
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
又到整理的时候了,这次参考torchvision里面的resnet34源代码,自己修改了一下,实现cifar10数据集的分类任务。
其实网络上已经有很多优秀的源代码了,没必要再写,如果执意要说个理由的话,就当是自己的笔记了哈哈,方便以后使用可以快速查阅。没别的,菜鸟就应该多积累。
ResNet34大体结构:


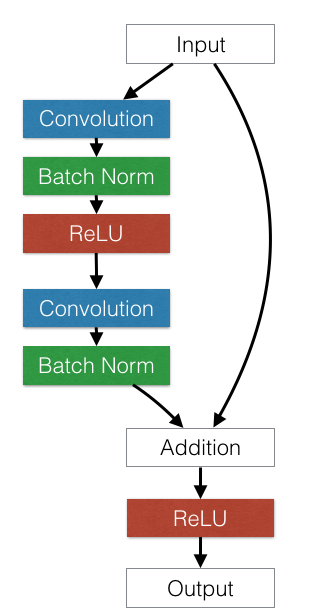
图片:来自《深度学习框架PyTorch:入门与实践》
PyTorch 使用 torchvision 自带的 CIFAR10 数据实现。
运行环境:pytorch 0.4.0 CPU版、Python 3.6、Windows 7
import torchvision as tv
import torchvision.transforms as transforms
from torch import nn
import torch as t
from torch import optim
from torch.nn import functional as F
t.set_num_threads(8)
class ResidualBlock(nn.Module):
# 实现子module: Residual Block
def __init__(self, inchannel, outchannel, stride=1, shortcut=None):
super(ResidualBlock, self).__init__()
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, 3, stride, 1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, 3, 1, 1, bias=False),
nn.BatchNorm2d(outchannel))
self.right = shortcut
def forward(self, x):
out = self.left(x)
residual = x if self.right is None else self.right(x)
out += residual
return F.relu(out)
class ResNet(nn.Module):
# 实现主module:ResNet34
# ResNet34 包含多个layer,每个layer又包含多个residual block
# 用子module来实现residual block,用_make_layer函数来实现layer
def __init__(self, num_classes=1000):
super(ResNet, self).__init__()
# 前几层图像转换
self.pre = nn.Sequential(
nn.Conv2d(3, 16, 3, 1, 1, bias=False),
nn.BatchNorm2d(16),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2, 1))
# 重复的layer,分别有3,4,6,3个residual block
self.layer1 = self._make_layer(16, 16, 3)
self.layer2 = self._make_layer(16, 32, 4, stride=1)
self.layer3 = self._make_layer(32, 64, 6, stride=1)
self.layer4 = self._make_layer(64, 64, 3, stride=1)
self.fc = nn.Linear(256, num_classes) # 分类用的全连接
def _make_layer(self, inchannel, outchannel, block_num, stride=1):
# 构建layer,包含多个residual block
shortcut = nn.Sequential(nn.Conv2d(inchannel, outchannel, 1, stride, bias=False), nn.BatchNorm2d(outchannel))
layers = []
layers.append(ResidualBlock(inchannel, outchannel, stride, shortcut))
for i in range(1, block_num):
layers.append(ResidualBlock(outchannel, outchannel))
return nn.Sequential(*layers)
def forward(self, x):
x = self.pre(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = F.avg_pool2d(x, 7)
x = x.view(x.size(0), -1)
return self.fc(x)
def getData(): # 定义对数据的预处理
transform = transforms.Compose([
transforms.Resize(40),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32),
transforms.ToTensor()])
trainset = tv.datasets.CIFAR10(root='./data/', train=True, download=True, transform=transform) # 训练集
trainloader = t.utils.data.DataLoader(trainset, batch_size=4, shuffle=True)
testset = tv.datasets.CIFAR10('./data/', train=False, download=True, transform=transform) # 测试集
testloader = t.utils.data.DataLoader(testset, batch_size=4, shuffle=False)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
return trainloader, testloader, classes
def trainModel(): # 训练模型
trainloader, testloader, _ = getData() # 获取数据
net = ResNet(10)
print(net)
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # 定义优化器
for epoch in range(1):
for step, (tx, ty) in enumerate(trainloader, 0):
optimizer.zero_grad() # 梯度清零
py = net(tx) # forward + backward
loss = criterion(py, ty)
loss.backward()
optimizer.step() # 更新参数
if step % 10 == 9: # 每2000个batch打印一下训练状态
acc = testNet(net, testloader)
print('Epoch:', epoch, '|Step:', step, '|train loss:%.4f' % loss.item(), '|test accuracy:%.4f' % acc)
print('Finished Training')
return net
def testNet(net, testloader): # 获取在测试集上的准确率
correct, total = .0, .0
for x, y in testloader:
net.eval()
py = net(x)
_, predicted = t.max(py, 1) # 获取分类结果
total += y.size(0) # 记录总个数
correct += (predicted == y).sum() # 记录分类正确的个数
return float(correct) / total
if __name__ == '__main__':
trainModel()欢迎指正哦
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/189465.html原文链接:https://javaforall.net


