
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
什么是交叉验证?
它的基本思想就是将原始数据(dataset)进行分组,一部分做为训练集来训练模型,另一部分做为测试集来评价模型。
主要是用于小部分数据集中。通过图片可以看出,划分出来的测试集(test set)是不可以动的,因为模型参数的优化是使用验证集(validation set),这个结果是有偏差的,所以需要一个没见过的新数据集进行泛化能力测试。
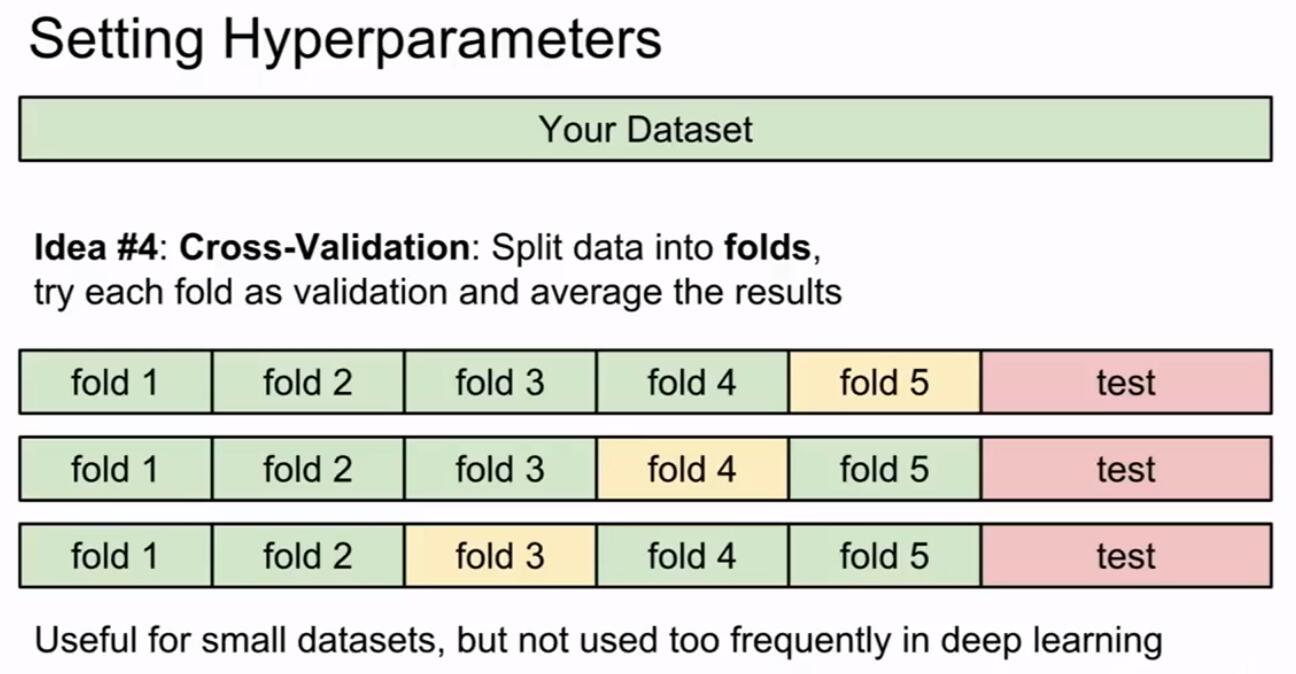

为什么用交叉验证法?
- 交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合。
- 还可以从有限的数据中获取尽可能多的有效信息。
交叉验证用途?
交叉验证(Cross Validation)是用来验证分类器的性能一种统计分析方法,基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集 (training set),另一部分做为验证集(validation set),当然还要留出测试集部分(test set),首先用训练集对分类器进行训练,在利用验证集来优化模型的超参数(hyperparameter),最后来使用测试集来测试模型的泛化能力。
- 可以用来选择模型
- 大致判断当前模型状态是否处于过拟合
- 交叉验证是一种评估统计分析、机器学习算法对独立于训练数据的数据集的泛化能力(generalize)。(过拟合的泛化能力差)
交叉验证的方法?
1. 留出法(holdout cross validation)
在机器学习任务中,拿到数据后,我们首先会将原始数据集分为三部分:训练集、验证集和测试集。
训练集用于训练模型,
验证集用于模型的参数选择配置,
测试集对于模型来说是未知数据,用于评估模型的泛化能力。
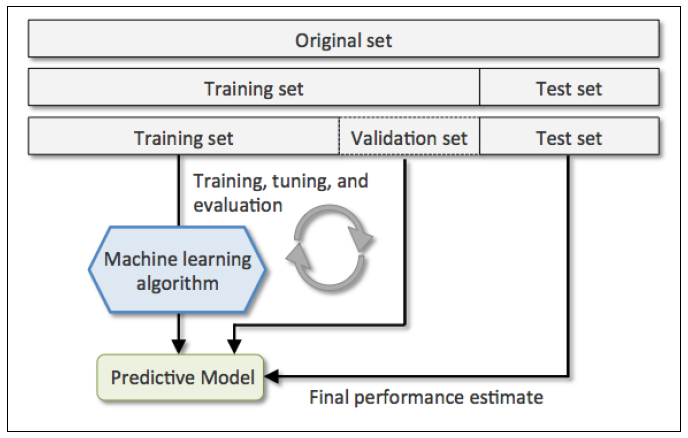
这个方法操作简单,只需随机把原始数据分为三组即可。
不过如果只做一次分割,它对训练集、验证集和测试集的样本数比例,还有分割后数据的分布是否和原始数据集的分布相同等因素比较敏感,不同的划分会得到不同的最优模型,而且分成三个集合后,用于训练的数据更少了。
2. k折交叉验证(k-fold cross validation)
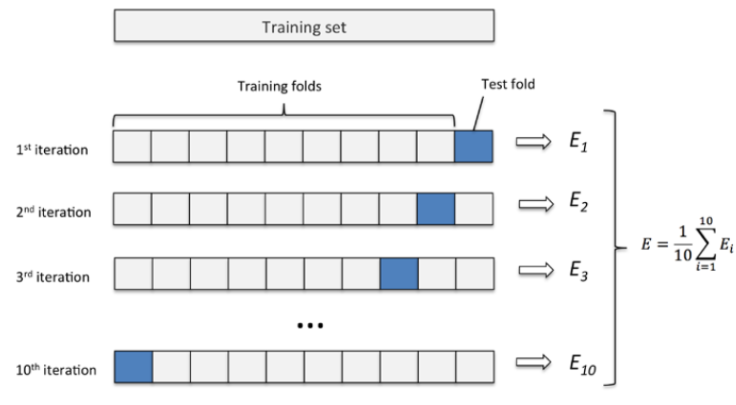
k折交叉验证是对留出法的改进,
k 折交叉验证通过对 k 个不同分组训练的结果进行平均来减少方差,因此模型的性能对数据的划分就不那么敏感。
- 第一步,不重复抽样将原始数据随机分为 k 份。
- 第二步,每一次挑选其中 1 份作为测试集,剩余 k-1 份作为训练集用于模型训练。
- 第三步,重复第二步 k 次,这样每个子集都有一次机会作为测试集,其余机会作为训练集。
- 在每个训练集上训练后得到一个模型,
- 用这个模型在相应的测试集上测试,计算并保存模型的评估指标,
- 第四步,计算 k 组测试结果的平均值作为模型精度的估计,并作为当前 k 折交叉验证下模型的性能指标。
k 一般取 10,
数据量小的时候,k 可以设大一点,这样训练集占整体比例就比较大,不过同时训练的模型个数也增多。
数据量大的时候,k 可以设小一点。
3.留一法(leave one out cross validation)
这个方法用于训练的数据只比整体数据集少了一个样本,因此最接近原始样本的分布。
但是训练复杂度增加了,因为模型的数量与原始数据样本数量相同。
一般在数据缺乏时使用。
此外:
- 多次 k 折交叉验证再求均值,例如:10 次 10 折交叉验证,以求更精确一点。
- 划分时有多种方法,例如对非平衡数据可以用分层采样,就是在每一份子集中都保持和原始数据集相同的类别比例。
- 模型训练过程的所有步骤,包括模型选择,特征选择等都是在单个折叠 fold 中独立执行的。
4.自助采样法(bootstrapping)
通过自助采样法,即在含有 m 个样本的数据集中,每次随机挑选一个样本,再放回到数据集中,再随机挑选一个样本,这样有放回地进行抽样 m 次,组成了新的数据集作为训练集。
这里会有重复多次的样本,也会有一次都没有出现的样本,原数据集中大概有 36.8% 的样本不会出现在新组数据集中。
优点是训练集的样本总数和原数据集一样都是 m,并且仍有约 1/3 的数据不被训练而可以作为测试集。
缺点是这样产生的训练集的数据分布和原数据集的不一样了,会引入估计偏差。
此种方法不是很常用,除非数据量真的很少。
具体实现
1. 留出法(holdout cross validation)
from sklearn import datasets from sklearn.model_selection import train_test_split iris = datasets.load_iris() X_trainval, X_test, y_trainval, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=0) X_train, X_val, y_train, y_val = train_test_split(X_trainval, y_trainval, test_size=0.2, random_state=0) # 数据集分布为:训练集0.64, 验证集0.16, 测试集0.2 print(X_train.shape, y_train.shape) print(X_val.shape, y_val.shape) print(X_test.shape, y_test.shape)
2. k折交叉验证(k-fold cross validation)
import numpy as np from sklearn.model_selection import KFold X = ["a", "b", "c", "d"] kf = KFold(n_splits=2) for train, test in kf.split(X): print("%s %s" % (train, test))
from sklearn.model_selection import cross_val_score # 可以通过修改模型参数,来选取最优参数组合 logreg = LogisticRegression() scores = cross_val_score(logreg,cancer.data, cancer.target) #cv:默认是3折交叉验证,可以修改cv=5,变成5折交叉验证。 print("Cross validation scores:{}".format(scores)) print("Mean cross validation score:{:2f}".format(scores.mean()))
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/168349.html原文链接:https://javaforall.net


