
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
承接上篇讲解,本文代码,讲解看上篇
目标:GBDT+LR模型
实现GBDT+LR模型代码,并比较和各种RF/XGBoost + LR模型的效果(下篇),发现GBDT+LR真心好用啊。
继续修复bug:GBDT和LR模型需要分开用不同的数据训练,当数据量多的时候,就能体现出差别,分开训练时防止过拟合,能提升模型的泛化性能。
步骤:GBDT+OneHot+LR
构造GBDT+LR步骤
训练阶段:
1、 获取特性数据,拆分成3组,一组测试数据,一组GBDT训练数据,一组LR训练数据
2、训练GBDT分类器
3、遍历GBDT树的叶子节点,拼接成一个长长的一维向量
4、 训练OneHot编码器
5、 训练LR模型
预测阶段:
1、把带预测的特征输入到GBDT
2、获得叶子节点,拼接成一个常常的一维向量
3、获得OneHot向量
4、LR预测结果
这里发现了上篇文章的一个错误:
就是GBDT树的叶子节点,输出的不是0/1的预测值,也不是0/1的概率,而是一些实数值,值还比较大,因此,叶子节点的值,拼接出来的向量,是个长长的非稀疏矩阵。
结果表明,GBDT+LR效果好过单纯的GBDT。
GBDT模型不能太深,太深效果反而不好,可能跟GBDT容易过拟合有关系。
测试数据:iris
数据采用sklearn里面自带的iris花分类数据。为了模拟CTR的二分类效果,做了一下特殊处理:
1、 iris花是个3分类的数据,因此把分类为2的数据,统一归为0,这样就模拟了0/1的二分类
2、分类数据比0/1=2:1
提醒:貌似GBDT模型不能太深,太深效果反而不好,可能跟GBDT容易过拟合有关系。
代码:
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
from sklearn.ensemble import GradientBoostingClassifier
np.random.seed(10)
# 加载测试数据
iris_data,iris_target = load_iris(return_X_y=True,as_frame=True)
iris_data.columns =['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm']
print(iris_data.head(5))
print(iris_data.columns)
print(iris_target)
iris_target = pd.DataFrame(iris_target,dtype='float32') #替换类型
print(iris_target.dtypes)
iris_target[iris_target['target']==2]=0 #把类别为2的归为0,这样模拟CTR的0/1标记。
iris=iris_data.merge(iris_target,left_index=True,right_index=True) #拼接成一个大的Dataframe,便于拆分测试数据
print(iris.head(5))
from sklearn.model_selection import train_test_split
# 拆分测试数据和验证数据
iris_train ,iris_test = train_test_split(iris,test_size=0.8,random_state=203)
print(iris_train.head(5))
#拆分特征和标签为测试集和训练集
Y_train = np.array(iris_train['target'])
X_train = iris_train.drop(columns=['target'])
#训练集进一步拆分为GBDT训练集和LR训练集,两者分开,能防止过拟合,提升模型的泛化性能。
X_train_GBDT ,X_train_LR,Y_train_GBDT,Y_train_LR = train_test_split(X_train,Y_train,test_size=0.5,random_state=203)
print(X_train_GBDT.head(5))
Y_test = np.array(iris_test['target'])
X_test = iris_test.drop(columns=['target'])
print(X_test.head(5))
#训练GBDT模型
from sklearn.ensemble import GradientBoostingClassifier
GBDT = GradientBoostingClassifier(n_estimators=5)
GBDT.fit(X_train_GBDT,Y_train_GBDT)
#GBDT直接预测
GBDTPredict= GBDT.predict(X_test)
#获取GBDT叶子节点的输出,展开成1维
GBDTy=GBDT.apply(X_train_GBDT)[:,:,0]
#训练OneHot编码
from sklearn.preprocessing import OneHotEncoder
OneHot = OneHotEncoder()
OneHoty=OneHot.fit_transform(GBDTy)
# 导入线性模型LR
from sklearn.linear_model import LinearRegression
OneHot.transform(GBDT.apply(X_train_LR)[:,:,0])
LR = LinearRegression()
LR.fit(OneHot.transform(GBDT.apply(X_train_LR)[:,:,0]),Y_train_LR)
#test GBDT输出预测的概率值
GBDT.predict_proba(X_test)[:,1]
# 把测试数据输入到训练好的GBDT模型,然后得到叶子节点的值
GBDTtesty=GBDT.apply(X_test)[:,:,0]
print(GBDTtesty)
# 得到OneHot编码
OneHotTesty = OneHot.transform(GBDTtesty)
#LR模型预测
LRy= LR.predict(OneHotTesty)
print(LRy)
#导入评估模块,使用AUC 评估模型
from sklearn.metrics import roc_curve,roc_auc_score
# 测试GBDT+LR的预测效果
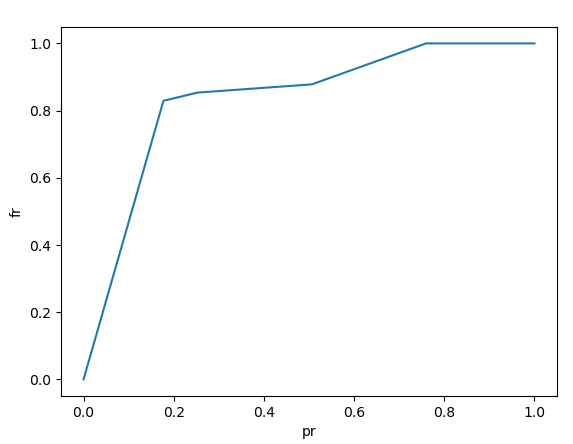
pr,fr,_=roc_curve(Y_test,LRy)
print(Y_test)
print('roc_auc_score of GDBT+LR is ',roc_auc_score(Y_test,LRy))
from matplotlib import pyplot
pyplot.plot(pr,fr)
pyplot.xlabel("pr")
pyplot.ylabel('fr')
pyplot.show()
# 测试GBDT预测的概率值和真值的差距
print('roc_auc_score of GDBT predict_proba is ',roc_auc_score(Y_test,GBDT.predict_proba(X_test)[:,1]))
# 测试GBDT预测值和真值的差距
print('roc_auc_score of GDBT predict is ',roc_auc_score(Y_test,GBDT.predict(X_test)))
结果比较:与直接GBDT模型的比较
roc_auc_score of GDBT+LR is 0.8348255634455078

直接用GBDT预测的结果:
roc_auc_score of GDBT predict_proba is 0.8260265514047544
roc_auc_score of GDBT predict is 0.8260265514047544
可以看到,GBDT+LR模型的效果,好于GBDT。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/183636.html原文链接:https://javaforall.net


