
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
一、前言
在这个系列博客中,小编将向大家介绍一下一款吞吐超级大的消息中间件——kafka。
说到消息中间件MQ,小编也在前面的博客中介绍过 rocketMq,activeMq等等。
至于为什么叫kafka呢?是因为创作它的程序员叫做jay krep,他非常喜欢 弗兰兹·卡夫卡,觉的kafka这个名字很酷,所以就起了这个名字。名字没有什么特别的意思。
二、什么是kafka?能干点什么?


Kafka是由Apache软件基金会开发的一个开源流平台,由Scala和Java编写。Kafka的Apache官网是这样介绍Kafka的。
流平台?干什么的?
- To publish (write) and subscribe to (read) streams of events, including continuous import/export of your data from other systems.
- To store streams of events durably and reliably for as long as you want.
- To process streams of events as they occur or retrospectively.
翻译过来就是:
- 发布和订阅流数据流,包括从其他系统持续导入/导出数据。
- 持久化数据流,数据落地
- 处理数据流,数据流回放
三、kafka的架构图
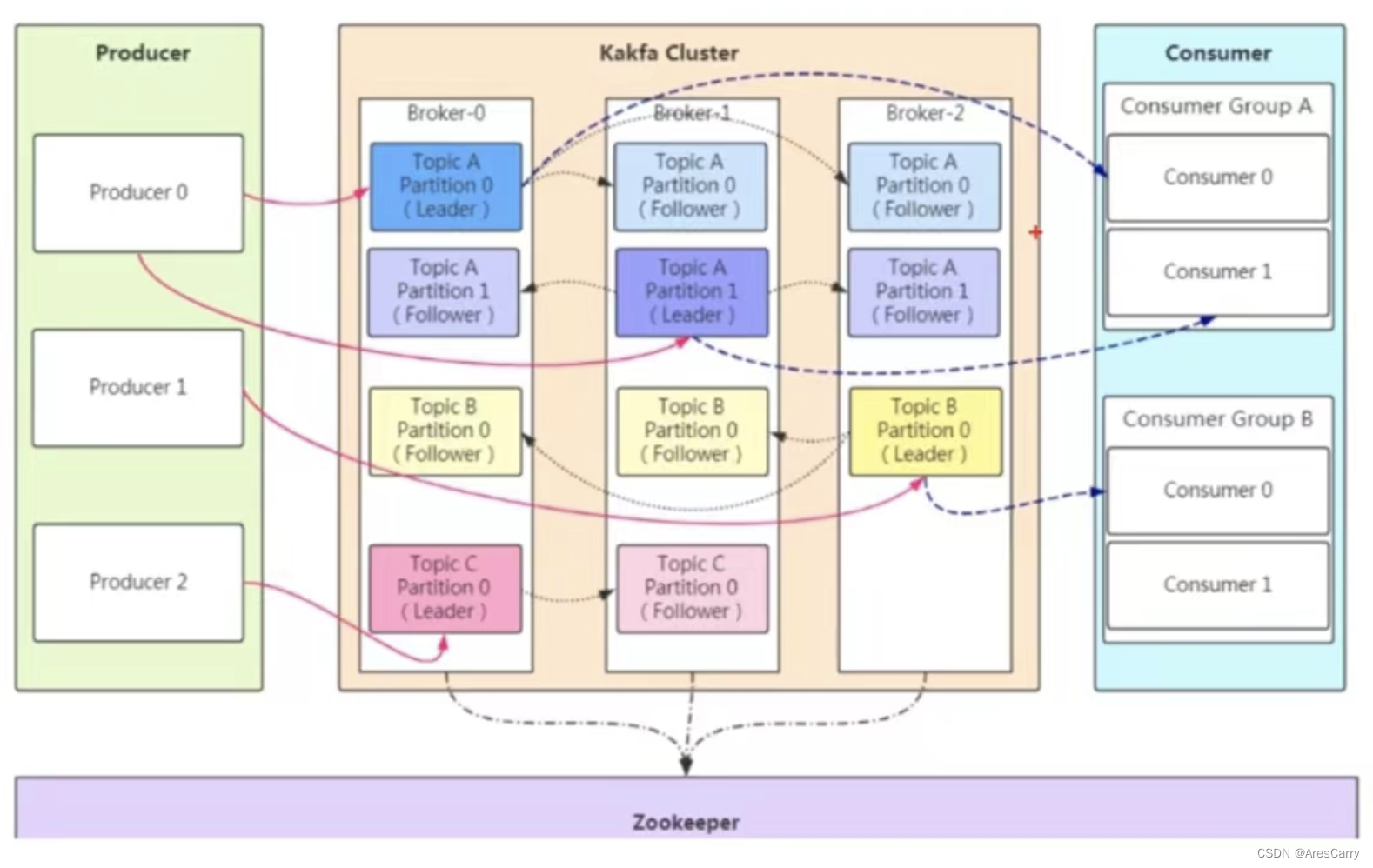
首先kafka其他mq一样,都是有 服务端和客户端组成,客户端我们一般分成 生产者和消费者。
-
生产者
-
服务端,一个节点叫做broker,多个broker组成我们的集群。其中通过 zookeeper来管理集群,比如集群配置,leader的选举,负载均衡等。
-
消费者

这里还有一些概念要介绍:
-
topic
队列,生产者会发送消息到topic,消费者从topic消费消息。 -
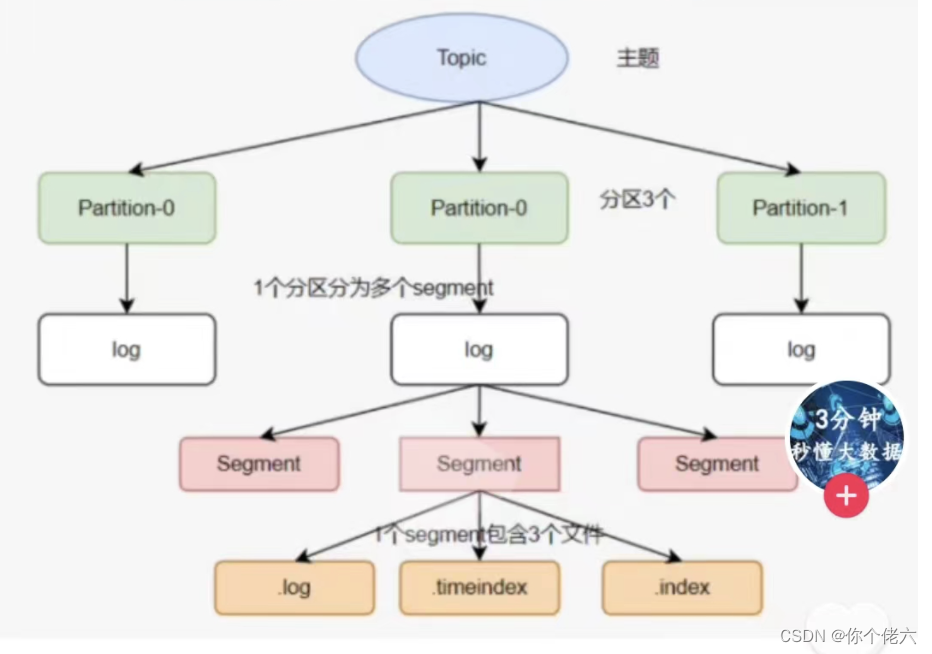
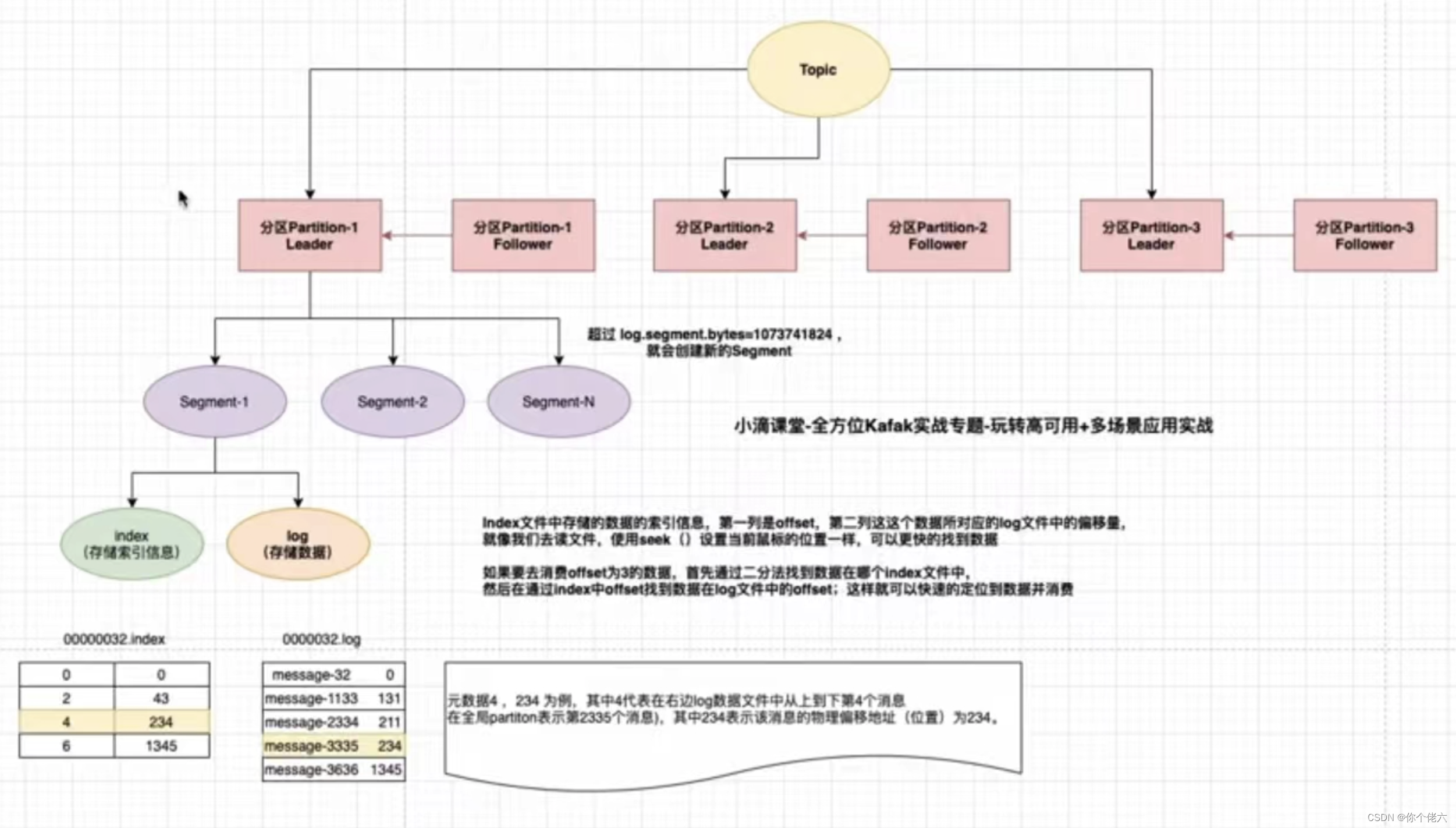
partition
分区,目的是提高并发,一个topic可以有多个partition,每个patition内的消息是保证顺序的,是有序队列。 -
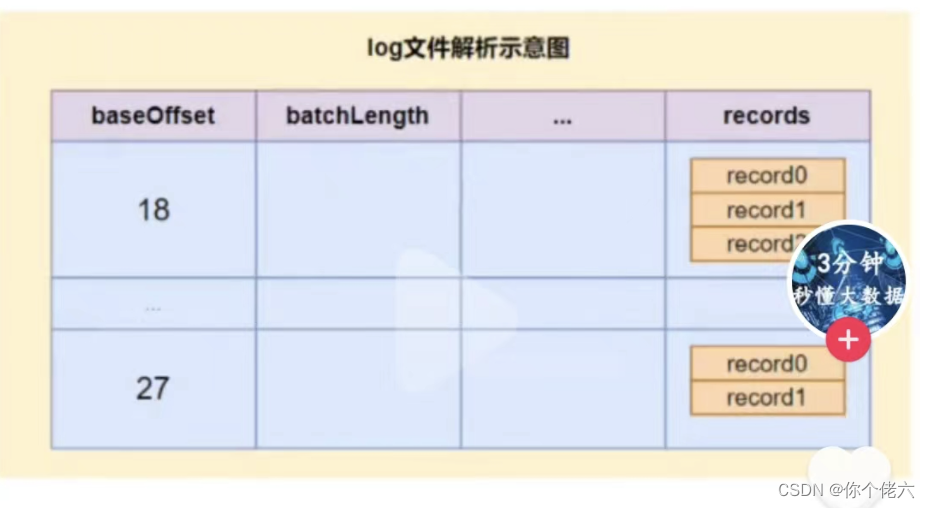
segment
每个patition又由多个segment file组成。文件存储二进制格式数据
segment = xxx.index + xxxx.timeindex + xxxx.log
xxxx.log是数据文件,xxx.index 和 xxx.timeindex 是索引文件。
log文件大小默认是1G,超出限制会新建立一个文件。可以通过log.segment.byte参数来配置每个segment大小。
命名规则:partition的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset + 1


-
replica
副本,kafka为了保证消息的高可用性,为每个日志文件都做了备份,被称作副本,目的就是为了防止数据丢失,这样就拆成了两类:leader 和 follower。如果其中一台broker 宕机,Kafka 会从剩余的 replica 中选举出新的 leader 继续提供服务。 -
leader
主副本,其中的数据会给到消费者。 -
follower
从副本,备胎,个别broker宕机的时候,可以重新选举为主副本。从副本中的数据,不会给到消费者。从副本主动从主副本拉取,不同从副本的拉取同步速度也是不一样的。 -
offset
消费者消费的位置信息,当消费者挂掉或重新恢复的时候可以,从消费位置重新继续消费。 -
consumer group
消费者组,消费者组内所有的消费者,分别消费不同分区数据,消费互斥。 -
ISR
in sync replica,基本保持同步的Replica列表,是从副本与主副本保持同步的列表,默认是30s数据,如果从副本保持同步,那么重新选举leader的时候,会被选择;如果与主副本同步差距较大,会被移除,选举leader,将不会被考虑。 -
OSR
out of sync replica,同步有延迟的follower列表。 -
LEO (logEndOffset)
表示每个partition的log最后一条message的位置。 -
HW(高水位 HighWatermark)
每个partition的副本数据间同步且一致的offset位置,即表示所有副本都已经commit的位置
高水位之前的数据才是Commit后的,对消费者才可见

四、小结
了解kafka的架构,就是要了解设计理念,阿里的rocketmq也是根据kafka的这个架构来设计的,好的架构可以拓展出更多的中间件。了解透了,你就会有收获。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/182549.html原文链接:https://javaforall.net


