
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
在游戏中,我们往往有一个计分板准确定义事情的好坏程度。但现实中,定义Reward有可能是非常困难的,并且人定的reward也有可能存在许多意想不到的缺陷。在没有reward的情况下,让AI跟环境互动的一个方法叫做Imitation-Learning。在没有reward的前提下,我们可以找人类进行示范,AI可以凭借这些示范以及跟环境的互动进行学习。这种模仿学习使得智能体自身不必从零学起,不必去尝试探索和收集众多的无用数据,能大大加快训练进程。
这跟supervised-learning有类似之处,如果采用这种做法,我们叫做Behavior-Cloning,也就是复制人类的行为。
但是这种监督学习有一个缺点,如果是智能体进入到一个以前从来没有见到过的状态,就会产生较大的误差,这种误差会一直累加,到最后没有办法进行正常的行为。因此我们需要让实际遇到的数据和训练数据的分布尽量保持一致。
DAgger
前期先让人类去操作policy,拿到足够多的数据以后做完全意义上的offline训练;如果offline训出来效果不好,把效果不好的场景再让人类操作一遍,对各个状态打上动作标签。然后新数据加旧数据一起再训练,直到效果变好为止,这就是DAgger。


通常第三步人来收集数据也是一个比较麻烦和漫长的过程,我们也可以使用其他算法来代替人类来打标签。
逆强化学习(Inverse Reinforcement Learning)
在强化学习中,我们给定环境(状态转移)和奖励函数,我们需要通过收集的数据来对自身的策略函数和值函数进行优化。在逆强化学习中,提供环境(状态转移),也提供策略函数或是示教数据,我们希望从这些数据中反推奖励函数。即给定状态和动作,建立模型输出对应奖励。在奖励函数建立好后,我们就能新训练一个智能体来模仿给定策略(示教数据)的行为。
GAIL(Generative Adversarial Imitation Learning)

在IRL领域有名的算法是GAIL,这种算法模仿了生成对抗网络GANs。把Actor当成Generator,把Reward Funciton当成Discriminator。
我们要训练一个策略网络去尽量拟合提供的示教数据,那么我们可以让需要训练的reward函数来进行评价,Reward函数通过输出评分来分辨哪个是示教数据的轨迹,哪个是自己生成的虚假轨迹;而策略网络负责生成虚假的轨迹,尽可能骗过Reward函数,让其难辨真假。两者是对抗关系,双方的Loss函数是对立的,两者在相互对抗中一起成长,最后训练出一个较好的reward函数和一个较好的策略网络。
模仿学习结合强化学习
模仿学习的特点:
- 用人工收集数据往往需要较大成本,而且数据量也不会很大,并且存在数据分布不一致的问题。
- 人也有很多办不到的策略,如果是非常复杂的控制(例如高达机器人,六旋翼飞行器),人是没办法胜任的。
- 训练稳定简单。
- 最多只能做到和示教数据一样好,无法超越。
强化学习的特点:
- 需要奖励函数。
- 需要足够的探索。
- 有可能存在的不能收敛问题。
- 可以做到超越人类的决策。
因此我们可以把两者结合起来,既有人类的经验,又有自己的探索和学习。我们的做法是进行预训练和微调。AlphaGo正是运用了这种框架。同样星际争霸2的AlphaStar同样也是这种训练框架,得到了超越人类的水平。

但在运用pretrain和finetune这种框架时我们通常会面临一个问题,就是在预训练过后进行强化学习的时候,我们的策略一开始采集到的数据很可能是非常糟糕的,这会直接摧毁策略网络,导致效果越来越差,训练没法进行。因此我们需要在策略中将一开始的示教数据保留下来,我们可以把示教的数据直接放入reply buffer中,这样可以让策略网络随时进行学习。
我们可以通过加入一个损失函数同时对loss进行优化:

应用

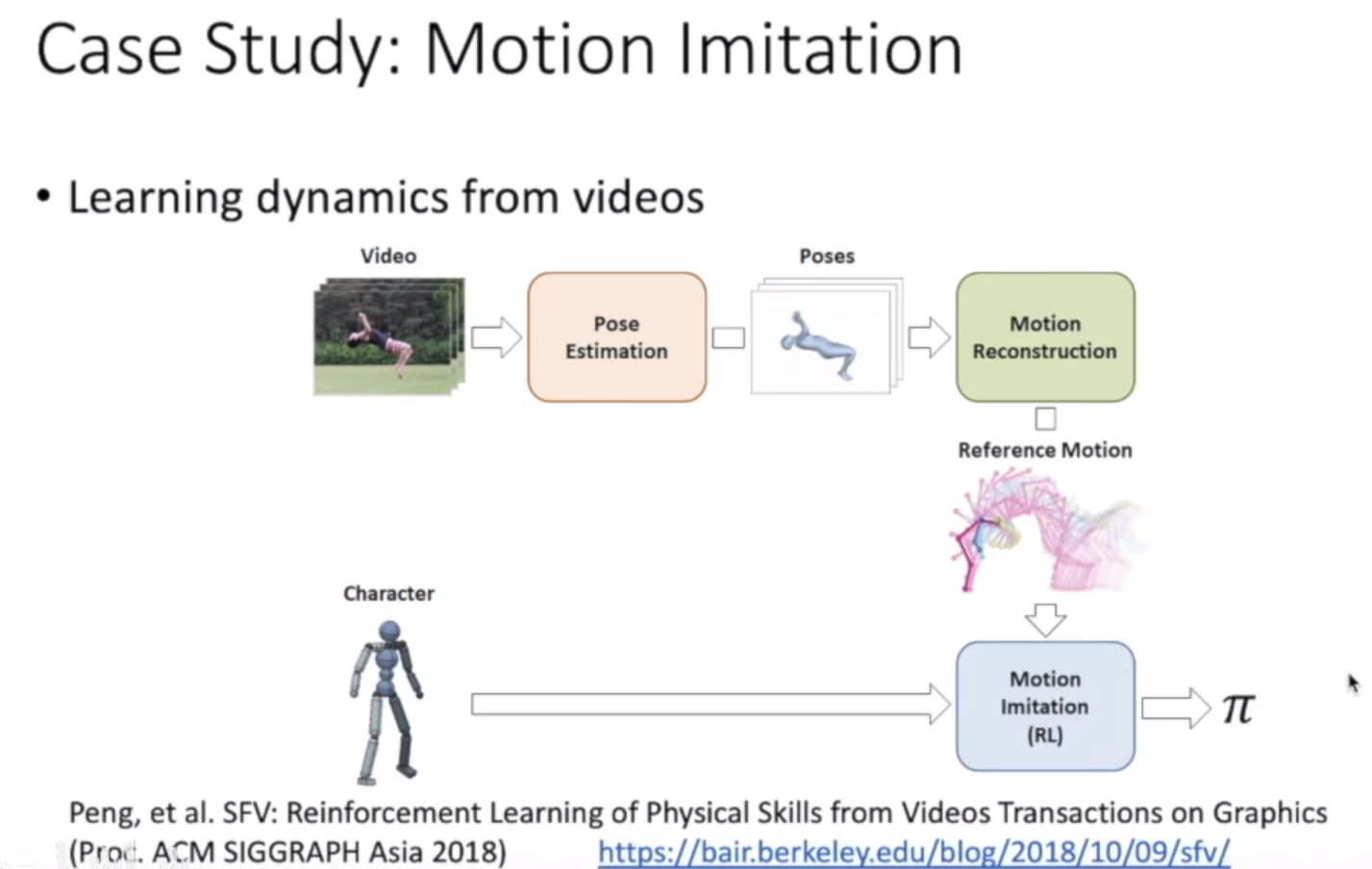
结论

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/191864.html原文链接:https://javaforall.net


