
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
聚类分析是统计学中研究这种“物以类聚” 问题的一种有效方法,它属于统计分析的范畴。聚类分析的实质是建立一种分类方 法,它能够将一批样本数据按照他们在性质上的亲密程度在没有先验知识的情况下自动进行分类。这里所说的类就是一个具 有相似性的个体的集合,不同类之间具有明显的区别。
目录
一、定义:
聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准, 聚类分析能够从样本数据出发,自动进行分类。聚类分析所使用方法的不同,常常会得到不同的结论。不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。 因此我们说聚类分析是一种探索性的分析方法。
二、区别于分类分析:
聚类与分类的不同在于,聚类所要求划分的类是未知的。
聚类是将数据分析到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。
从统计学的观点看,聚类分析是通过数据建模简化数据的一种方法。传统的统计聚类分析方法包括系统聚类法、分解法、加入法、动态聚类法、有序样品聚类、有重叠聚类和模糊聚类等。采用k-均值、k-中心点等算法的聚类分析工具已被加入到许多著名的统计分析软件中,如SPSS、SAS等。
从机器学习的角度讲,簇相当于隐藏模式。聚类是搜索簇的无监督学习过程。与分类不同,无监督学习不依赖预先定义的类或带类标记的训练实例,需要由聚类学习算法自动确定标记,而分类学习的实例或数据对象有类别标记。聚类是观察式学习,而不是示例式的学习。
聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。聚类分析所使用方法的不同,常常会得到不同的结论。不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。
从实际应用的角度看,聚类分析是数据挖掘的主要任务之一。而且聚类能够作为一个独立的工具获得数据的分布状况,观察每一簇数据的特征,集中对特定的聚簇集合作进一步地分析。聚类分析还可以作为其他算法(如分类和定性归纳算法)的预处理步骤。
三、聚类方法
- 层次聚类(Hierarchical Clustering)
合并法、分解法、树状图 - 非层次聚类
划分聚类、谱聚类
四、层次聚类分析原理
层次聚类法的运算原理都是基于事物(个案)之间的距离,它的运算过程可以总结成下面两个步骤:
-
在聚类开始前,假设有n个事物(个案),每个个案(事物)都自成一类,然后按照定义的距离公式计算个案之间的距离,这些距离可以整理成一个n*n的距离矩阵。将距离最近的两个个案合并为一类,那么总类别就减少为n-1个。
-
重复上面的过程,计算出n-1个类别间的距离,形成新的距离矩阵,再将距离最接近的两个类别合并。重复以上过程,直至所有的个案都被归为一类为止。
从以上层次聚类分析的运算过程可知:层次聚类可以对个案(事物)进行聚类。因为层次聚类提供的距离测量方法非常丰富,所以能够用于计算的个案(事物)的指标数据可以是连续型数据,也可以是分类型数据。
在以上聚类过程中,还涉及到类别起点的选择,可以思考一下,当两个个案(事物)被并为一类后,下一次计算距离时,该类别的起点坐标如何确定?以不同的类别起点计算类别之间的距离,会得到不同的距离结果。根据类别距离的不同确定方式,层次聚类法可以分为以下几种类型,如下图:
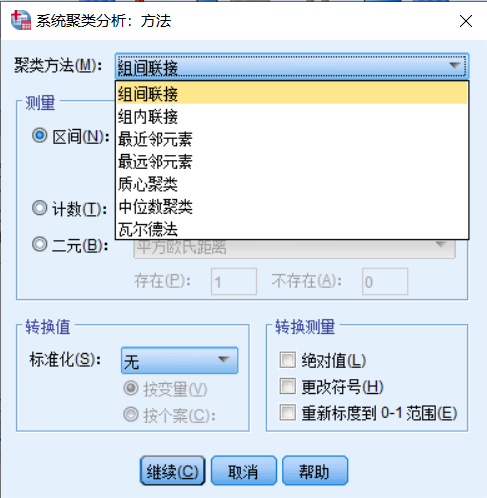

注:使用的是spss处理,具体方法为:分析>>分类>>系统聚类>>方法
-
组间联接:用两个类别间各个事物(个案)两两之间距离的平均值来表示两个类别之间的距离,这是SPSS默认的方法,也是最为稳健的聚类方法。
-
组内联接:除了考虑上面组间联接的距离之外,还需要综合考虑类别内部在合并之前的类别距离。也就是充分考虑所有数据点之间的距离关系。
-
最短距离法:也称为最近邻元素聚类,用两个类别中各个事物(个案)之间最短的那个距离来表示两个类别之间的距离。
-
最长距离法:也称为最远邻元素聚类,用两个类别中各个事物(个案)之间最长的那个距离来表示两个类别之间的距离。
-
重心法:也称为质心聚类,用两个类别重心之间的距离来表示两个类别之间的距离。重心就是类别中所有事物(个案)指标数据的平均值。
-
中位数聚类:也称为中间距离聚类。类与类之间的距离既不采用最近距离,也不采用最远距离,而是将两者的平均值作为两个类别的距离。
-
离差平方和法:也称为瓦尔德(Wald)法。该聚类方法是使各类别中的离差平方和较小,而不同类别之间的离差平方和较大,将两个类别合并后增加的离差平方和作为两类之间的距离。
五、举例分析
我们国家是一个自然地质灾害频发的国家。6月24日四川茂县叠溪镇新磨村突发山体垮塌,造成全村100余人被掩埋,截止6月25日14时,已经确认10人遇难,仍有93人失联。面对突发的自然灾害,正确的应急救灾程序尤为重要,这决定是否能够最大限度的减少伤亡,而应急物资的分类、储备和物流是重要组成部分。
应急物资的种类繁多,涉及到衣食住行的各个方面,各种物资的价格也不尽相同,库存条件、数量等都存在差别,这些问题都给应急物资管理带来困难。面对品种繁多的应急物资,对所有品种都给予相同程度的重视是不合理的,要达到有限资源的作用最大化,就必须对应急物资进行分类管理。在应急物资管理领域,物资的分类主要依据物资的性质进行定性分类,然后制定优先级,并没有定量的评定标准,不能很好的表明某类物资的重要性。因此有些学者提出基于聚类分析的应急物资储备分类方法。
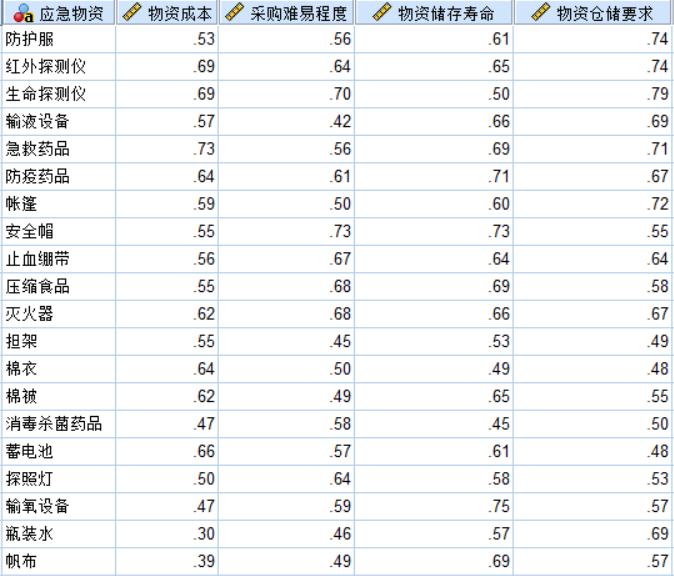
首先选取20种常用应急物资:防护服、安全帽、止血绷带、担架、红外探测仪、生命探测仪、输液设备、输氧设备、急救药品、防疫药品、瓶装水、压缩食品、帐篷、棉衣、棉被、消毒杀菌药品、蓄电池、灭火器、探照灯、帆布。从以下四个一级指标对它们进行评价,每个一级指标下面还有3到4个二级指标,如下图所示:
通过问卷调查的形式,咨询专家和储备工作相关人员对以上各项指标进行打分,然后采用模糊评价的形式,得到以上20种物资的综合评价值。
分析>>分类>>系统聚类>>方法>>组间>>图>>勾选谱系图>>确认
结果分析:
谱系图:谱系图显示了上方聚类步骤的综合情况。我们以距离20为切点,将20种物资分类3大类。然后根据每类物资的特点对它们进行描述。
类别特点描述及对待措施:
-
第一类为高物资成本、高储存要求的物资。尤其对仓储条件的要求很严,例如,生命探测仪对于仓库的存储容量和温湿度都要求很高,必须要重点管理,与此同时,该类物资的采购难度和物资储存寿命较低。综上所述,对于该类物资的管理重点在于提高仓库储存水平。
-
第二类为高物资成本、低仓储要求的物资。该类物资的特点是物资成本相对较高(低于第一类物资的物资成本),但对仓储条件的要求不高。例如,蓄电池的采购成本相对较高,但对储存条件的要求不高,只需保持仓库合理的温湿度,防止受潮即可。对于此类应急物资在储备管理方面应侧重于降低物资存储量的管理,避免高库存,进行中度管理即可。
-
第三类为低物资成本、易采购物资。例如,瓶装水的物资成本低,市场供应充足,生产厂商较多,在灾害发生时即使储备不充足,也容易在市场上快速购买获得。同时,该类物资的储存寿命较长,对仓储条件的要求不高,在储备管理方面进行一般管理即可。
六、参考文献
[1]摘自泰山教育:聚类分析及其SPSS实现
[2]摘自微信公众号生活统计学:SPSS分析技术:层次聚类分析;为四川茂县祈福!聚类分析应用于救灾物资的高效管理
[3]摘自百度百科:聚类分析
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/180858.html原文链接:https://javaforall.net


