
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
由于工作内容接触到点云标定,需要用到最小二乘法,所以特意花了点时间研究LM算法,但是由于大学的高等数学忘得差不多了,所以本文从最基本的一些数学概念开始;
信赖域法
在最优化算法中,都是要求一个函数的极小值,每一步迭代中,都要求目标函数值是下降的,而信赖域法,顾名思义,就是从初始点开始,先假设一个可以信赖的最大位移,然后在以当前点为中心,以为半径的区域内,通过寻找目标函数的一个近似函数(二次的)的最优点,来求解得到真正的位移。在得到了位移之后,再计算目标函数值,如果其使目标函数值的下降满足了一定条件,那么就说明这个位移是可靠的,则继续按此规则迭代计算下去;如果其不能使目标函数值的下降满足一定的条件,则应减小信赖域的范围,再重新求解。
泰勒公式:
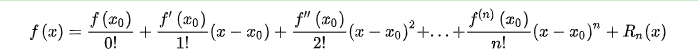

雅可比矩阵
雅可比矩阵几乎在所有的最优化算法中都有提及,因此我们很有必要了解一下其具到底是什么,关于这一点,下方截图说的很清楚;
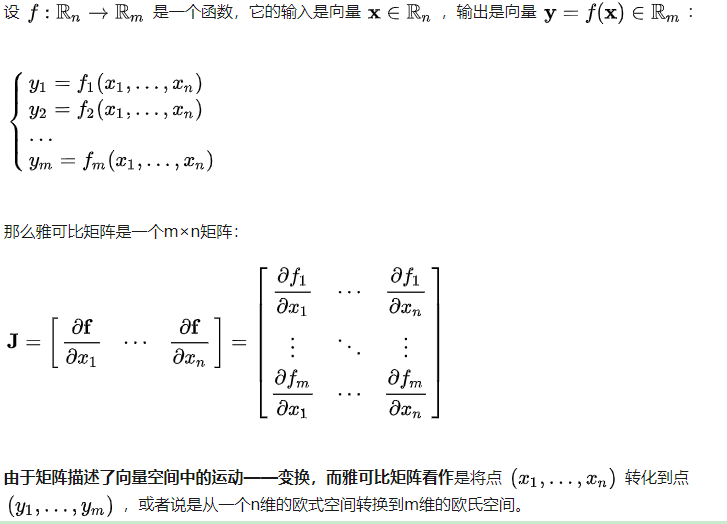
从上面可以了解,雅可比矩阵实际上就是一阶偏导数所组成的矩阵,其列数由未知参数个数决定,其行数由我们提供的输入参数组决定;
各种最优化算法

需要注意的是,对于LM算法,可以具体到下种形式:
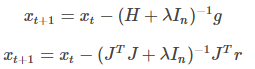
其中,r是残差;
代码实现
LM算法的关键是用模型函数 f 对待估参数向量p在其领域内做线性近似,忽略掉二阶以上的导数项,从而转化为线性最小二乘问题,它具有收敛速度快等优点。
LM算法需要对每一个待估参数求偏导,所以,如果你的拟合函数 f 非常复杂,或者待估参数相当地多,那么就不适合使用LM算法了,可以使用Powell算法,Powell算法不需要求导。
需要说明的是,这是非线性无约束的问题,如果待估参数是有约束的,暂时还没有涉及到这个领域;
就是从初始点开始,先假设一个可以信赖的最大位移,然后在以当前点为中心,以为半径的区域内,通过寻找目标函数的一个近似函数(二次的)的最优点,来求解得到真正的位移。在得到了位移之后,再计算目标函数值,如果其使目标函数值的下降满足了一定条件,那么就说明这个位移是可靠的,则继续按此规则迭代计算下去;如果其不能使目标函数值的下降满足一定的条件,则应减小信赖域的范围,再重新求解。
在使用Levenberg-Marquart时,先设置一个比较小的μ值,当发现目标函数反而增大时,将μ增大使用梯度下降法快速寻找,然后再将μ减小使用牛顿法进行寻找。
6.阻尼系数的调整

当阻尼系数足够大时,使算法更接近最速下降法,所以在残差没有明显变化时可以使用;当阻尼系数足够小时,算法更接近高斯牛顿算法,此时迭代速度更快;
有算法精度ep和上一次残差e,当e<lamda < ep时,lamda = lamda/5,当lamda > ep时,lamda = lamda*5,当lamda < ep时,lamda = lamda;
代码如下:
% 计算函数f的雅克比矩阵
syms a b y x real;
f=a*cos(b*x) + b*sin(a*x)
Jsym=jacobian(f,[a b])
data_1=[ 0, 0.2, 0.4, 0.6, 0.8, 1.0, 1.2, 1.4, 1.6, 1.8, 2.0, 2.2, 2.4, 2.6, 2.8, 3.0,3.2, 3.4, 3.6, 3.8, 4.0, 4.2, 4.4, 4.6, 4.8, 5.0, 5.2, 5.4, 5.6, 5.8, 6.0, 6.2 ];
obs_1=[102.225 ,99.815,-21.585,-35.099, 2.523,-38.865,-39.020, 89.147, 125.249,-63.405, -183.606, -11.287,197.627, 98.355, -131.977, -129.887, 52.596, 101.193,5.412, -20.805, 6.549, -40.176, -71.425, 57.366, 153.032,5.301, -183.830, -84.612, 159.602, 155.021, -73.318, -146.955];
% 2. LM算法
% 初始猜测初始点
a0=100; b0=100;
y_init = a0*cos(b0*data_1) + b0*sin(a0*data_1);
% 数据个数
Ndata=length(obs_1);
% 参数维数
Nparams=2;
% 迭代最大次数
n_iters=60;
% LM算法的阻尼系数初值
lamda=0.1;
%LM算法的精度
ep=100
% step1: 变量赋值
updateJ=1;
a_est=a0;
b_est=b0;
% step2: 迭代
for it=1:n_iters
if updateJ==1
% 根据当前估计值,计算雅克比矩阵,雅可比矩阵只需要在第一次循环时计算一次就好
J=zeros(Ndata,Nparams); % 雅可比矩阵的行数由原始输入数据个数决定,列数由待估参数个数决定
for i=1:length(data_1)
J(i,:)=[cos(b_est*data_1(i))+data_1(i)*b_est*cos(a_est*data_1(i)) -sin(b_est*data_1(i))*a_est*data_1(i)+sin(a_est*data_1(i)) ]; % 雅可比矩阵由偏导组成
end
% 根据当前参数,得到函数值
y_est = a_est*cos(b_est*data_1) + b_est*sin(a_est*data_1);
% 计算误差
d=obs_1-y_est;
% 计算(拟)海塞矩阵
H=J'*J;
% 若是第一次迭代,计算误差
if it==1
e=dot(d,d); % 可以认为e是初始值计算所估误差
end
end
% 根据阻尼系数lamda混合得到H矩阵
H_lm=H+(lamda*eye(Nparams,Nparams));
% 计算步长dp,并根据步长计算新的可能的\参数估计值
dp=inv(H_lm)*(J'*d(:))
%求误差大小
g = J'*d(:);
a_lm=a_est+dp(1); % 在初始值上加上所求步长,作为新的评估参数
b_lm=b_est+dp(2);
% 计算新的可能估计值对应的y和计算残差e
y_est_lm = a_lm*cos(b_lm*data_1) + b_lm*sin(a_lm*data_1);
d_lm=obs_1-y_est_lm
e_lm=dot(d_lm,d_lm) % 这个值后面主要用于和上一次误差进行比对,从而调整阻尼系数
% 根据误差,决定如何更新参数和阻尼系数
if e_lm<e % 如果小于上一次误差
if e_lm<ep % 如果小于算法精度
break % 结束,说明该阻尼系数合理
else
lamda=lamda/5; % 如果小于上一次误差,但大于算法精度,那么更新阻尼系数,同时将当前评估参数作为初始值重新计算
a_est=a_lm;
b_est=b_lm;
e=e_lm;
disp(e);
updateJ=1;
end
else
updateJ=0;
lamda=lamda*5;
end
end
%显示优化的结果
a_est
b_est
plot(data_1,obs_1,'r')
hold on
plot(data_1,a_est*cos(b_est*data_1) + b_est*sin(a_est*data_1),'g')
参考链接:
https://blog.csdn.net/a6333230/article/details/83304098
https://blog.csdn.net/baidu_38172402/article/details/82223284
https://zhuanlan.zhihu.com/p/39762178
http://www.360doc.com/content/18/0330/13/18306241_741511614.shtml
https://blog.csdn.net/xueyinhualuo/article/details/46931989?utm_medium=distribute.pc_relevant.none-task-blog-
https://www.cnblogs.com/shhu1993/p/4878992.html
https://en.wikipedia.org/wiki/Levenberg%E2%80%93Marquardt_algorithm
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/187118.html原文链接:https://javaforall.net


