
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
一、背景简介
ByteBuf,顾名思义,就是字节缓冲区,是Netty中非常重要的一个组件。熟悉jdk NIO的同学应该知道ByteBuffer,正是因为jdk原生ByteBuffer使用比较复杂,某些场景下性能不是太好,netty开发团队重新设计了ByteBuf用以替代原生ByteBuffer。
二、ByteBuf和ByteBuffer对比
下面用图示来展示ByteBuf和ByteBuffer工作原理:
①、ByteBuffer
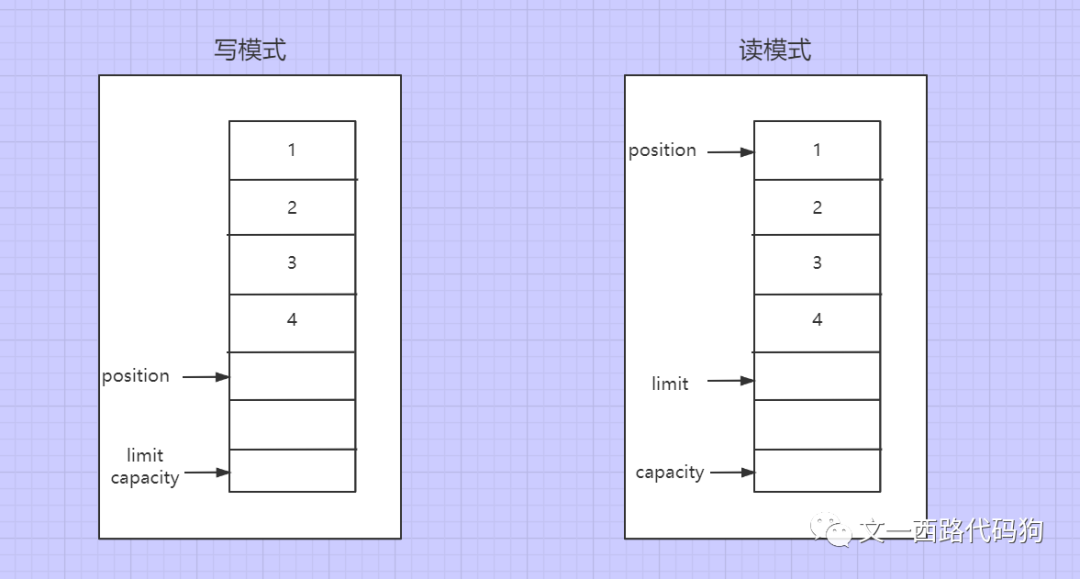

ByteBuffer依靠flip()来切换模式,在读模式下调用flip()切换为写模式,在写模式下limit和capacity相等,position标识当前写的位置。在写模式下调用flip()切换为读模式,在读模式下position回到起始位置开始读,limit回到position位置表示能读到多少数据,capacity不变表示缓存区容量大小。
capacity:在读/写模式下都是固定的,就是缓冲区容量大小。
position:读/写位置指针,表示当前读(写)到什么位置。
limit:在写模式下表示最多能写入多少数据,此时和capacity相同。在读模式下表示最多能读多少数据,此时它的值等于缓存区中实际数据量的大小。
②、ByteBuf
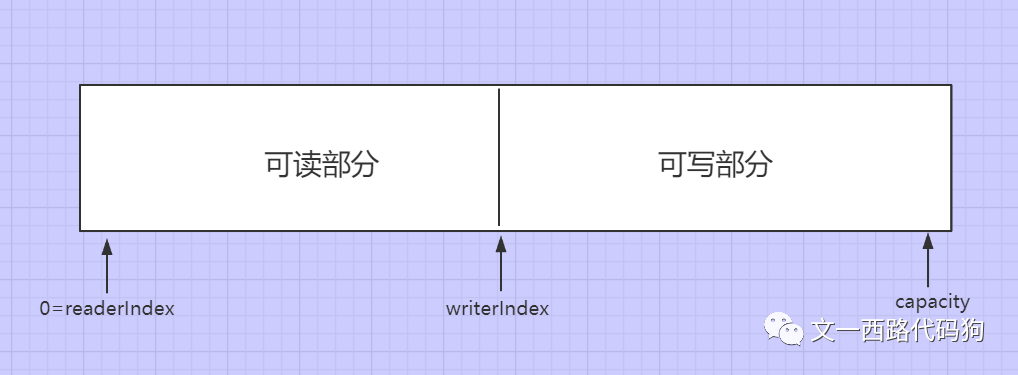
ByteBuf主要是通过readerIndex 和 writerIndex两个指针进行数据的读和写,整个ByteBuf被这两个指针最多分成三个部分,分别是可丢弃部分,可读部分和可写部分
刚初始化的时候,整个缓冲区还没有数据,读写指针都指向0,所有的内容都是可写部分,此时还没有可读部分和可丢弃部分,如下:

当写完N个字节数据后,读指针仍然是0,因为还没有开始进行读事件,写指针向后移动了N个字节的位置,如下:
当开始读数据并且读取M个字节数据之后(M<N)写指针位置不变,读指针后移动了M个字节的位置,如下:
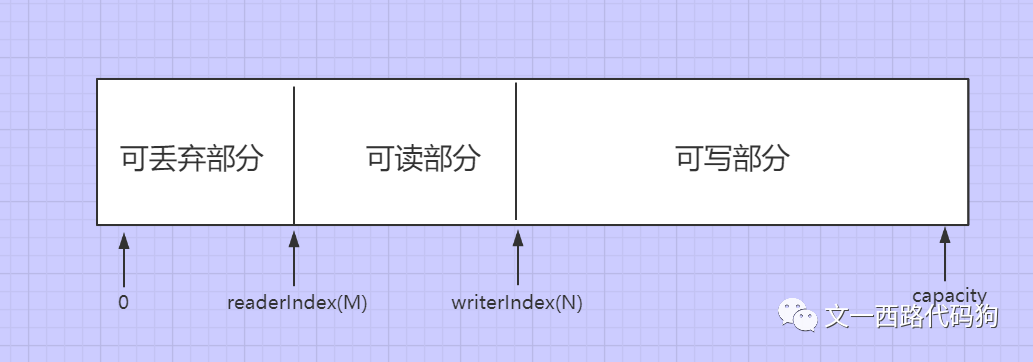
当可丢弃部分数据被清空之后,readerindex重新回到起始位置,writerindex的位置为writerindex的值减去之前的readerindex,也就是M,相关图示如下:

调用clear之后,writerindex和readerinde全部复位为0。它不会清除缓冲区内容(例如,用填充0),而只是清除两个指针。更改的读写指针的值,每个位置上原本的字节内容并没有发生改变,只是变成了可写状态而已。另请注意,此操作的语义不同于Buffer.clear()。

三、源码
明白了ByteBuf工作原理之后,ByteBuf相关的api就很好理解了,在此附上netty官方api文档,以供参阅:
https://netty.io/4.1/api/overview-summary.html。
我们在这里看下netty扩容相关源码逻辑。
扩容肯定是在写入数据的时候会由相关逻辑判断,我们随便进入一个写入字节的api方法。
public abstract ByteBuf writeBytes(byte[] src);进入到其抽象子类AbstractByteBuf中。
@Override
public ByteBuf writeBytes(byte[] src) {
writeBytes(src, 0, src.length);
return this;
}
@Override
public ByteBuf writeBytes(byte[] src, int srcIndex, int length) {
ensureAccessible();
ensureWritable(length);
setBytes(writerIndex, src, srcIndex, length);
writerIndex += length;
return this;
}首先ensureAccessible进行安全校验,每种尝试访问缓冲区内容的方法都应调用此方法,以检查缓冲区是否已释放。然后ensureWritable判断是否可写,扩容相关逻辑就在这里进行判断,如果缓冲区可写执行setBytes进行数据写入,然后writerindex向后移动length的位置,最后将ByteBuf对象进行返回。我们重点看ensureWritable。
@Override
public ByteBuf ensureWritable(int minWritableBytes) {
if (minWritableBytes < 0) {
throw new IllegalArgumentException(String.format(
"minWritableBytes: %d (expected: >= 0)", minWritableBytes));
}
ensureWritable0(minWritableBytes);
return this;
}直接进入ensureWritable0(minWritableBytes)方法中,此时minWritableBytes就是我们计划需要申请的内存大小空间。
private void ensureWritable0(int minWritableBytes) {
// 安全检查,保证写入之前是可访问的
//ensureAccessible();
// 可写,不必扩容
if (minWritableBytes <= writableBytes()) {
return;
}
//下标越界
if (minWritableBytes > maxCapacity - writerIndex) {
throw new IndexOutOfBoundsException(String.format(
"writerIndex(%d) + minWritableBytes(%d) exceeds maxCapacity(%d): %s",
writerIndex, minWritableBytes, maxCapacity, this));
}
//达到临界条件,开始执行扩容逻辑
// 计算新的容量,实际上为当前容量扩容至2的幂次方大小(具体是多少需要进行后续判断和计算)
int newCapacity = alloc().calculateNewCapacity(writerIndex + minWritableBytes, maxCapacity);
// 扩容后的容量
capacity(newCapacity);
}可以看到真正开辟内存空间新容量逻辑处理的是 alloc().calculateNewCapacity(writerIndex + minWritableBytes, maxCapacity)执行的,进入到方法里面。
来到其实现类AbstractByteBufAllocator的calculateNewCapacity方法。
@Override
public int calculateNewCapacity(int minNewCapacity, int maxCapacity) {
if (minNewCapacity < 0) {
throw new IllegalArgumentException("minNewCapacity: " + minNewCapacity + " (expectd: 0+)");
}
if (minNewCapacity > maxCapacity) {
throw new IllegalArgumentException(String.format(
"minNewCapacity: %d (expected: not greater than maxCapacity(%d)",
minNewCapacity, maxCapacity));
}
// 扩容的阈值,4兆字节大小
final int threshold = 1048576 * 4;
if (minNewCapacity == threshold) {
return threshold;
}
//如果计划一共需要的内存容量大小大于阈值,则需要和最大容量j进行比较
if (minNewCapacity > threshold) {
int newCapacity = minNewCapacity / threshold * threshold;
if (newCapacity + threshold > maxCapacity) {
newCapacity = maxCapacity;
} else {
newCapacity += threshold;
}
return newCapacity;
}
//如果计划一共需要的内存容量大小小于阈值,则以64为基数进行倍增
int newCapacity = 64;
while (newCapacity < minNewCapacity) {
newCapacity <<= 1;
}
return Math.min(newCapacity, maxCapacity);
}minNewCapacity是我们计划一共需要的内存容量大小,maxCapacity是最大缓冲区容量大小。首先判断minNewCapacity 是否小于零或者minNewCapacity 是否大于maxCapacity,满足任一都抛出异常信息,然后判断我们计划一共需要的内存容量大小minNewCapacity 是否等于了阈值4M:
①、如果等于了阈值,新容量大小就是阈值4M。
②、如果计划一共需要的内存容量大小大于阈值,则maxCapacity和minNewCapacity 相对于阈值的整数倍再加上一个阈值进行大小判断,如果大于maxCapacity,则新容量最大就是maxCapacity,返回maxCapacity,如果小于maxCapacity,则相当于按照阈值的2倍进行扩容。
③、如果计划一共需要的内存容量大小小于阈值,则以64为基数只要小于我们计划需要的内存容量大小,就2倍扩容,最后选取循环后的扩容值和最大值两个值其中的较小者。
至此扩容就完成了,总结来说就是在扩容过程中有一个扩容需要容量的一个阈值4M,如果我们需要的内存空间等于这个阈值,那么扩容后的容量就是阈值大小,如果我们需要的内存容量大小大于阈值或者小于阈值,其扩容逻辑判断和扩容后返回的容量大小是不同的。但是最终扩容后的容量大小总是2的幂次方大小并且不会比maxCapacity大。
4、ByteBuf主要的继承关系
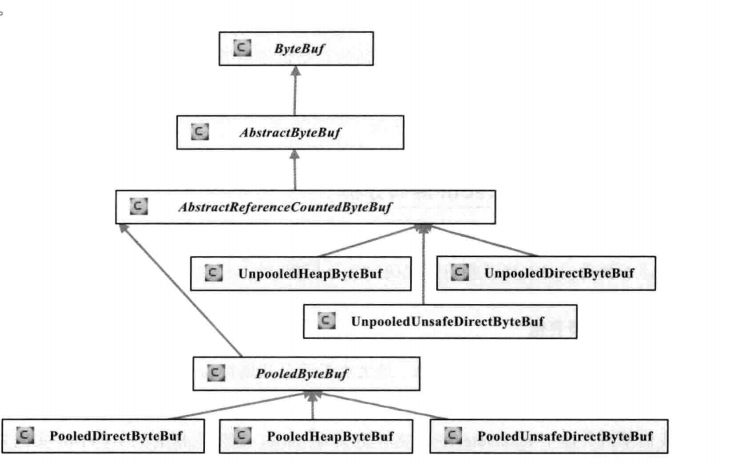
从内存分配的角度看,ByteBuf可以分为两类
(1)堆内存(HeapByteBuf)字节缓冲区:特点是内存的分配和回收速度快,可以被JVM自动收回;缺点就是如果进行Socket的I/O读写,需要额外做一次内存复制,将堆内存对应的缓冲区复制到内核Chanenel中,性能会有一定程度的下降。
(2)直接内存(DirectByteBuf) 字节缓冲区:非堆内存,它在堆外进行内存分配,相比于堆内存,它的分配和回收速度会慢一些,但是将它写入或者从Socket Channel中读取时,由于少了一次内存复制,速度比堆内存快。
正式因为各有利弊,所以Netty提供了多种ByteBuf供开发者使用,经验表明,ByteBuf的最佳实践是在I/O通信线程的读写缓冲区使用DirectByteBuf,后端业务消息的编解码模块使用HeapByteBuf,这样组合可以达到性能最优。
从内存回收角度看,ByteBuf也可以分为两类:基于对象池的ByteBuf和普通ByteBuf。两者的主要区别就是基于对象池的ByteBuf可以重用ByteBuf对象,它自己维护了一个内存池,可以循环利用创建的ByteBuf,提升内存的使用效率,降低由于高负载导致的频繁GC。测试表名使用内存池后的Netty在高负载、大并发的冲击下内存和GC更加平稳。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/191833.html原文链接:https://javaforall.net


