
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
LR模型相关知识点
归一化
- 机器学习中为什么需要归一化?
(1) 消除量纲影响
健康=3身高+2体重,身高单位:米,体重单位:斤
Δ身高=0.3,Δ体重=5,前者变化更大,但‘健康’指标变化小
(2)可以加速优化过程,后加快了梯度下降求最优解的速度;(减少迭代次数,加快模型的训练)
数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
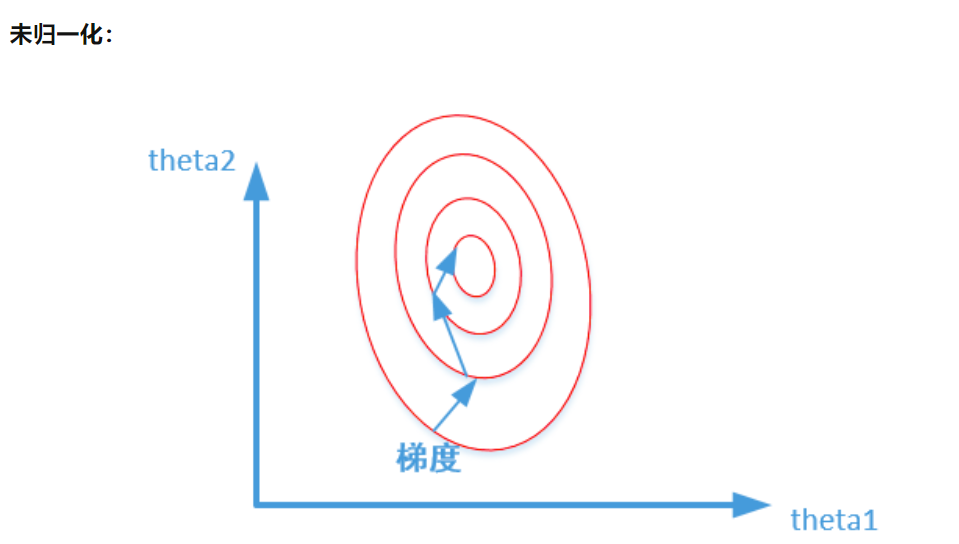

两个特征区别相差特别大。所形成的等高线比较尖锐。当时用梯度下降法时,很可能要垂直等高线走,需要很多次迭代才能收敛。
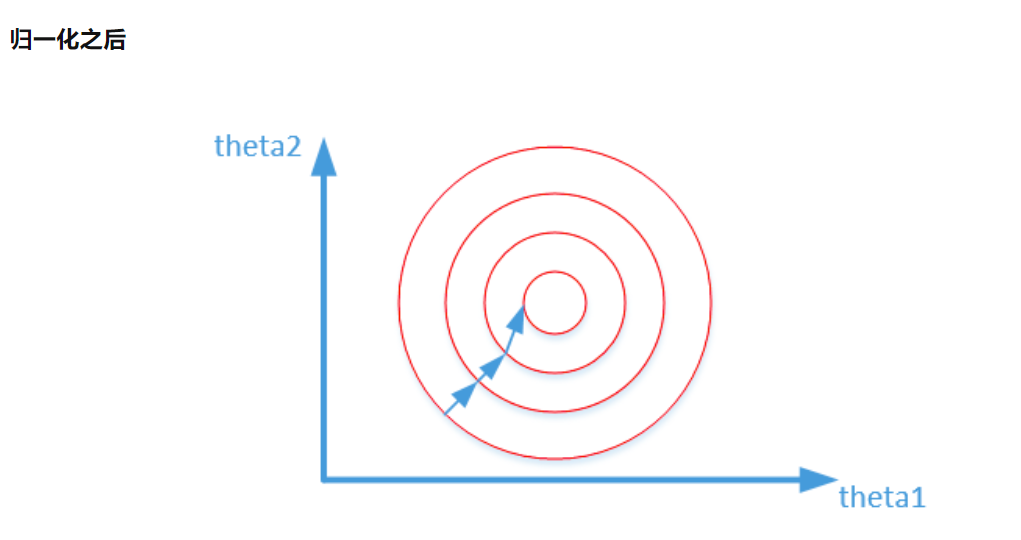
对两个原始特征进行了归一化处理,其对应的等高线相对来说比较圆,在梯度下降时,可以较快的收敛。
(3)归一化有可能提高精度
有些分类器需要计算样本之间的距离,例如k-means。如果一个特征的值域范围特别大。那么距离计算就主要取决于这个特征,有时会与实际情况相违背。(比如这时实际情况是值域范围小的特征更重要)
- 哪些归一化的方法?
Ⅰ 线性函数归一化
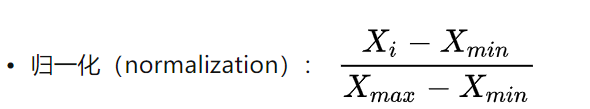
缺陷:
1)当有新数据加入时,可能导致max和min的变化,需要重新定义
2)存在极端的最大最小值,即易受异常值影响
适用:
如果对输出结果范围有要求,用归一化
如果数据较为稳定,不存在极端的最大最小值,用归一化
Ⅱ 0均值标准化

适用:
如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响
归一化与标准化的区别
1)归一化的缩放是统一到区间(仅由极值决定),
标准化的缩放是更加“弹性”和“动态”的,和整体样本的分布有很大的关系。
2)归一化:缩放仅仅与最大最小值有关。
标准化:缩放与每个点有关。通过方差和均值体现出来。
3)归一化:输出范围在0-1之间
标准化:输出范围是负无穷到正无穷
- 归一化和标准化本质上都是一种线性变换
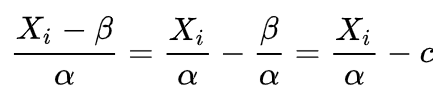
就发现事实上就是对向量 x按照比例压缩a再进行平移 c。所以归一化和标准化的本质就是一种线性变换。
性质:线性变化不改变原始数据的数值排序
- 代码
from sklearn import preprocessing
from scipy.stats import rankdata
x = [[1], [3], [34], [21], [10], [12]]
std_x =preprocessing.StandardScaler().fit_transform(x)
norm_x = preprocessing.MinMaxScaler().fit_transform(x)
# print(std_x)
# print(norm_x)
print('原始顺序 :', rankdata(x))
print('标准化顺序:', rankdata(std_x))
print('归一化顺序:', rankdata(norm_x))
- 哪些模型需要归一化,哪些不需要
需要:
线性回归、LR、SVM、GBDT(?)、KNN、KMeans 、神经网络(基本都有wx+b)基于参数的模型或基于距离的模型,都是要进行特征的归一化。
不需要:
概率模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率,更关注增量,如决策树、rf
基于树的方法是不需要进行特征的归一化,例如随机森林,bagging 和 boosting等
- LR归一化问题,什么情况可以不归一化,什么情况必须归一化
可以不归一化: 量纲没有明显差距,
不同特征取值范围差异过大的数据最好都先做归一化
还要具体看使用两种归一化方法中的哪个
损失函数及解法
3. 为什么提到LR损失函数要能知道交叉熵,为什么是它,以它为损失函数在优化的是一个什么东西,知道它和KL散度以及相对熵的关系
4. 提到LR的求解方法,比如SGD,知道SGD和BGD的区别,知道不同的GD方法有什么区别和联系,二阶优化算法知道什么,对比offline learning和online learning的区别
调参
6. 提到调参,知道模型不同超参数的含义,以及给定一个特定情况,大概要调整哪些参数,怎么调整
正则化(regularization)
- 如何防止模型的过拟合(overfit)?
通过正则化 - l1、l2的原理,几何解释和概率解释?
几何解释
https://zhuanlan.zhihu.com/p/35356992
概率解释
https://zhuanlan.zhihu.com/p/56185913 - 为什么正则化能够防止过拟合?
模型越复杂,越容易过拟合,这大家都知道,加上L1正则化给了模型的拉普拉斯先验,加上L2正则化给了模型的高斯先验。从参数的角度来看,L1得到稀疏解,去掉一部分特征降低模型复杂度。L2得到较小的参数,如果参数很大,样本稍微变动一点,值就有很大偏差,这当然不是我们想看到的,相当于降低每个特征的权重。)
模型过拟合通常是因为模型复杂度过高(补图)
模型复杂度又通常是与参数个数有关:参数个数越多,模型复杂度越高。所以
感性角度: 减少参数个数(让参数=0),就可以降低模型复杂度
*数学角度:*相当于拉格朗日
【待完成】再补充几个视频
- 为什么l1正则化具有稀疏性(w=0)?/为什么l1正则能够进行特征选择(使w=0)
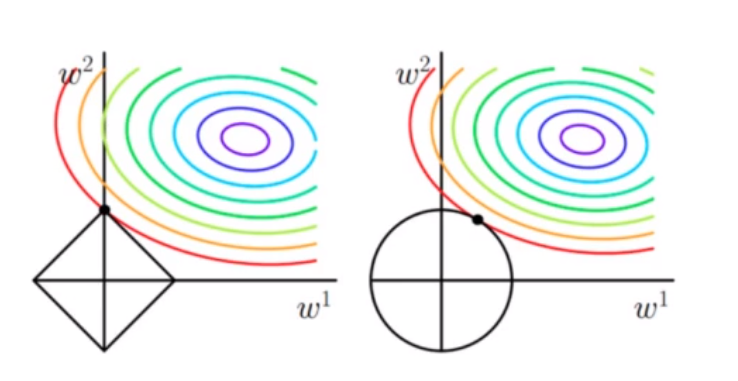
解空间的形状的角度: 交点才满足最小化目标和约束条件,方形更容易在坐标轴上有交点,所以w=0可以实现,圆形l2可以使参数很小,但基本不会取0
L1正则化是L1范数而来,投到坐标图里面,是棱型的,最优解在坐标轴上取到,所以某些部分的特征的系数就为0。
(彩色为等值线图:同一圈上经验风险/损失是相同的;
方形、圆形:分别为l1/l2的可行域)
贝叶斯概率角度:
贝叶斯最大后验概率估计
https://zhuanlan.zhihu.com/p/32685118
- L1正则化不可导,怎么求解?
坐标轴下降法(按照每个坐标轴一个个使其收敛),最小角回归(是一个逐步的过程,每一步都选择一个相关性很大的特征,总的运算步数只和特征的数目有关,和训练集的大小无关)
其他
- LR的分布式实现逻辑是怎么样的,数据并行和模型并行的区别,P-S架构大概是怎么一回事
- LR作为一个线性模型,如何拟合非线性情况?特征侧比如离散化,交叉组合,模型比如引入kernel,又可以推广到FM等model上
- 逻辑回归为什么一般性能差?
LR是线性的,不能得到非线性关系,实际问题并不完全能用线性关系就能拟合。
参考:
https://zhuanlan.zhihu.com/p/32685118
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/183429.html原文链接:https://javaforall.net


