
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
小伙伴想精准查找自己想看的MySQL文章?喏 → MySQL江湖路 | 专栏目录


提到唯一索引和普通索引,相信大家都不陌生,当同事小姐姐问你这俩有什么区别时?或许你会脱口而出:“这还用问?见名知意啊,一个是允许字段重复,一个不允许存在重复数据!”
是否解决小姐姐的疑问我不知道,但你在同事心目中,肯定不是啥好玩意儿~ 要知道,一眼就看出的答案,一般不会有人问,除非问傻子~
那么当你处理一张市民信息表时,其中一列为市民的身份证号信息,你会怎么选择哪个索引?为什么?
对于一个经历过风风雨雨、日日夜夜的程序员来说,需要你考虑的东西可不仅是重不重复这类问题,而是…

开个玩笑~~应当结合实际情况,对各个场景进行综合考虑。
其实,如果在业务代码中保证了不会写入重复的身份证号,那么这两个选择逻辑上都是正确的。但是在SELECT和DML场景中,唯一索引和普通索引却有很多不同。
1、在SELECT中,唯一索引和普通索引的区别
本文测试引擎选择我们最常用的InnoDB,版本为MySQL8.0;
假设,执行查询的语句是:
select id from T where id_card = 666;
(身份证太长,咱们用简单数据做演示)我们知道,MySQL的InnoDB采用的是B+树实现的索引结构,查找过程从B+树的树根起,按层搜索到666所在的叶子节点,然后取出该节点所在的数据页,把数据页读到内存后,通过二分法在数据页中定位id_card=666的行数据。
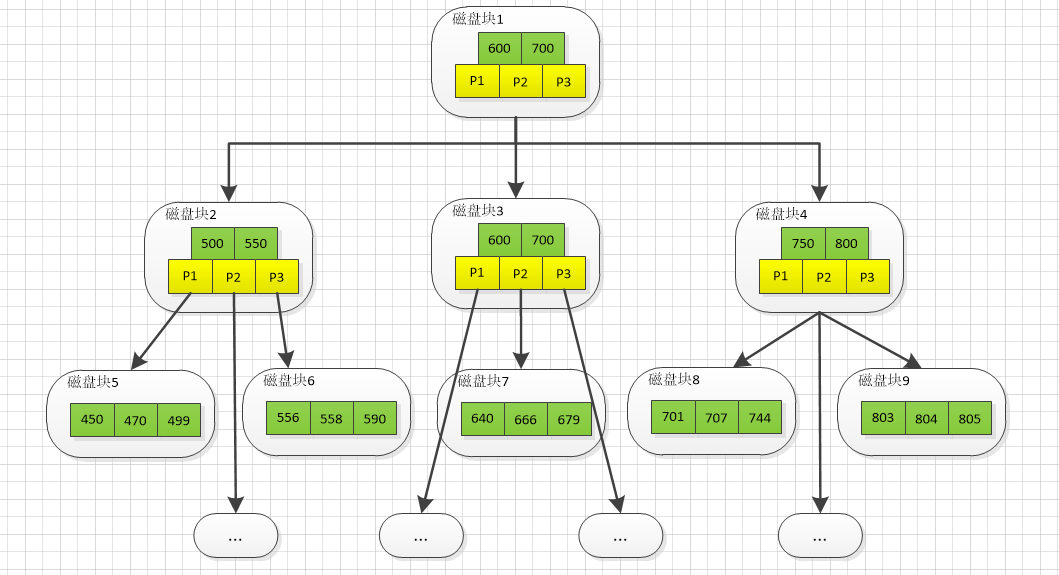
B+ 树的查找过程如上图:
将磁盘块1从磁盘加载到内存,发生一次IO ,在内存中使用二分查找方式找到 666 在600和700 之间,锁定磁盘块1的P2 指针。- 通过磁盘块1 的 P2 指针地址把
磁盘块3 加载到内存,发生第二次IO ,锁定磁盘块3 的 P2 指针 - 通过磁盘块3 的P2指针加载
磁盘块7到内存,发生第三次 IO,同时根据二分查找找到666 查询结束。
普通索引和唯一索引的定位方式:
- 普通索引:查到第一条id_card=666 后,然后继续往后查找直到碰到第一个
id_card<>666的记录时,结束。 - 唯一索引:由于索引定义了唯一性,查找到第一个满足条件的记录后,直接结束。
两者在查询方面的性能差距微乎其微。对于普通索引多的那一次操作,因为本身就是以数据页为单位读进内存,数据页大小默认16KB(大概1000行),要多做的那一次“查找和判断下一条记录”的操作,就只需要一次指针寻找和一次计算。当然,不可避免查询的数据是该数据页的最后一位,这样还要再读下一块数据页,算法会复杂一些。
但你知道的,这种概率很小,我们程序员要相信逆墨菲定律:大概率不会出现且未被发现的BUG,在难以改动的前提下,你就当不知道就完了,发生了又能咋地?有测试顶着呢!
有同学问我了:
普通索引为什么要继续向下查找?继续向下查找的原因是由于普通索引允许重复值,且B+Tree是天然有序的。SQL中并没有指定limit 1,所以他还要往下查,看是否有同条件的数据一起返回,直到查到第一条不满足条件的数据为止。
2、在DML中,唯一索引和普通索引的区别
ding!这是本篇文章的重点,在看之前,我们需要先了解什么是change buffer。
了解MySQL机制的同学们知道,当执行 DML(INSERT、UPDATE、DELETE)等操作时,InnoDB会利用 change buffer进行加速写操作,可以将写操作的随机磁盘访问调整为局部顺序操作,而在机械硬盘时代,随机磁盘访问(随机I/O)也是数据库操作中的最耗性能的硬伤。当普通索引(非唯一索引)的数据页发生写操作时,把操作内容写到内存中的change buffer后就可以立刻返回(执行完成)了。
这里我以UPDATE操作为例,当需要更新某一行数据时,会先判断该行所在数据页是否在内存中,如果在就直接在内存数据页中更新,如果这个数据页没有内存中的话,在不影响数据一致性的前提下,InnoDB 会将这些UPDATE操作缓存在 change buffer 中,这样就不需要从磁盘读入数据页,当有SQL查询需要访问这个数据页的数据时,将数据页读入内存后,然后先执行 change buffer 中与这个页的相关UPDATE操作,通过这种方式保证这个数据页的逻辑正确性。

可见,change buffer是会被从内存持久化到磁盘中的,将 change buffer 中的操作应用到原数据页,得到最新结果的过程被称为 merge。除了访问这个数据页会触发 merge 外,系统有后台线程会定期 merge。在数据库正常关闭(shutdown)的过程中,也会执行 merge 操作,相当于刷脏页啦(把已修改的数据更新到实际数据文件中)。
触发merge的操作主要有以下几种(你该记住的点):
- 有SQL线程访问这个数据页;
- master thread线程每秒或每10秒进行一次
merge change buffer的操作; - 在数据库正常关闭的时候。
小朋友,你是否有很多问号??DB服务器宕机,数据不是就丢了?这就得redo log + binlog来保证了,可以参考作者另一篇文章《听我讲完redo log、binlog原理,面试官老脸一红》,本篇不再赘述。
跑远了?言归正传~~上文提到普通索引(非唯一索引)会使用到change buffer进行加速写操作,你是不是已经get到点了呢~
是的,唯一索引不会使用 Change buffer ,如果索引设置了唯一属性,在进行插入或者修改操作时,InnoDB 必须进行唯一性检查,如果不读取索引页到缓冲池,无法校验索引是否唯一,如果都把索引页读到内存了,那直接更新内存会更快,就没必要使用change buffer了。
-
对于普通索引(非唯一索引)的DML操作来说,当待更新的数据页在内存中时,找到前值和后值的区间插入即可;当待更新的数据页在不在内存中时,直接把操作写到Change buffer就完事儿了。舒服! -
而
对于唯一索引,当待更新的数据页在不在内存中时,索引每次都得把数据页读到内存中判断唯一性,将数据从磁盘读入内存涉及大量随机IO的访问,慢的一批,当遇到高频写操作时??唉,别想了,难受!
到这里,相信你对普通索引和唯一索引的取舍有了一定的概念,普通索引和唯一索引在查询能力上是没差别的,主要考虑的是更新的影响。还得结合实际业务场景来判断,如果是读取远大于更新和插入的表,唯一索引和普通索引都可以,但是如果业务需求相反,个人觉得应该使用普通索引,当然如果是那种更新完要求立即可见的需求,就是刚更新完就要再查询的,这种情况下反而不推荐普通索引,因为这样会频繁的产生merge操作,起不到change buffer的作用,反而需要额外空间来维护change buffer就有点得不偿失了。
当我们使用普通索引,尤其在使用机械盘的场景下,尽量把change buffer开大从而确保数据的写入速度。最后,通过列举一下 change buffer 的配置,结束今天的分享,相信看到这里的都是有心人,也是喜爱MySQL的崽子,记得不要吝啬你的点赞哦~~

change buffer 配置
- innodb_change_buffer_max_size% 配置写缓冲的大小,占整个缓冲池的比例,默认值是25%,可以通过修改该值提高InnoDB写效率,最大值是50%。
mysql> show variables like '%innodb_change_buffer_max_size%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| innodb_change_buffer_max_size | 25 |
+-------------------------------+-------+
1 row in set (0.00 sec)
- innodb_change_buffering配置是否缓存辅助索引页的修改,默认为 all,即缓存 INSERT/DELETE/UPDATE等DML操作。
mysql> show variables like '%innodb_change_buffering%';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| innodb_change_buffering | all |
+-------------------------+-------+
1 row in set (0.00 sec)
MySQL系列文章汇总与《MySQL江湖路 | 专栏目录》
往期热门MySQL系列文章:
- 原创 | MySQL中特别实用的几种SQL语句送给大家
- 原创 | SQL优化最干货总结 – MySQL(2020最新版)
- 原创 | 为什么大家都说SELECT * 效率低
- 原创 | 面试让HR都能听懂的MySQL锁机制,欢声笑语中搞懂MySQL锁
- 原创 | MySQL中的 utf8 并不是真正的UTF-8编码 ! !
- 原创 | MySQL数据中有很多换行符和回车符!!该咋办?
- 原创 | delete后加 limit是个好习惯么
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/191563.html原文链接:https://javaforall.net


