
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
当我们的数据采集到hdfs层上之后,我们就开开始对数据进行建模以便后来分析,那么我们整体的架构先放在每个建模层级的最前面
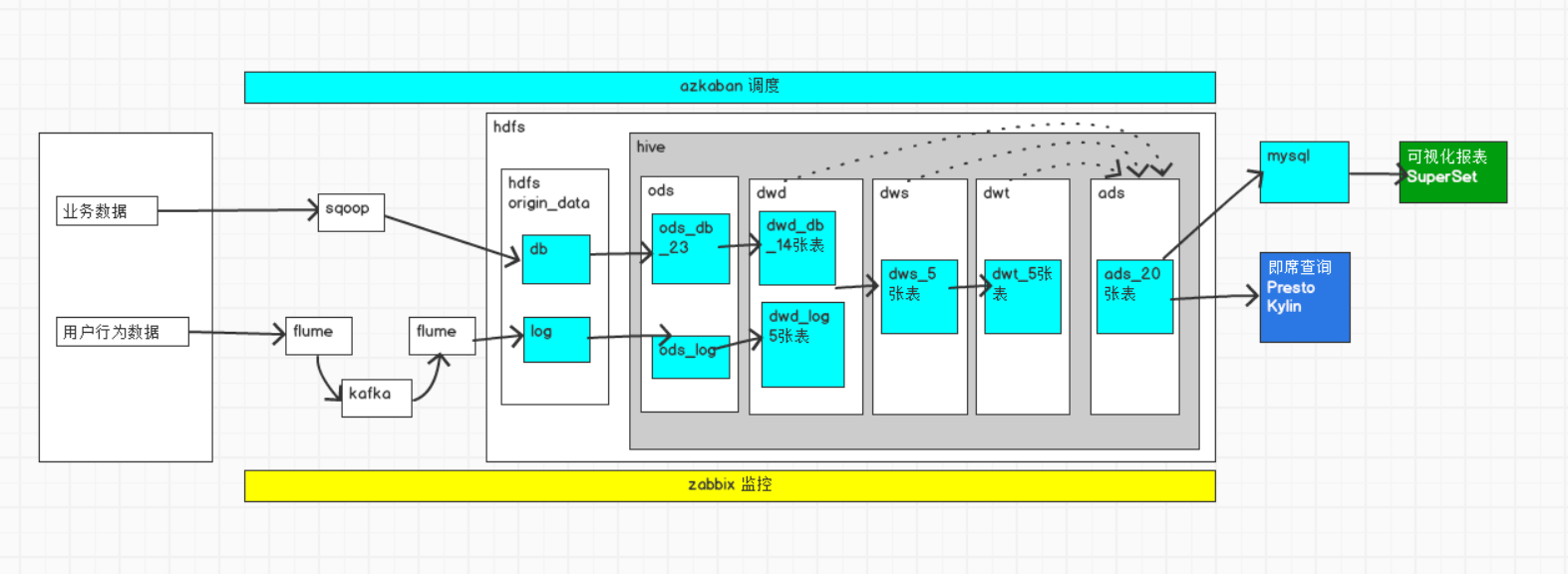


所以项目1的将行为数据和业务数据导入到hdfs中我们已经完成了,现在需要的是将hdfs的数据通过ODS层数据建模,初步的分析以及改变,那么我们首先介绍下ODS层的作用
因为我们的数据刚落到hdfs上,他还只是单纯的数据,并没有能让我们直接操作。所以我们需要将这些数据放入到能够对数据进行操作的框架中,如我们这个项目采取了使用hive的方法。所以我们此次在ODS层需要做到的就是将hdfs上的数据在不丢失数据内容的情况下原封不动的放到hive中。
针对HDFS上的用户行为数据和业务数据,我们如何规划处理?
(1)保持数据原貌不做任何修改,起到备份数据的作用。
(2)数据采用压缩,减少磁盘存储空间(例如:原始数据100G,可以压缩到10G左右)
(3)创建分区表,防止后续的全表扫描
(4)创建外部表。在企业开发中,除了自己用的临时表,创建内部表外,绝大多数场景都是创建外部表。
数仓搭建-ODS层
hive准备
在安装好hive后,我们将hive的运算引擎改为spark,注意这是hive on spark而不是spark on hive,要注意hive和spark的版本兼容问题。然后要安装好有spark
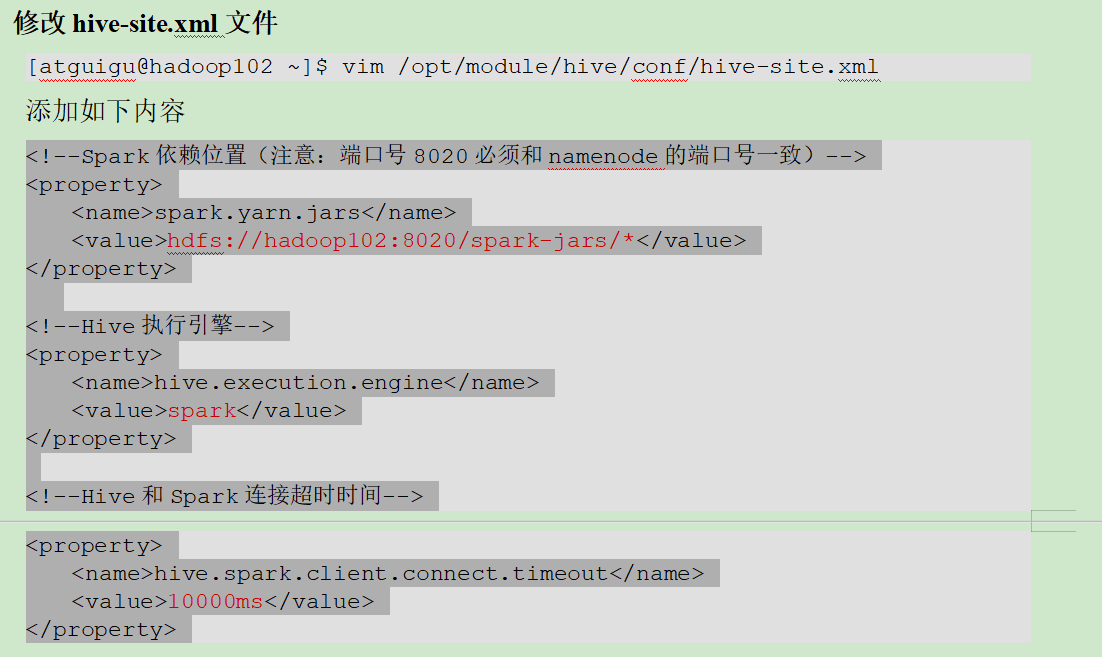
一切没问题后,我们去hive的conf目录内添加关于spark的配置文件,添加后我们hive的运算引擎就变成spark
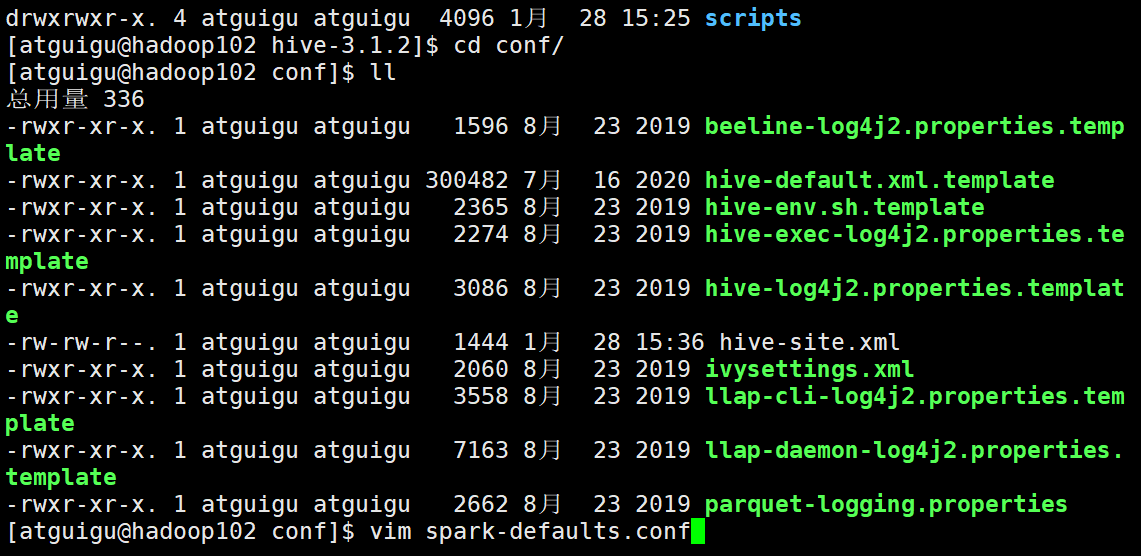
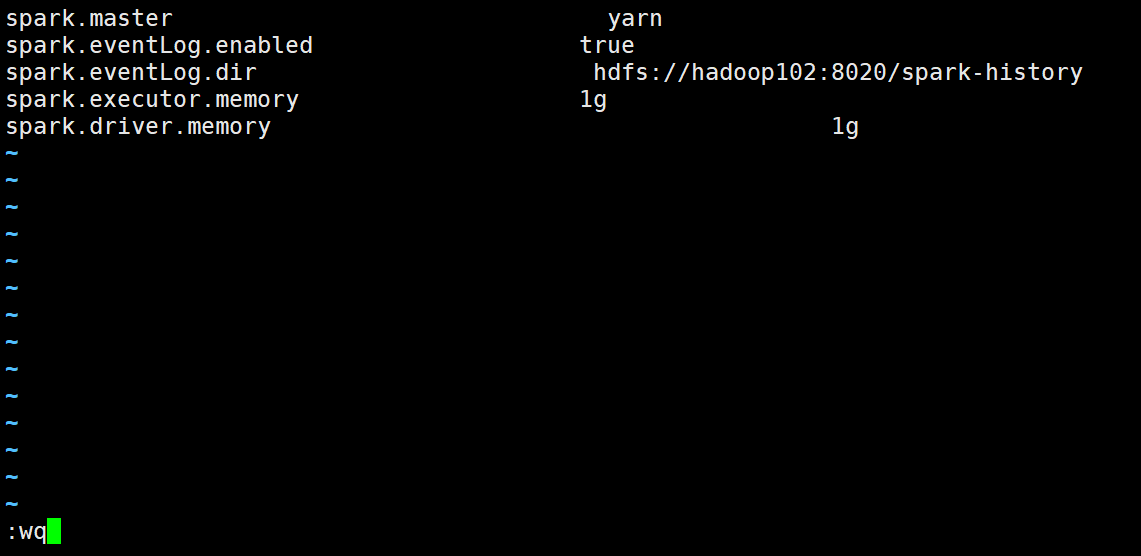
然后为了能看spark运行效果,还需要在hdfs中给一个路径,用于存储历史日志

然后又因为在安装spark时,安装的spark中就自带hadoop的jar包(因为某些spark运行需要hadoop依赖),并不是纯净版的spark的jar包,且这个自带的hadoop的jar包还自带一些hive的jar包;直接使用会和安装的Hive3.1.2出现兼容性问题。所以采用Spark纯净版jar包,不包含hadoop和hive相关依赖,避免冲突。
这里展示下怎么在官网下载纯净版spark,进入官网后点击Downloads
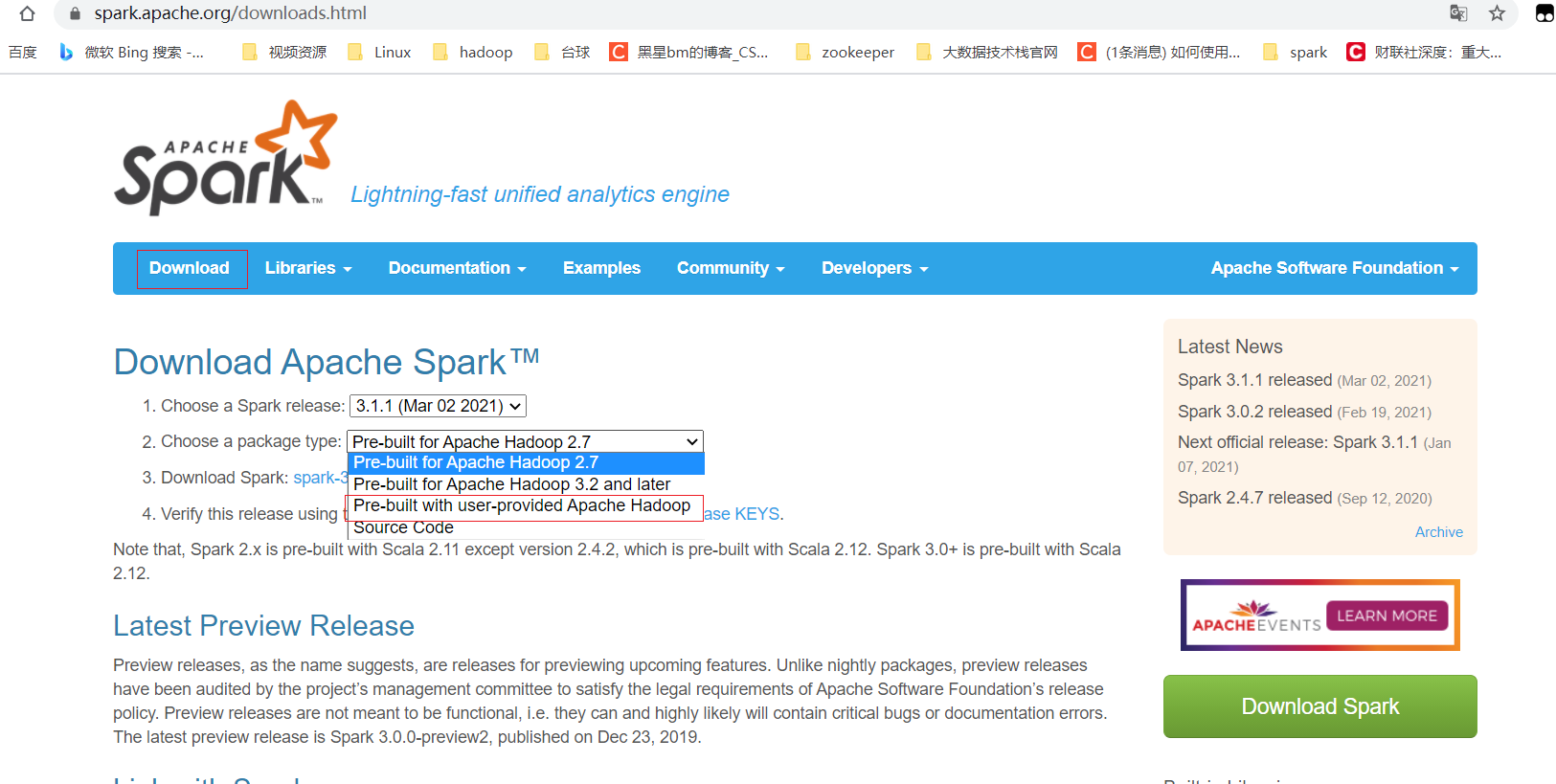
选择需要用户提供hadoop依赖的这个版本,可以看到底下有一个没hadoop依赖的jar包

解压后将这个没hadoop依赖的spark包下的jars包传给hive,那么怎么能传给hive让它使用呢。因为Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。并且在hive的配置文件中设置路径为这个依赖。
首先在hdfs中创建目录

然后将纯净的spark的jars依赖上传到hdfs上的spark-jars

然后检查下是否导入成功
可以看见有146条,但是我们在linux中可以通过wc -l可以检查条数发现是147条

这是因为我们通过ll显示时,会在最上面自动添加一条信息总容量
所以纯净版spark依赖顺利导入到hdfs
然后我们要修改hive的依赖文件,确保hive能找到纯净版spark依赖
然后我们在hive中随便创建个表,插入一条数据,让它跑一下运算引擎,测试一下是否是spark

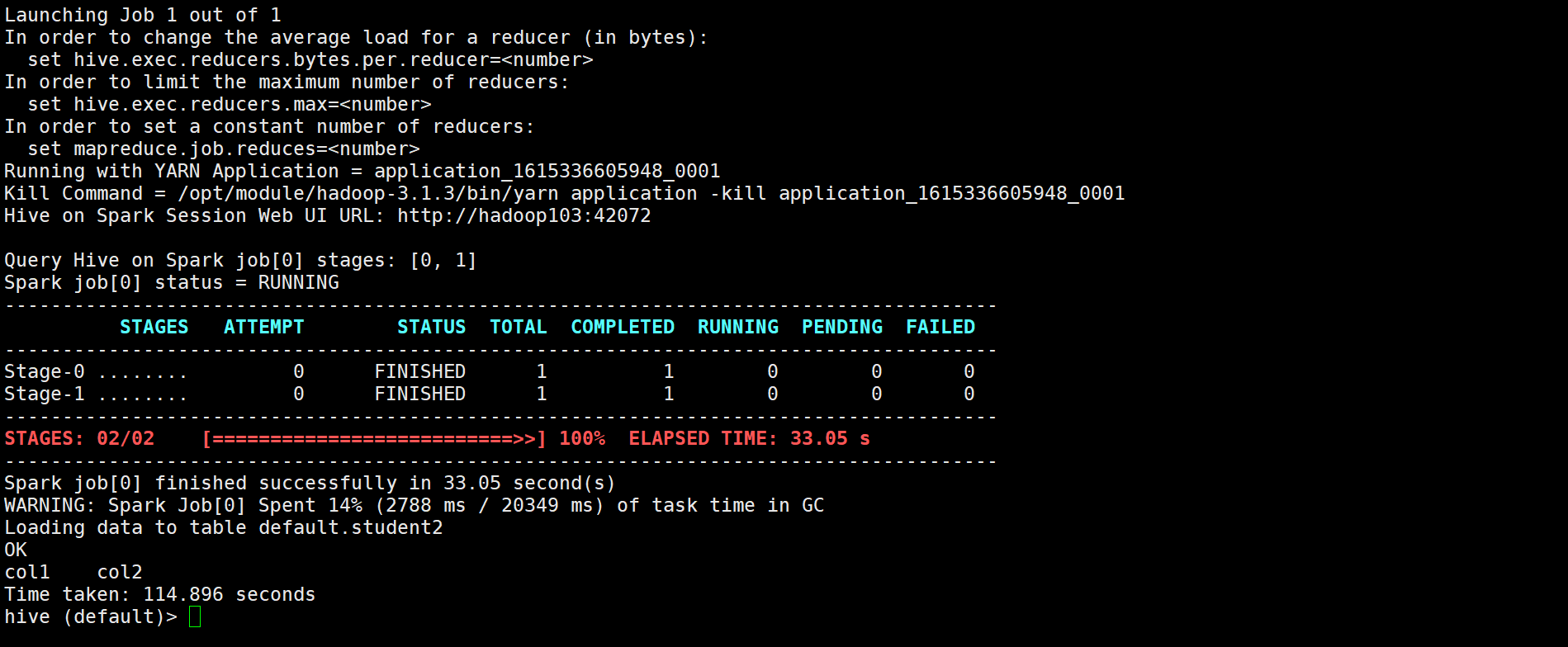
因为是第一次使用spark引擎,会建立spark session,所以用的时间会比较长;之后在使用就会很快了
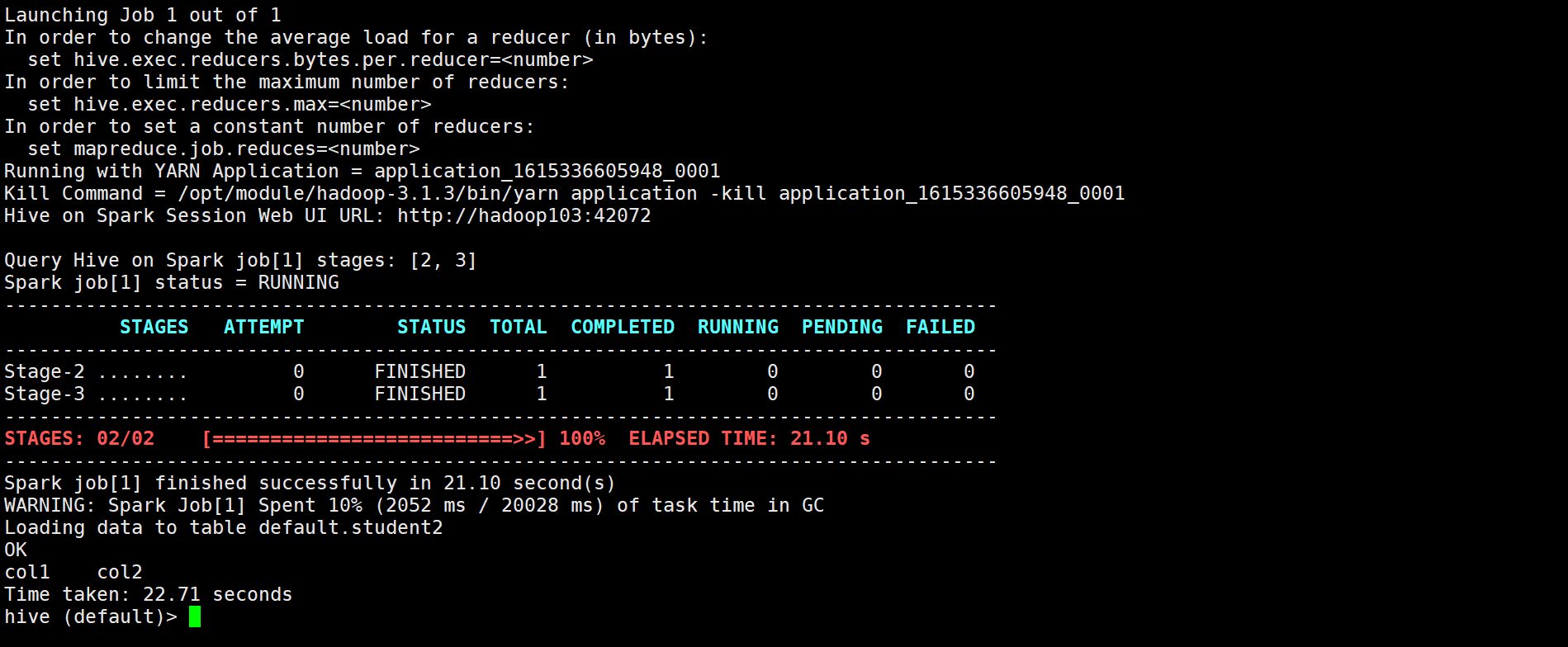
这个时候我们上yarn看一眼,可以看到hive on spark,且这个任务只要hive不关就一直占住yarn的队列,一直是running的状态,说明配置成功
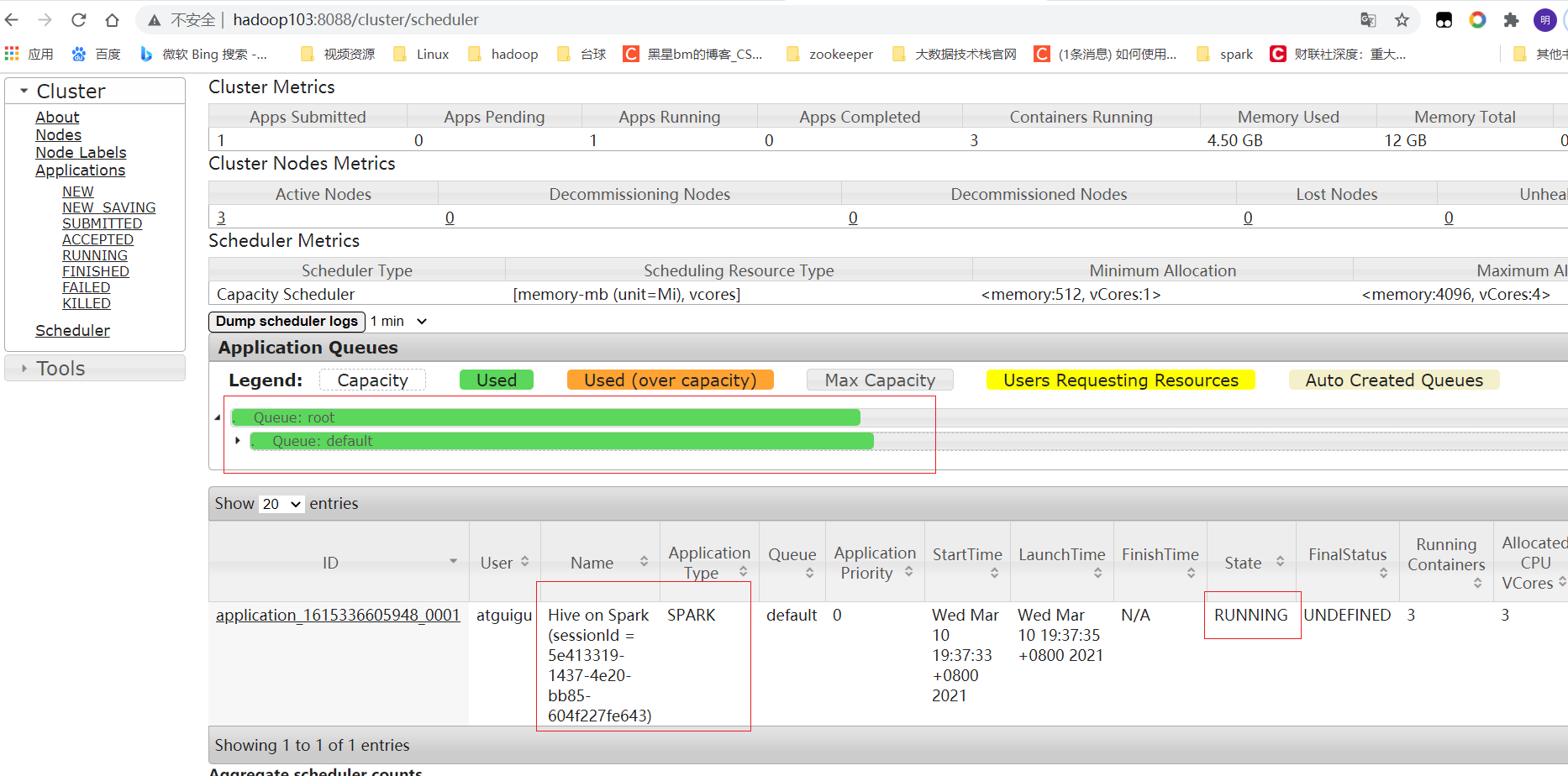
这个时候我们如果在跑一个hadoop提交MR的任务就会发现任务卡住;MR任务同样未指定队列,所以其默认也提交到了default队列,由于容量调度器单个队列的并行度为1。故后提交的MR任务会一直等待,不能开始执行。
容量调度器default队列中,同一时间只有一个任务执行,并发度低,如何解决呢?
yarn多队列问题
方案一:增加ApplicationMaster资源比例,进而提高运行app数量。
方案二:创建多队列,比如增加一个hive队列。
首先我们要明白的问题是,yarn默认的是容量调度器,也就是可以多队列调度,每个队列用的是FIFO。但是我们默认的是只有一个队列,就是FIFO。当我们的MR任务跑起来的时候,其实已经被调度了,但是没有ApplicationMaster资源去让其运行,并不是它没有被调度。一条队列即使是FIFO也能跑多个任务。
方案一:在hadoop102的/opt/module/hadoop-3.1.3/etc/Hadoop/capacity-scheduler.xml文件中修改如下参数值
yarn.scheduler.capacity.maximum-am-resource-percent
0.5
方案二:创建多队列,也可以增加容量调度器的并发度。(见ppt)
连接hive并建表
hive的配置已经没问题了,我们开始用hive连接工具,连接hive并建表。这里我们使用DataGrip这个软件连接,注意的是一个Console相当一一个客户端,在这个Console里设置的参数只在这个Console有效
这里提一个小问题
关于hive中的中文注释乱码问题解决
当我们创建hive表的时候,使用中文注释的话,通过desc查看表的信息时,会发现表的注释全是问号
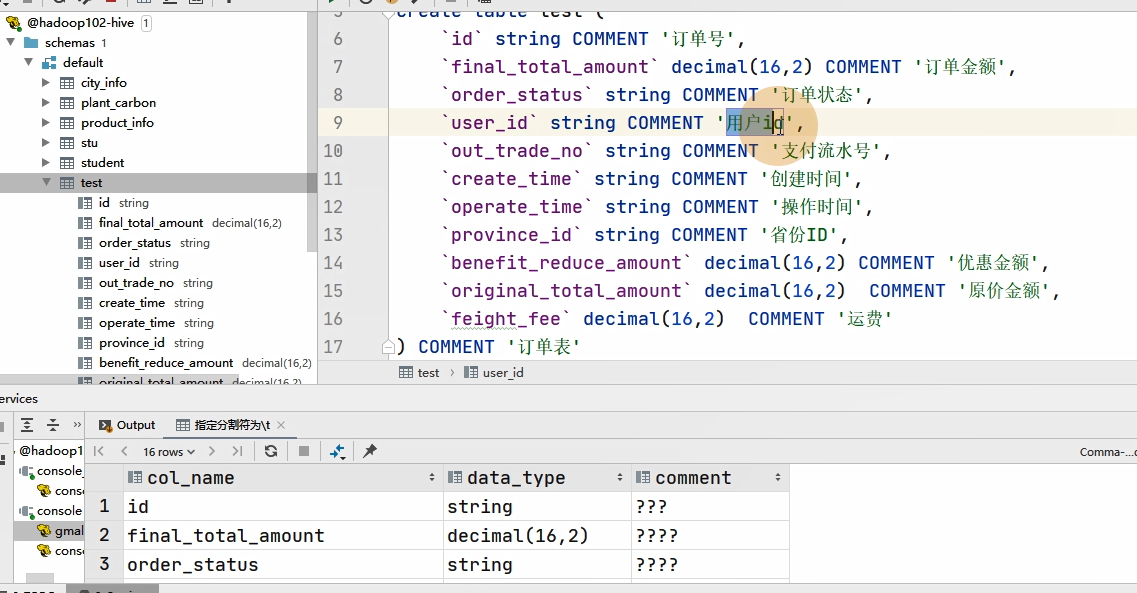
这是因为我们hive配置表的元数据放到mysql中存储,mysql中默认表被创建的时候用的是默认的字符集(latin1),所以会出现中文乱码
解决方案:
(1)在Hive元数据存储的Mysql数据库(MetaStore)中,执行以下SQL:
#修改字段注释字符集
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
#修改表注释字符集
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(20000) character set utf8;
#修改分区参数,支持分区建用中文表示
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(20000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(20000) character set utf8;
#修改索引名注释,支持中文表示
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
#修改视图,支持视图中文
ALTER TABLE TBLS modify COLUMN VIEW_EXPANDED_TEXT mediumtext CHARACTER SET utf8;
ALTER TABLE TBLS modify COLUMN VIEW_ORIGINAL_TEXT mediumtext CHARACTER SET utf8;
(2)修改hive-site.xml中Hive读取元数据的编码,在原来的配置上修改
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
注意的是,之前创建的表的元数据已经损坏了,所以无法恢复中文乱码,只能重新创建表
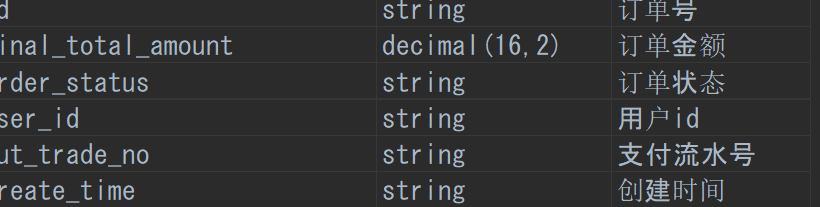
创建行为日志表ods_log
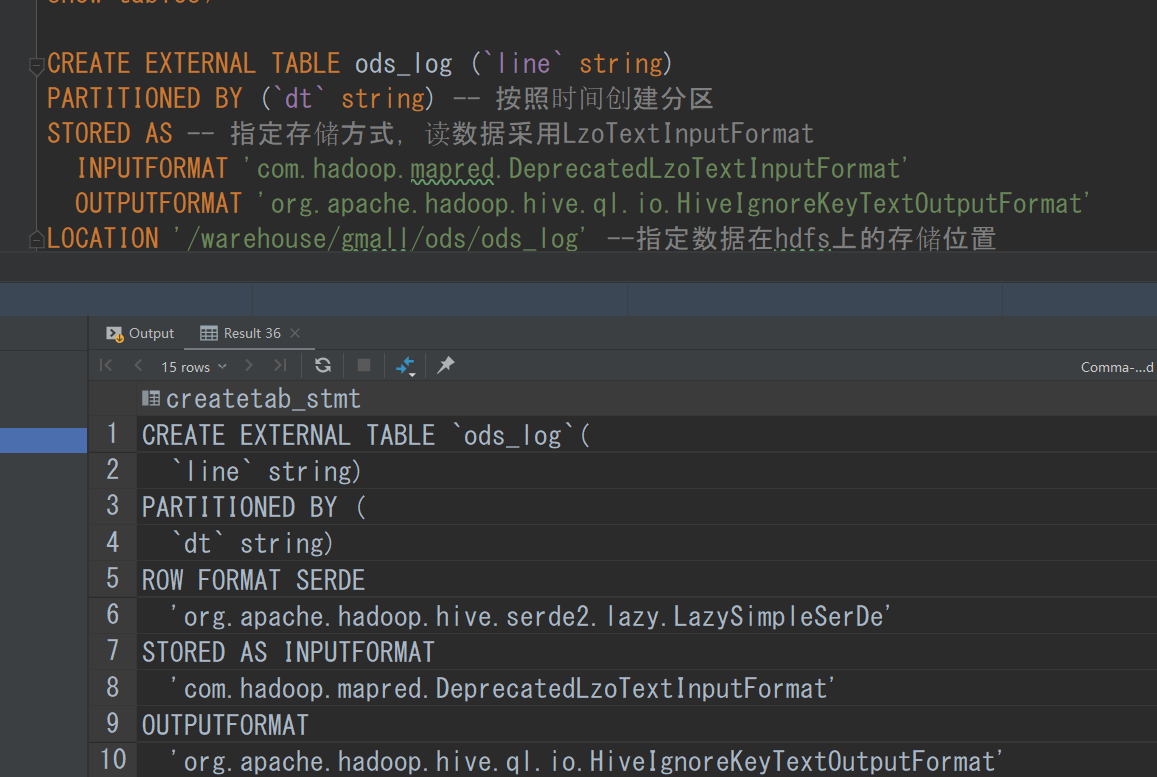
首先我们要通过创表语句创建hive的表为数据到来做准备,而log数据都是json文件,那么我们就放一个String字段,这个字段直接放整个json。并且使用时间分区表创建
drop table if exists ods_log;
CREATE EXTERNAL TABLE ods_log (`line` string)
PARTITIONED BY (`dt` string) -- 按照时间创建分区
STORED AS -- 指定存储方式,读数据采用LzoTextInputFormat
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_log' --指定数据在hdfs上的存储位置
;
解析:
(1)使用external创建外部表,保护数据
(2)PARTITIONED BY (dt string),创建时间分区表
(3)STORED AS,设定这个表load是读数据的inputformat格式和存储数据格式
(4)LOCATION 指定数据在hdfs上的存储位置
关于第三点解析:
我们可以通过 show create table 表明来查看某个表的详细数据
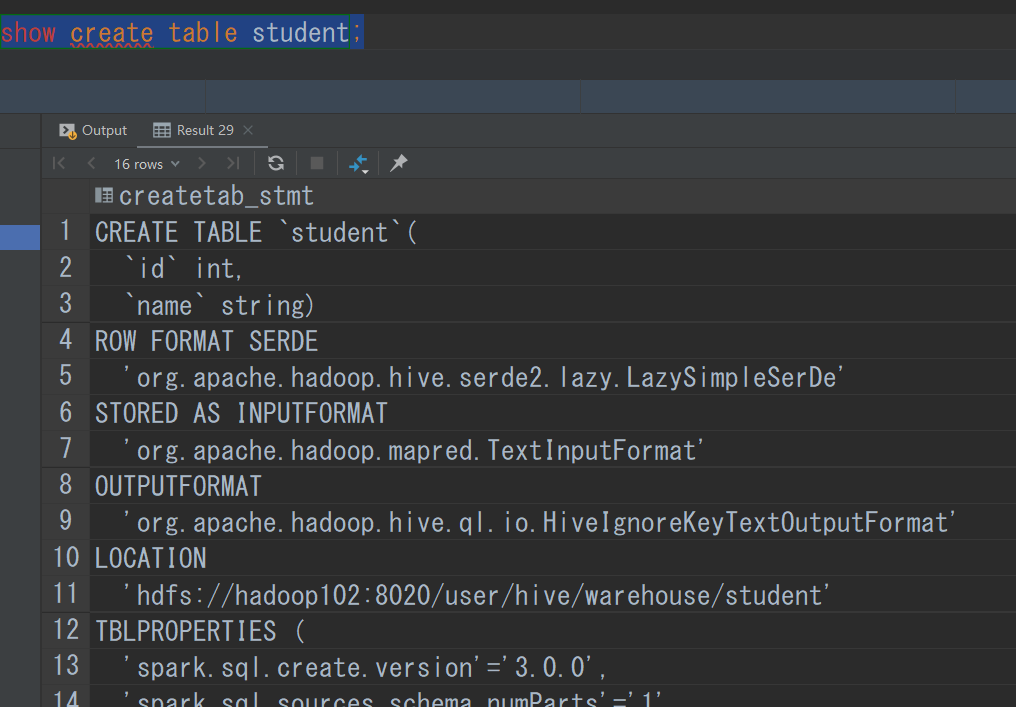
可以看见它的读取和储存数据都是text格式,也就是我们直接能读懂的方法。
但是我们在上传log数据时,使用了lzo压缩,那么怎么更改INPUTFORMAT呢?可以上官网找一下,直接搜hive lzo
第一个便是然后我们看它怎么解决的
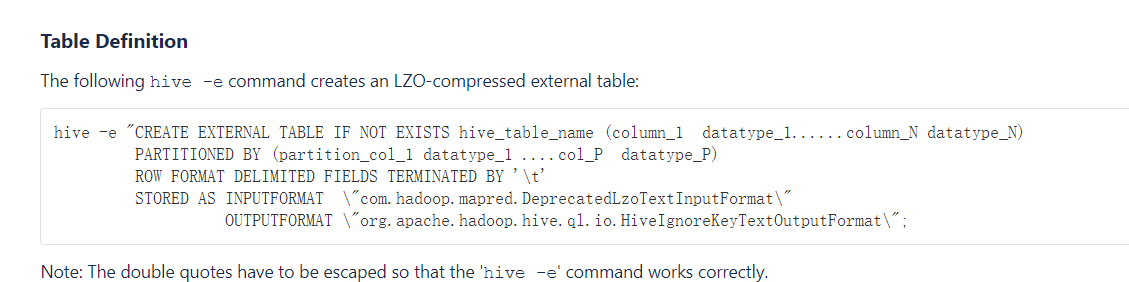
照抄即可,于是我们建好了ods_log表。
然后我们将原本在hdfs上的log数据加载进这个hive表中
load data inpath '/origin_data/gmall/log/topic_log/2020-06-14' into table ods_log partition(dt='2020-06-14');
注意:时间格式都配置成YYYY-MM-DD格式,这是Hive默认支持的时间格式
然后为lzo压缩文件创建索引
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer -Dmapreduce.job.queuename=hive /warehouse/gmall/ods/ods_log/dt=2020-06-14
那么ods层的行为数据就完事了,接下来时业务数据
创建业务数据表
首先因为我们mysql中导出的数据,所以他已经是表的格式了,那么我们再创建hive表的时候可以借鉴它的mysql表的格式,我们可以通过mysql连接工具的sql导出,来转储sql,得到它的sql建表语句
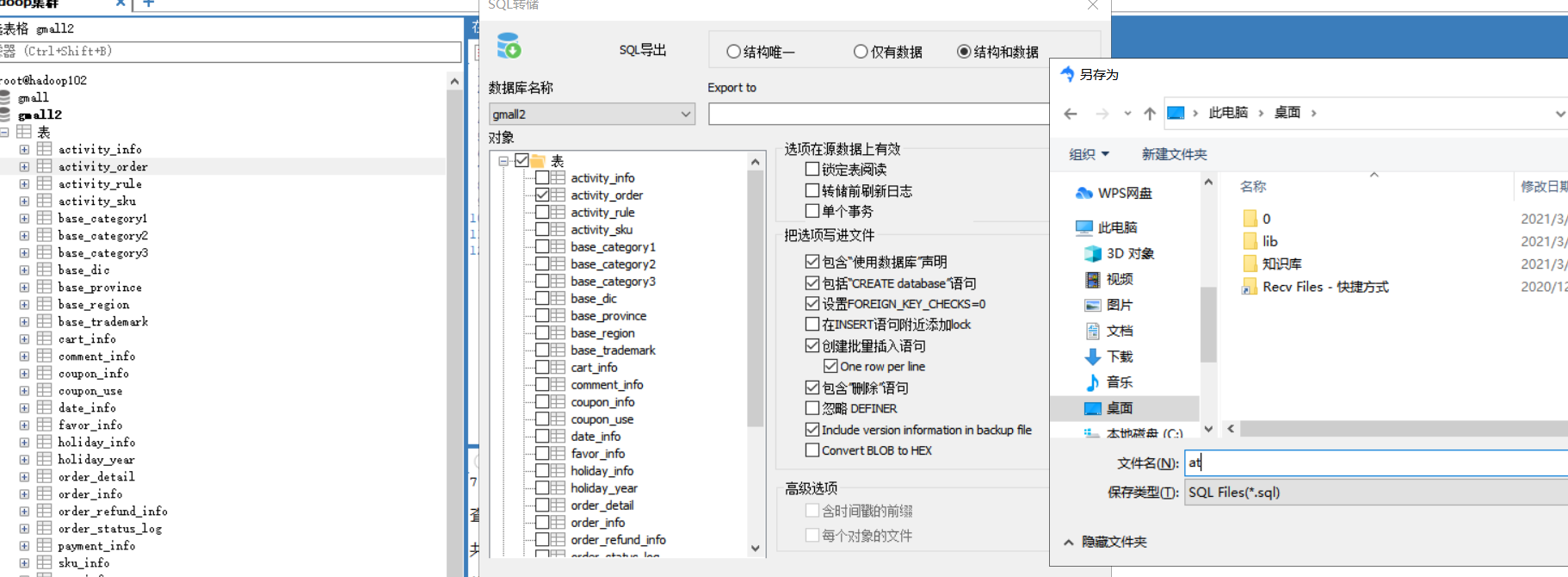
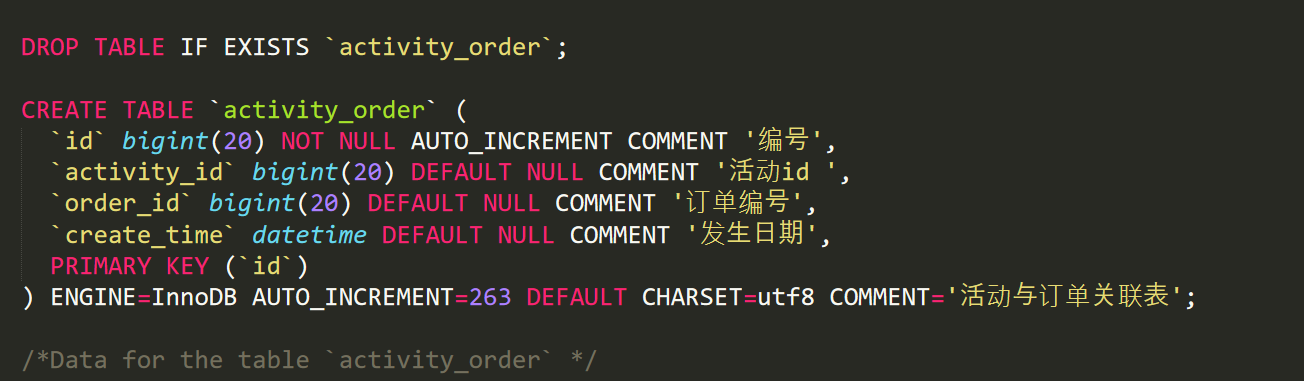
所以这就是mysql中对这个表的建表语句,完全可以借鉴到hive建表语句中
具体建表语句看ppt
然后再通过脚本将数据load上去就完成了ODS层的数仓搭建
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/188506.html原文链接:https://javaforall.net


