
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
今天我们一起来学习一下如何用Python来实现XGBoost分类,这个是一个监督学习的过程,首先我们需要导入两个Python库:
import xgboost as xgb
from sklearn.metrics import accuracy_score这里的accuracy_score是用来计算分类的正确率的。我们这个分类是通过蘑菇的若干属性来判断蘑菇是否有毒的分类,这个数据集中有126个属性,我们来看看数据集,我把数据集放到网盘上分享给大家:训练和测试数据集,密码:w8td。打开数据集可以发现这其实是一组组的向量,我们来看一组数据集的截图:
首先第一列表示标签列,是每一组数据的正确分类,1表示蘑菇是有毒的,0表示蘑菇无毒的。后面的数据,我们以第一组数据为例,3:1表示数据包含了第三组特征,其他没有不包含的特征的数据,我们就没有在数据集中显示,所以也可以把每一行看做是一个向量,这和我之前有一篇博文“SVM做文本分类详细操作流程”处理的数据格式是一样的。这里有两个数据集,一个训练集一个测试集,接下来我们读取数据集:

data_train = xgb.DMatrix('Desktop/dataset/agaricus.txt.train')
data_test = xgb.DMatrix('Desktop/dataset/agaricus.txt.test')我们来看看训练集和测试集的大小:
可以看出,除开第一列的标签列,数据集一共有126组特征,6513组训练数据和1611组测试数据。
接下来我们来指定训练的参数:

param = {
'max_depth':2, 'eta':1, 'silent':1, 'objective':'binary:logistic'}解释一下,这里max_depth: 树的最大深度。默认值是6,取值范围为:[1,∞];eta:为了防止过拟合,更新过程中用到的收缩步长。在每次提升计算之后,算法会直接获得新特征的权重。eta通过缩减特征的权重使提升计算过程更加保守。默认值为0.3,取值范围为:[0,1];silent:取0时表示打印出运行时信息,取1时表示以缄默方式运行,不打印运行时信息,默认值为0;objective: 定义学习任务及相应的学习目标,“binary:logistic” 表示二分类的逻辑回归问题,输出为概率。下面我们就可以用xgboost训练模型了:
import time
start_time = time.clock()
bst = xgb.train(param, data_train, num_round)
end_time = time.clock()
print(end_time - start_time)这里的num_round表示训练的时候迭代的次数,我们默认它是2,训练过程是相当快的,这段代码输出是训练时长:0.015257000000000076。这个时候我们用训练集做预测:
train_preds = bst.predict(data_train)
print ("train_preds",train_preds)输出是:
train_preds [0.9239239 0.28583017 0.28583017 ... 0.05169873 0.05169873 0.05169873]这些数据输出的是概率,表示的是每一组蘑菇有毒的概率,我们再将这些数据分类:
train_predictions = [round(value) for value in train_preds]
print ("train_predictions",train_predictions)分类之后的输出是:
train_predictions [1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, ... 1.0, 0.0, 0.0, 0.0]这里输出全部都是0和1了,这就是我们用训练数据集训练出的结果,我们可以将这个结果与训练集中的标签作比较,来看看这个预测的准确率如何:
y_train = data_train.get_label()
print ("y_train",y_train)这是我们获取训练数据集的标签,再与我们训练出的结果进行比较:
train_accuracy = accuracy_score(y_train, train_predictions)
print ("Train Accuary: %.2f%%" % (train_accuracy * 100.0))结果是Train Accuary: 97.77%,准确率还可以。同理,我们可以用测试集来验证我们的模型如何:
# make prediction
preds = bst.predict(data_test)
predictions = [round(value) for value in preds]
y_test = data_test.get_label()
test_accuracy = accuracy_score(y_test, predictions)
print("Test Accuracy: %.2f%%" % (test_accuracy * 100.0))我们可以得到Test Accuracy: 97.83%,这可以说明我们用训练集训练出来的模型还是不错的。
以上是我们用xgboost对数据进行分类模型训练的全过程,接着,我们还可以对这个模型输出它的决策树:
from matplotlib import pyplot
import graphviz
xgb.plot_tree(bst, num_trees = 0,rankdir = 'LR')
pyplot.show()这里解释一下,xgb.plot_tree()方法的第一个参数表示模型,第二个参数表示树的索引是从0开始的,其实还可以填第三个参数:rankdir = ‘LR’,’LR’表示水平方向,默认的是垂直方向。
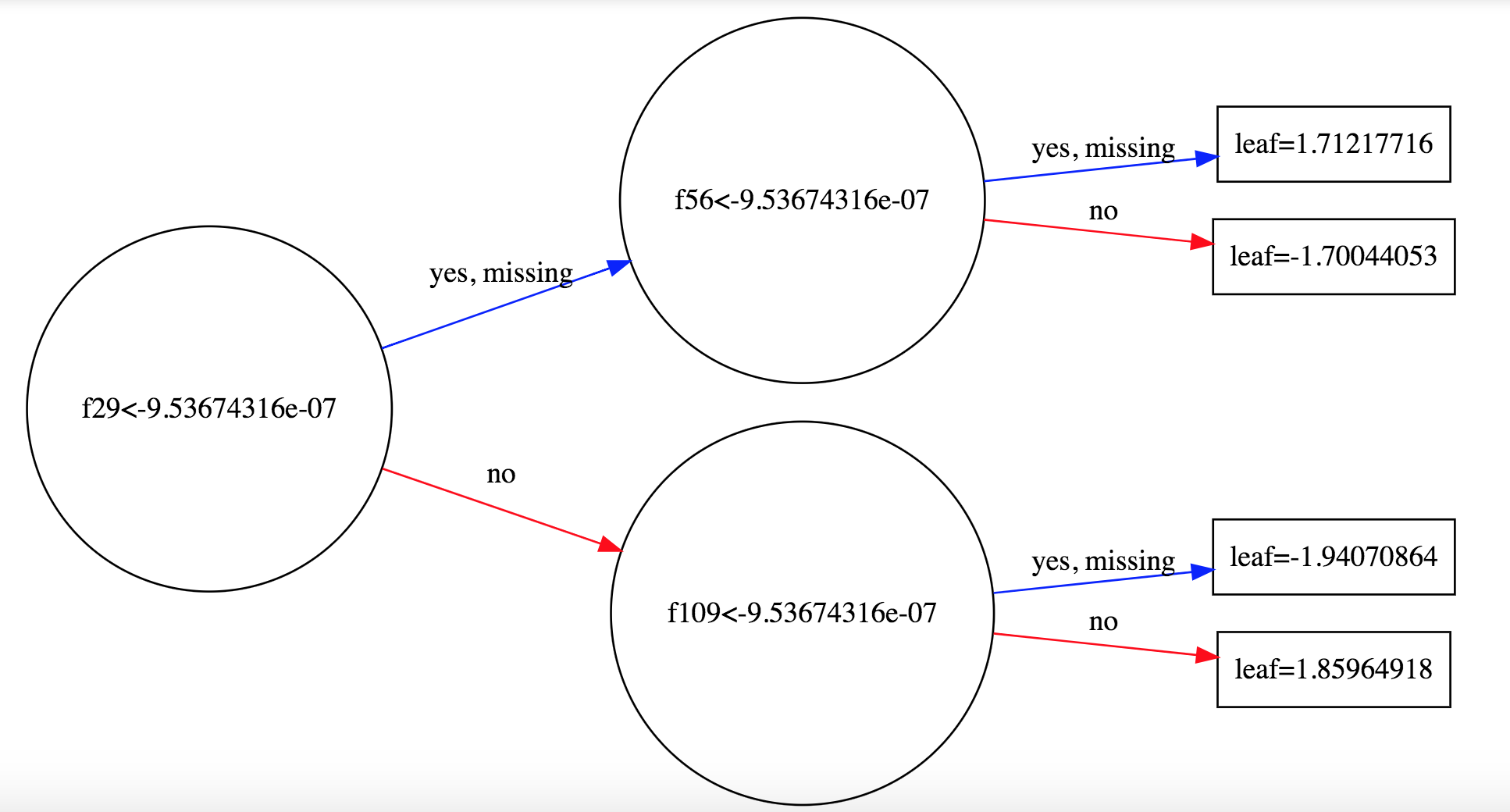
我们可以得到这个模型的决策树:
这个决策树节点中的f29表示的是数据集中的第29个特征。
以上就是我们用Python实现的xgboost分类模型的过程,希望对各位朋友有所帮助,本人能力有限,文中如有纰漏之处,还望各位朋友多多指教,如有转载,也请标明出处,谢谢。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/188611.html原文链接:https://javaforall.net


