
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
Flask框架搭建
创建一个Flask框架
1、打开pycharm专业版,创建一个flask框架项目,如图:
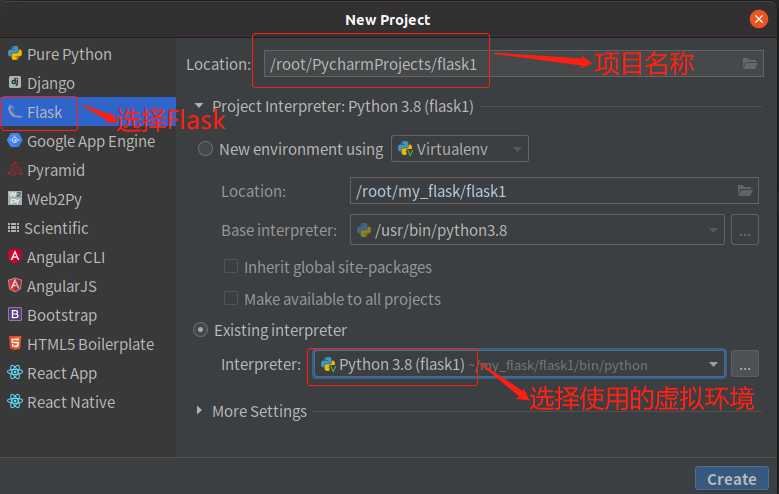

- 这里的虚拟环境是创建项目之前已经创建好的虚拟环境
2、点击创建按钮,跳转到项目主界面,如图:
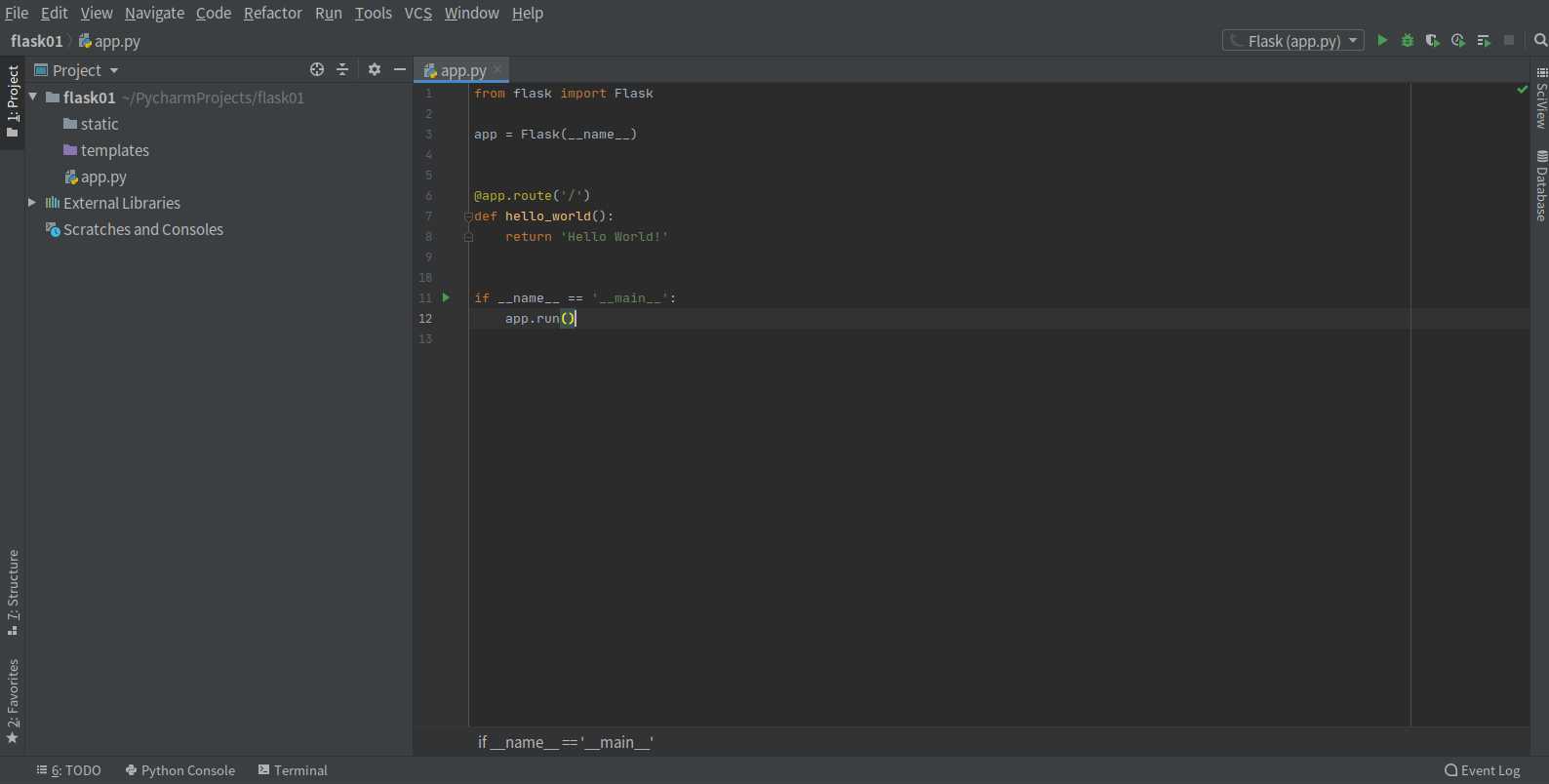
- 由上图可以看出项目的结构,如图:

解析一个应用程序
创建完成Flask项目,会自动生成一个应用程序,代码如下:
from flask import Flask
# 初始化Flask实例
app = Flask(__name__)
@app.route('/') # /就是指路由
def hello_world(): # 视图函数
return 'Hello World!' # 视图函数return接受的类型是string,dict,tuple,response对象,以及WSGI可调用类型的
if __name__ == '__main__':
app.run()
- 首先我们导入了 Flask 类。 该类的实例将会成为我们的 WSGI 应用。
- 接着我们创建一个该类的实例。第一个参数是应用模块或者包的名称。如果你使用 一个单一模块(就像本例),那么应当使用 name ,因为名称会根据这个 模块是按应用方式使用还是作为一个模块导入而发生变化(可能是 ‘main’ , 也可能是实际导入的名称)。这个参数是必需的,这样 Flask 才能知道在哪里可以 找到模板和静态文件等东西。更多内容详见 Flask 文档。
- 然后我们使用 route() 装饰器来告诉 Flask 触发函数的 URL 。
- 函数名称被用于生成相关联的 URL 。函数最后返回需要在用户浏览器中显示的信息。
把它保存为 hello.py 或其他类似名称。请不要使用 flask.py 作为应用名称,这会与 Flask 本身发生冲突。
WSGI是指Web服务器网关接口(Python Web Server Gateway Interface,缩写为WSGI)是为Python语言定义的Web服务器和Web应用程序或框架之间的一种简单而通用的接口
打开Terminal,使用python3 app.py命令来运行一下该应用程序,如下图:
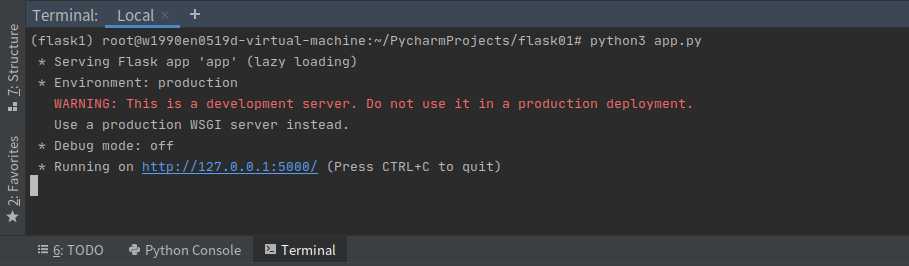
从运行的日志来看,这样就启动了一个非常简单的一个内建服务器,现在就可以打开浏览器访问http://127.0.0.1:5000/ ,界面上会出现Hello World! 字样。
该应用程序的请求过程和响应过程如下图:
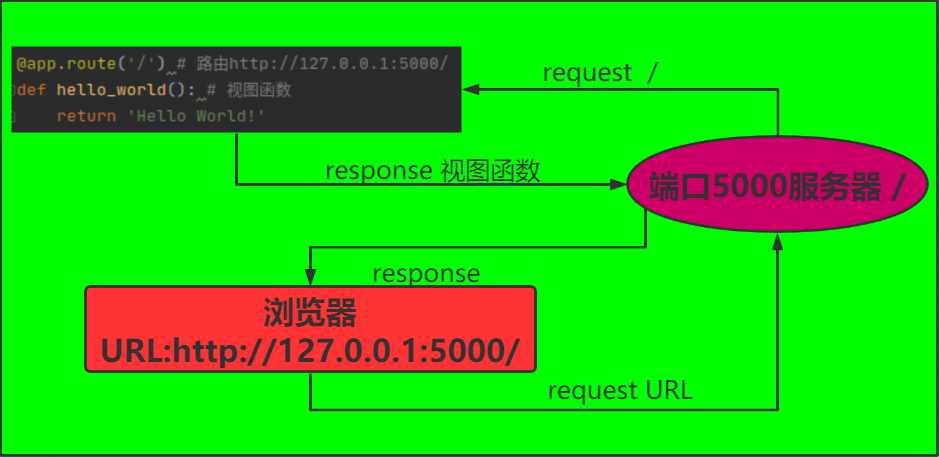
由上面的应用程序可以看出,默认情况下是只能访问本机的IP地址是http://127.0.0.1,端口号是5000,如果想使用自己电脑上的IP地址和其他端口号可以通过app.run(host='IP地址',port=端口号)进行配置,当然如果想设置服务器公开访问的话可以设置成app.run(host='0.0.0.0'),这样可以被所有人进行访问。
调试模式
虽然 flask 命令可以方便地启动一个本地开发服务器,但是每次应用代码修改之后都需要手动重启服务器。这样不是很方便, Flask 可以做得更好。如果你打开 调试模式,那么服务器会在修改应用代码之后自动重启,并且当应用出错时还会提供一个 有用的调试器。
由上面程序运行的日志不难看出Debug mode: off,默认是关闭的,无论你怎么修改代码,都必须重启服务器,才能去访问。如果不想重启服务器的情况下,边修改代码边调试的话,需开启debug的调试模式,通过app.run(debug=True)来设置成调试模式,设置完成之后必须重新启动服务器,你会发现debug模式变为on,如图:
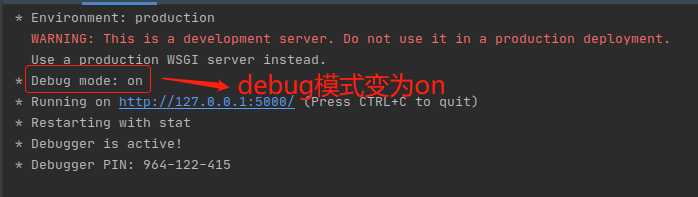
开启debug调试模式,只要你在修改代码的同时服务器会重新加载你的最新代码,便于调试,适用于开发环境(development),而debug=Flase或者默认的情况下,debug模式默认是关闭的,适用于生产环境(production)。
路由
什么是路由?路由就是指通过URL定位到的具体python类或者python函数的程序。路由是使用@app.route('/')来定义的,括号中的字符串/就是路由,也就是指使用 route() 装饰器来把函数绑定到 URL,如下面的定义两个路由:
@app.route('/')
def index():
return 'Index Page'
@app.route('/hello')
def hello():
return 'Hello, World'
比如说上面的两个路由,如果不指定host,那么默认访问本机的IP地址是127.0.0.1:5000,但是如果想要得到index的函数的返回值在页面显示,这就需要通过URL或者IP地址来寻找index的路径,也就是指index的路由/,这样才能得到Index Page,同样hello的函数的路由就是这/hello。
route()装饰器是通过底层add_url_rule函数来实现的,上面的两个路由可以写成,两种方式是等效的:
def index():
return 'Index Page'
app.add_url_rule('/',view_func=index)
def hello():
return 'Hello, World'
app.add_url_rule('/hello',view_func=hello)
路由变量规则
通过把 URL 的一部分标记为 <variable_name> 就可以在 URL 中添加变量。标记的部分会作为关键字参数传递给函数。通过使用<converter:variable_name> ,可以选择性的加上一个转换器,为变量指定规则。
变量器规则支持以下几种转换器类型:
| string | (缺省值) 接受任何不包含斜杠的文本 |
|---|---|
| int | 接受正整数 |
| float | 接受正浮点数 |
| path | 类似 string ,但可以包含斜杠 |
| uuid | 接受 UUID 字符串 |
示例如下:
@app.route('/index/<name>')# <name>是一个变量,默认是字符串类型
def index(name):# 参数是必须传递的
return '小明'
@app.route('/add/<int:num>')# <int:num>是一个变量,转换器类型是int类型
def multi(num):# 参数是必须传递的
num = num * 10
return str(num)
@app.route('/add/<float:num>')# <float:num>是一个变量,转换器类型是float类型
def add(num):# 参数是必须传递的
num = num + 0.5
return str(num)
@app.route('/index/<path:paths>') # <path:paths>是一个变量,转换器类型是path类型
def get_path(paths):# 参数是必须传递的
return paths
@app.route('/uid/<uuid:uid>')# <uuid:uid>是一个变量,转换器类型是uuid类型,uid必须传正确的uuid的格式的数据
def get_uid(uid):# 参数是必须传递的
return "获取唯一的标识码:"+ str(uid)
唯一的 URL / 重定向行为
重定向行为 / 唯一的 URL的不同之处在于是否使用尾部的斜杠,如下面两个视图函数:
@app.route('/projects/')# 重定向,路由中定义了/,无论请求的URL中是否带/,都可以执行视图函数,如果请求URL中没有带/,浏览器中就做了一次重定向
def projects():
return 'The project page'
@app.route('/about')# 唯一URL,请求路由的时候如果添加/:http://127.0.0.1:5000/about/,会显示Not Found
def about():
return 'The about page'
projects 的 URL 是中规中矩的,尾部有一个斜杠,看起来就如同一个文件夹。 访问一个没有斜杠结尾的 URL 时 Flask 会自动进行重定向,帮你在尾部加上一个斜杠。
about 的 URL 没有尾部斜杠,因此其行为表现与一个文件类似。如果访问这个 URL 时添加了尾部斜杠就会得到一个 404 错误。这样可以保持 URL 唯一,并帮助 搜索引擎避免重复索引同一页面。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/179760.html原文链接:https://javaforall.net


