
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
总述
- 要理解mAP与F1 Score需要一些前置条件,比如:IoU、FP、TP、FN、TN、AP等
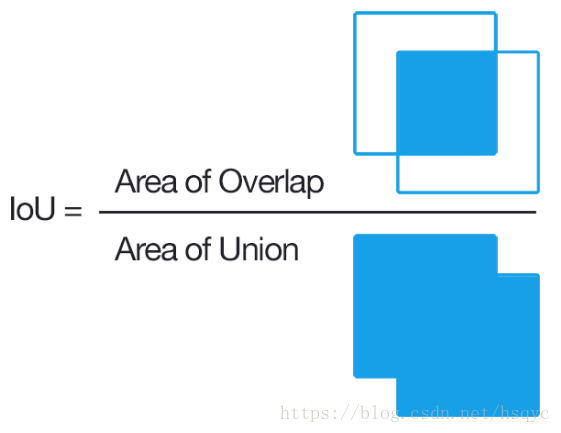
IoU
- 衡量监测框和标签框的重合程度。一张图就能解释。

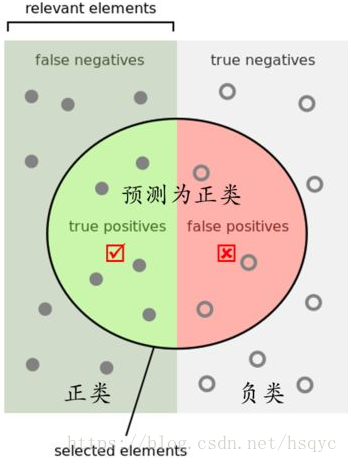
TP、TN、FP、FN
- TP,即True Positives,表示样本被分为正样本且分配正确。
- TN,即True Negatives,表示样本被分为样本且分配正确。
- FP,即False Positives,表示样本被分为正样本但分配错误。
- FN,即False Negatives,表示样本被分为负样本但分配错误。
Precision
- Precision,即精度,表示被正确分配的正样本数占总分配的正样本数的比例,公式为
- P r e c i s i o n = T P ( T P + F P ) Precision=\frac{TP}{(TP+FP)} Precision=(TP+FP)TP
Recall
- Recall,即召回率,表示被正确分配的正样本数占总正样本数的比例,公式为
- R e c a l l = T P ( T P + F N ) Recall=\frac{TP}{(TP+FN)} Recall=(TP+FN)TP
F1-Score
- F1-Score又称F1分数,是分类问题的一个衡量指标,常作为多分类问题的最终指标,它是精度和召回率的调和平均数。对于单个类别的F1分数,可使用如下公式计算
- f 1 k = 2 R e c a l l k ∗ P r e c i s i o n k R e c a l l k + P r e c i s i o n k f1_k=2 \frac{Recall_k*Precision_k}{Recall_k+Precision_k } f1k=2Recallk+PrecisionkRecallk∗Precisionk
- 而后计算所有类别的平均值,记为F1,公式为
- F 1 = ( 1 n Σ f 1 k ) 2 F1= (\frac{1}{n}\Sigma f1_k )^2 F1=(n1Σf1k)2
mAP
- mAP,英文全称是mean Average Precision,即各类别AP的平均值,AP的计算使用了差值平均准确率的评测方法,即Precision-Recall曲线下的面积,公式为
- A P = ( 1 n Σ ( r ∈ 1 n , 2 n … n − 1 n , 1 ) P i n t e r p o ( r ) ) AP=(\frac{1}{n}\Sigma_{(r∈{\frac{1}{n},\frac{2}{n}…\frac{n-1}{n},1})}{P_interpo (r)}) AP=(n1Σ(r∈n1,n2…nn−1,1)Pinterpo(r))
其中n表示检测点的个数,P_interpo ®代表在召回率为r时准确率的数值。根据AP可计算mAP,公式为 - m A P = ( 1 n Σ A P ) mAP=(\frac{1}{n} \Sigma {AP}) mAP=(n1ΣAP)
mAP计算过程:
- 涉及到PR图,挖坑
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/182161.html原文链接:https://javaforall.net


