kworkers_work为什么名词1.简介: 在spi驱动中用到了内核的线程,用的函数就是跟kthread_worker和kthread_work相关的函数,对于这两个名词的翻译,在网上暂时没有找到合适的,先翻译成线程内核线程相关的:工人和工作,这么直白的翻译是根据其工作原理相关的,本来想翻译成别的,一想到他的实现方式,直白的翻译,更能让人理解。 此部分介绍的函数主要在inc
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
1. 简介:
在spi驱动中用到了内核的线程,用的函数就是跟 kthread_worker 和 kthread_work 相关的函数,对于这两个名词的翻译,在网上暂时没有找到合适的,先翻译成线程内核线程相关的:工人和工作,这么直白的翻译是根据其工作原理相关的,本来想翻译成别的,一想到他的实现方式,直白的翻译,更能让人理解。
此部分介绍的函数主要在 include/linux/kthread.h 文件,这里可以推测,也许是内核为了方便我们使用内核的线程,而设计的kthread_work和kthread_worker。
2. 函数:
2.1 先来看这两个结构体:
kthread_worke和
kthread_worker:
- struct kthread_worker {
- spinlock_t lock;
- struct list_head work_list;
- struct task_struct *task;
- struct kthread_work *current_work;
- };
-
- struct kthread_work {
- struct list_head node;
- kthread_work_func_t func;
- wait_queue_head_t done;
- struct kthread_worker *worker;
- };
【1】其中的 wait_queue_head_t 结构体需要解析一下:
- struct __wait_queue_head {
- spinlock_t lock;
- struct list_head task_list;
- };
- typedef struct __wait_queue_head wait_queue_head_t;
2.2 声明:
DEFINE_KTHREAD_WORK宏和
DEFINE_KTHREAD_WORKER宏:
- #define KTHREAD_WORKER_INIT(worker) { \
- .lock = __SPIN_LOCK_UNLOCKED((worker).lock), \
- .work_list = LIST_HEAD_INIT((worker).work_list), \
- }
-
- #define KTHREAD_WORK_INIT(work, fn) { \
- .node = LIST_HEAD_INIT((work).node), \
- .func = (fn), \
- .done = __WAIT_QUEUE_HEAD_INITIALIZER((work).done), \
- }
-
- #define __WAIT_QUEUE_HEAD_INITIALIZER(name) { \
- .lock = __SPIN_LOCK_UNLOCKED(name.lock), \
- .task_list = { &(name).task_list, &(name).task_list } }
-
- #define DEFINE_KTHREAD_WORKER(worker) \
- struct kthread_worker worker = KTHREAD_WORKER_INIT(worker)
-
- #define DEFINE_KTHREAD_WORK(work, fn) \
- struct kthread_work work = KTHREAD_WORK_INIT(work, fn)
2.3 初始化
init_kthread_work宏和
init_kthread_worker宏:
- #define init_kthread_worker(worker) \ // 初始化 kthread_worker
- do { \
- static struct lock_class_key __key; \
- __init_kthread_worker((worker), “(“#worker“)->lock”, &__key); \
- } while (0)
-
- #define init_kthread_work(work, fn) \ // 初始化 kthread_work
- do { \
- memset((work), 0, sizeof(struct kthread_work)); \
- INIT_LIST_HEAD(&(work)->node); \
- (work)->func = (fn); \
- init_waitqueue_head(&(work)->done); \
- } while (0)
-
- void __init_kthread_worker(struct kthread_worker *worker,
- const char *name,
- struct lock_class_key *key)
- {
- spin_lock_init(&worker->lock);
- lockdep_set_class_and_name(&worker->lock, key, name);
- INIT_LIST_HEAD(&worker->work_list);
- worker->task = NULL;
- }
2.4 内核线程一直执行的函数
kthread_worker_fn函数:
-
-
-
-
- int kthread_worker_fn(void *worker_ptr)
- {
- struct kthread_worker *worker = worker_ptr;
- struct kthread_work *work;
-
- WARN_ON(worker->task);
- worker->task = current;
- repeat:
- set_current_state(TASK_INTERRUPTIBLE);
-
- if (kthread_should_stop()) {
- __set_current_state(TASK_RUNNING);
- spin_lock_irq(&worker->lock);
- worker->task = NULL;
- spin_unlock_irq(&worker->lock);
- return 0;
- }
-
- work = NULL;
- spin_lock_irq(&worker->lock);
- if (!list_empty(&worker->work_list)) {
- work = list_first_entry(&worker->work_list,
- struct kthread_work, node);
- list_del_init(&work->node);
- }
- worker->current_work = work;
- spin_unlock_irq(&worker->lock);
-
- if (work) {
- __set_current_state(TASK_RUNNING);
- work->func(work);
- } else if (!freezing(current))
- schedule();
-
- try_to_freeze();
- goto repeat;
- }
【1】可以看到,这个函数的关键就是重复的执行kthread_worker结构体中的work_list链表锁挂接的kthread_work中的func函数,直到work_list变为空为止。
【2】要知道的是kthread是内核线程,是一直运行在内核态的线程
【3】这个函数一般是作为回调函数使用,比如spi.c中的如下程序
- master->kworker_task = kthread_run(kthread_worker_fn,
- &master->kworker,
- dev_name(&master->dev));
-
-
-
-
-
-
-
-
-
-
- #define kthread_run(threadfn, data, namefmt, …) …(此处省略)
2.5 队列化kthread_work
queue_kthread_work 函数:
-
-
-
-
-
-
-
-
-
- bool queue_kthread_work(struct kthread_worker *worker,
- struct kthread_work *work)
- {
- bool ret = false;
- unsigned long flags;
-
- spin_lock_irqsave(&worker->lock, flags);
- if (list_empty(&work->node)) {
- insert_kthread_work(worker, work, &worker->work_list);
- ret = true;
- }
- spin_unlock_irqrestore(&worker->lock, flags);
- return ret;
- }
-
-
- static void insert_kthread_work(struct kthread_worker *worker,
- struct kthread_work *work,
- struct list_head *pos)
- {
- lockdep_assert_held(&worker->lock);
-
- list_add_tail(&work->node, pos);
- work->worker = worker;
- if (likely(worker->task))
- wake_up_process(worker->task);
- }
2.6 执行完worker中的work
flush_kthread_worker 函数:
- struct kthread_flush_work {
- struct kthread_work work;
- struct completion done;
- };
-
- static void kthread_flush_work_fn(struct kthread_work *work)
- {
- struct kthread_flush_work *fwork =
- container_of(work, struct kthread_flush_work, work);
- complete(&fwork->done);
- }
-
-
-
-
-
-
-
-
- void flush_kthread_worker(struct kthread_worker *worker)
- {
- struct kthread_flush_work fwork = {
- KTHREAD_WORK_INIT(fwork.work, kthread_flush_work_fn),
- COMPLETION_INITIALIZER_ONSTACK(fwork.done),
- };
-
- queue_kthread_work(worker, &fwork.work);
- wait_for_completion(&fwork.done);
- }
【1】如何就flush了呢?看2.7的总结
2.7 总结的一张图:
说了半天,其实woker和work的关系还是很难理解的,当我们经过一段时间,再次看的时候,难免还要花很长时间,因此,我画了一张图:
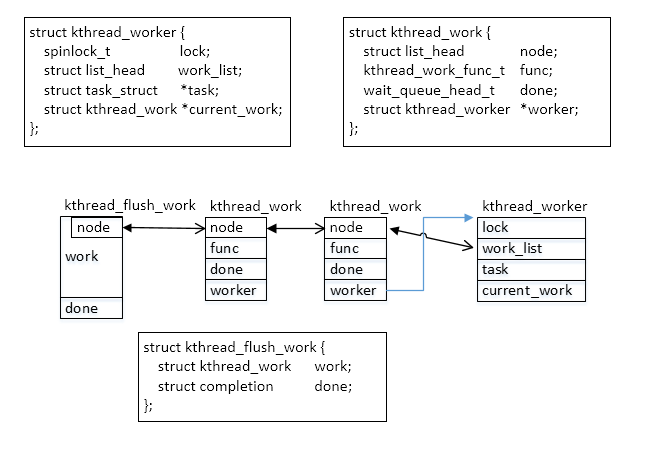

【1】worker中的task执行的是各自work中的func指定的函数,此规则同样适用于kthread_flush_work
【2】kthread_flush_work中的函数是kthread.c文件指定的函数,而kthread_work中的函数是用户自己定义的函数
【3】每次唤醒线程执行的work都是worker中的work_list下挂载的正常顺序的第一个
【4】如何实现等待全部的work都执行完呢?调用的是flush_kthread_worker函数中的wait_for_completion(&fwork.done);语句,只有当前边的work都执行完,才能轮到kthread_flush_work中的kthread_flush_work_fn的执行,此函数就是唤醒kthread_flush_work中的done。从而确定了前边的work都执行完了
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/189765.html原文链接:https://javaforall.net



