
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
1 STN (Spatial Transformer Network)
1.1 来源
论文来源:https://arxiv.org/pdf/1506.02025.pdf


参考博客:
1. https://blog.csdn.net/ly244855983/article/details/80033788(论文解读)
2. https://blog.csdn.net/xbinworld/article/details/69049680 (梯度流动图)
3. https://blog.csdn.net/l691899397/article/details/53641485(这里有caffe代码分析)
1.2 动机
普通CNN能够显式学习到平移不变性,隐式学习到旋转不变性、伸缩/尺度不变性(通常学的不够好),但是attention机制的成功告诉我们,与其让网络自己隐式学习某个能力,不如为它显式设计某个模块,让它更容易学习到这个能力。
因此,设计STN的目的就是为了显式地赋予网络以上各项变换(transformation)的不变性(invariance)。
1.3 网络结构
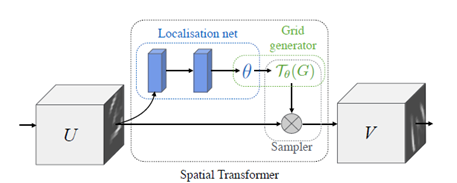
如上图所示,STN由Localisationnet(定位网络),Grid generator(网格生成器)和Sampler(采样器)三部分构成。
1. Localisation Net
Localisation Net 的目标是学习空间变换参数θ,无论通过全连接层还是卷积层,LocalisationNet 最后一层必须回归产生空间变换参数θ。
输入:特征图U ,其大小为 (H, W, C)
输出:空间变换参数θ(对于仿射变换来说,其大小为(6,))
结构:结构任意,比如卷积、全连接均可,但最后一层必须是regression layer来产生参数θ,记作θ= floc(U)
2. Grid Generator
该层利用LocalisationNet 输出的空间变换参数θ,将输入的特征图进行变换,这个决定了变换前后图片U、V之间的坐标映射关系。
以仿射变换为例,将输出特征图上某一位置(xit,yit)通过参数θ映射到输入特征图上某一位置(xis,yis),上标t表示target,上标s表示source,计算公式如下:
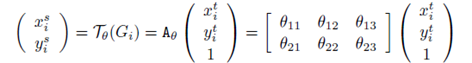
因此,GridGenerator的作用是,输入target坐标,计算输出source坐标,因为STN的目标是从source中的不同坐标采集灰度值“贴”到target中,从而实现target的变换。
举个例子,经过仿射变换,对原图产生了平移和旋转,使得原本倾斜的图片变正了,如下图所示:
3. Sampler
Sampler根据GridGenerator产生的坐标映射关系,把输入图片U变换成输出图片V。
在计算中, (xis,yis)往往会落在原始输入特征图的几个像素点中间,因此需要利用双线性插值来计算出对应该点的灰度值:
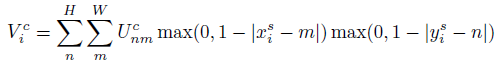
Unmc:是输入特征图U通道c中位置为 (n, m) 的灰度值。
Vic :是输出特征图V通道c中位置为 (xit, yit),即像素点i的灰度值。
论文中在变换时用都是标准化坐标,即xi,yi∈[−1,1]。
(双线性插值参考文献:https://zh.wikipedia.org/wiki/%E5%8F%8C%E7%BA%BF%E6%80%A7%E6%8F%92%E5%80%BC)
1.4 反向传播
Localisationnet、Grid generator、Sampler三者都是可微的,因此它们可以插入到正常的网络构架中,通过反向传播更新参数,无需额外的监督信息。
这里可以看一下反向的梯度流动:
1. Vic关于xis、yis的偏导,用于更新Localisationnet中的参数,注意这条梯度支流传递到Localisation net就结束了。
2. Vic关于Unmc的偏导,这是整个网络梯度向前传递的流动。
(缺图)
原论文中还给出了Sampler的反向求导公式,即Vic关于xis、yis的偏导、Vic关于Unmc的偏导,在此就不展开介绍。
1.5 优势
STN的主要特点:
1. 模块化:STN可以插入到现有深度学习网络结构的任意位置,且只需要较小的改动。
2. 可微分性:STN是一个可微分的结构,可以反向传播,整个网络可以端到端训练。
3. 不需要额外的监督信息。
1.6 论文中的实验结果
1.6.1 Distroted MINST
对MINST数据集做了rotation(R), rotation, scale and translation (RTS), projective transformation (P), andelastic warping (E)
Baseline:FCN,CNN。
ST-FCN:STN直接作用在inputiamge。
ST-CNN:STN直接作用在inputiamge。
STN内部:都使用双线性插值,但用了不同的transformationfunctions,θ参数不同:an affine transformation(Aff 仿射变换), projective transformation (Proj 投影变换),and a 16-point thin plate spline transformation (TPS 16点薄板样条变换)。
实验结果如下:
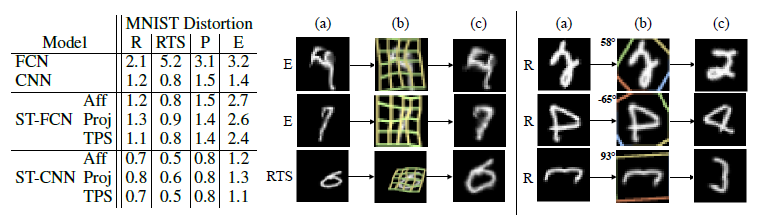
右边的图片是CNN识别失败但STN识别成功的例子。(a)输入图片(b)STN中grid的可视化 (c)STN输出图片
(更多的关于实验中网络结构的参数说明,请参见STN原论文)
1.6.2 Street View House Numbers
图片来自真实世界中的街景房屋编号,数据集约有200k张图片,每张图片中包含一个数字序列,数字范围是从1到5。
Input data:从原图中crop得到包含数字编号的小图片,大小是64×64或128×128。
Baseline:charactersequence CNN model,11个隐层,5个独立的softmaxclassifier。
ST-CNN Single:在Baseline的inputdata上引入一个STN,其localisation net是一个4层CNN
ST-CNN Multi:在Baseline的前4个卷积层之前,分别引入一个STN(一共4个STN),其localisationnet是2层32个神经元的FCN。
上述STN都使用了双线性差值和仿射变换。
实验结果如下:
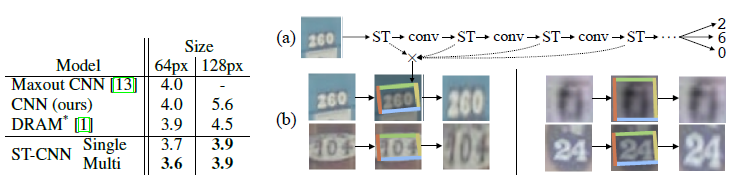
(a)ST-CNN Multi的网络结构示意图 (b)ST-CNN Muli的可视化效果
1.6.3 CUB-200-2011 birds dataset
CUB-200-2011birds dataset来自《TheCaltech-UCSD Birds-200-2011 dataset》,包括6k训练图片,5.8k测试图片,包括200种鸟类,是多标签的。在该论文的实验中,只用了classlabel来训练。
Baseline:anInception architecture with batch normalisation pre-trained on ImageNet andfine-tuned on CUB,达到82.3%的正确率。
ST-CNN:2个或4个并行的STN,结构如下:
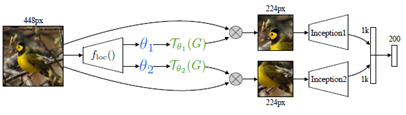
实验结果如下,4xST-CNN比Baseline提高了1.8%的准确率:
(缺图)
右上图片:2xST-CNN的可视化结果,2个STN表现为红色、绿色的两个方框,有趣的是,看起来红框检测了鸟的头部,绿框检测了鸟的身体。
右下图片:4xST-CNN的可视化结果,有类似效果。
1.7 应用场景
1. 在OCR中,用STN对扭曲倾斜的文本区域整体进行校正,帮助后续网络更好地识别内容;STN也可以对单个字符做校正。
2. 在OCR中,从一整幅原图中找到若干个不同尺寸的文本区域,用STN得到固定尺寸的featuremap,再对其中的内容进行文字识别。
1.8 SpatialTransformerOP MXNet
SpatialTransformerOP是一个inference过程的算子,要求输入inputdata和locatisation net的参数θ。
1.8.1 接口
SpatialTransformer(data=None, loc=None,target_shape=_Null, transform_type=_Null, sampler_type=_Null, name=None,attr=None, out=None, **kwargs)
|
Parameters: |
· data (Symbol) – Input data to the SpatialTransformerOp. · loc (Symbol) – localisation net, the output dim should be 6 when transform_type is affine. You shold initialize the weight and bias with identity tranform. · target_shape (Shape(tuple), optional, default=[0,0]) – output shape(h, w) of spatialtransformer: (y, x) · transform_type ({‘affine’}, required) – transformation type · sampler_type ({‘bilinear’}, required) – sampling type · name (string, optional.) – Name of the resulting symbol. |
|
Returns: |
The result symbol. |
|
Return type: |
1.8.2 正向
1. 把target的坐标归一化到[-1,1],变成齐次坐标
2. 调用linalg_gemm,做仿射变换,即Gridgenerator过程
3. 调用BilinearSamplingForward,做双线性差值
代码在 http://rtfcode.com/xref/mxnet-0.12.1/src/operator/spatial_transformer-inl.h#L68
1.8.3 反向
1. 调用BilinearSamplingBackward
2. 调用linalg_geem
2 Deformable Convolution
2.1 相关研究
DeformableConvolution借鉴了之前Spatial Transformer Network的bilinearsampling的思路和具体的backpropagation方法,使用了bilinearsampling将任何一个位置的输出,转换成对于feature map的插值操作。
2.2 算法原理
虽然CNN中的特征映射图和卷积核是3Dtensor,但deformable convolution是在2D空间域上运行的,并且在通道维度上保持不变。
1. 传统2D卷积
设输入特征图x,输出特征图y,卷积核w,设R表示感受野的大小,以3x3stride=1的卷积为例,R={(-1,1), (-1,0), …, (1,0), (1,1)}定义了9个位置,用N=9表示位置的个数。
于是,计算输出特征图y上的每个位置p0,
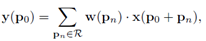
2. 可变形卷积
仅增加了一个参数△pn,其中n=1,2, … , N,计算可变形卷积的公式为,
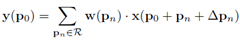
然而,△pn通常是小数,于是就引入了bilinearsampling,来计算变形后的x(p) = x(p0+pn +△pn),
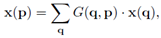
其中,q表示p附近的4个点,函数G(·,·)表示bilinearsampling的计算,因为是双线性差值,G(·,·)有x、y两个维度,
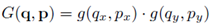
其中g(a,b) = max(0, 1-|a-b|),这跟STN中的双线性差值是一致的。
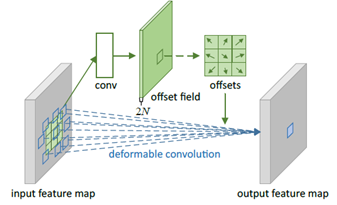
重点来了,deformableconvolution到底学习的是什么?
可变形卷积通过一个conv层,是对inputfeature map中的每个位置,学习得到offset field,这个offsetfield的大小是和input feature map相同的。
还是以3×3 stride=1的filter为例,N=9,offset field的维度是2N=18,代表了input feature map中每个位置,对应filter的3×3区域中的9个计算点都有x、y方向上的2个offset,于是2N=2*3*3=18。
学习得到offsetfield,就能计算x(p0+pn +△pn),就能根据公式计算出outputfeature map中的y(p0)了。
2.3 应用
注意到,deformable convolution的输入输出特征图尺寸与标准卷积是相同的,因此它可以取代在现有的CNNs中原有的卷积模块的位置。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/180576.html原文链接:https://javaforall.net


