GIL锁,Thread1不再参与这次竞争。如果是Thread1因为Time Tick到期释放GIL(多数是CPU密集型任务),那么三个线程可以同时竞争这把GIL锁,可能出现Thread1在竞争中胜出,再次执行的情况。单核CPU下,这种情况不算特别糟糕。因为只有1个CPU,所以CPU的利用率是很高的。
在多核CPU下,由于GIL锁的全局特性,无法发挥多核的特性,GIL锁会使得多线程任务的效率大大降低。
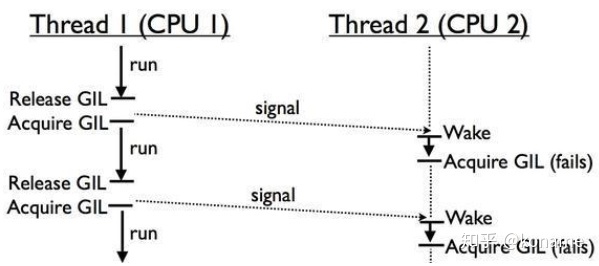
Thread1在CPU1上运行,Thread2在CPU2上运行。GIL是全局的,CPU2上的Thread2需要等待CPU1上的Thread1让出GIL锁,才有可能执行。如果在多次竞争中,Thread1都胜出,Thread2没有得到GIL锁,意味着CPU2一直是闲置的,无法发挥多核的优势。
为了避免同一线程霸占CPU,在python3.2版本之后,线程会自动的调整自己的优先级,使得多线程任务执行效率更高。
既然GIL降低了多核的效率,那保留它的目的是什么呢?这就和线程执行的安全有关。
Python GIL不能绝对保证线程安全
def add():
global n
for i in range(10**1000):
n = n +1
def sub():
global n
for i in range(10**1000):
n = n - 1
n = 0
import threading
a = threading.Thread(target=add,)
b = threading.Thread(target=sub,)
a.start()
b.start()
a.join()
b.join()
print n
上面的程序对n做了同样数量的加法和减法,那么n理论上是0。但运行程序,打印n,发现它不是0。问题出在哪里呢,问题在于python的每行代码不是原子化的操作。比如n = n+1这步,不是一次性执行的。如果去查看python编译后的字节码执行过程,可以看到如下结果。
19 LOAD_GLOBAL 1 (n)
22 LOAD_CONST 3 (1)
25 BINARY_ADD
26 STORE_GLOBAL 1 (n)
从过程可以看出,n = n +1 操作分成了四步完成。因此,n = n+1不是一个原子化操作。
- 1.加载全局变量n
- 2.加载常数1
- 3.进行二进制加法运算
- 4.将运算结果存入变量n。
根据前面的线程释放GIL锁原则,线程a执行这四步的过程中,有可能会让出GIL。如果这样,n=n+1的运算过程就被打乱了。最后的结果中,得到一个非零的n也就不足为奇。
总结
对于IO密集型应用,多线程的应用和多进程应用区别不大。即便有GIL存在,由于IO操作会导致GIL释放,其他线程能够获得执行权限。由于多线程的通讯成本低于多进程,因此偏向使用多线程。
对于计算密集型应用,由于CPU一直处于被占用状态,GIL锁直到规定时间才会释放,然后才会切换状态,导致多线程处于绝对的劣势,此时可以采用多进程+协程。
参考资料
https://realpython.com/python-gil/
https://zhuanlan.zhihu.com/p/97218985
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/165065.html原文链接:https://javaforall.net


