
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
在我的监督分类代码里,我一共分为了以下几个步骤:
1.制作训练样本数据;
2.遥感数据的筛选(时间、地点与云量);
3.遥感数据预处理(去云、镶嵌、裁剪);
4.构建光谱指数:NDVI、mNDWI,NDBI;
5.构建分类样本集 并分为训练样本与验证样本;
6.选择合适方法进行分类;
7.精度验证;
8.导出分类结果;
上面的步骤基本为·监督分类常用步骤,可以根据自己的需求修改,但大体没什么变化。
1.制作训练样本数据;
构造样本数据一般有两个方法,一个是本地上传矢量的训练数据;另外一个是在GEE里面自己选点制作。我主要介绍第二种方法。
构造样本数据,首先创建一个new layer,然后选择该要素,并在地图上标点。
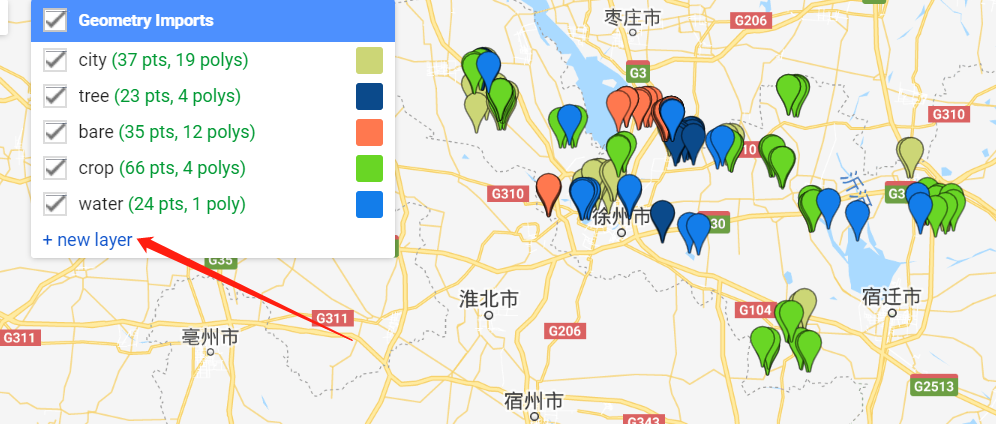

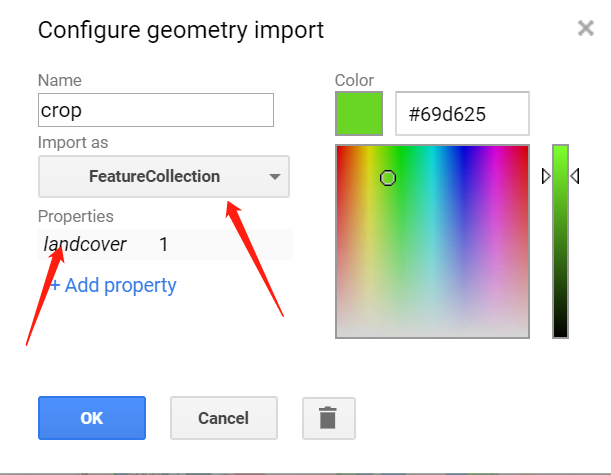
选择好样本点之后,记得打开该要素,改变图层类型为featurecollection,并添加分类属性:landcover与值。比如耕地样本点的值就为1。
2.遥感数据的筛选(时间、地点与云量);
这一步根据自己的需求选取,我代码里面的roi就是研究区。如果你发现研究区影像云非常多,可以把过滤云标准调整高一点。
var startDate = ee.Date('2018-04-01');
var endDate = ee.Date('2018-9-30');
var collection = l8
.filterDate(startDate, endDate)//时间过滤
.filterBounds(roi)//位置过滤
.filter(ee.Filter.lte('CLOUD_COVER',20))//云量过滤
;3.遥感数据预处理(去云、镶嵌、裁剪);
首先是构造一个去云函数,并且做好封装,以便你随时调用。
var remove_cloud=function(collection)
{
// 计算每个像元的云分量,定义函数fun_calCloudScore
var fun_calCloudScore = function(image) {
return ee.Algorithms.Landsat.simpleCloudScore(ee.Image(image));//simpleCloudScore计算TOA数据每一个像元的云指数
};
//确定要进行函数运算的数据集以及函数
var calCloudScore = ee.ImageCollection(collection)
.map(fun_calCloudScore)
;
//屏蔽阈值超过10的像素
var fun_maskCloud = function(image) {
var mask = image.select(['cloud']).lte(10);//TOA数据经simpleCloudScore计算产生“cloud”属性,“cloud”小于10的像元保留
// 显示云显示云掩膜
return image.updateMask(mask);//更新
};
//确定要进行函数运算的数据集以及函数
var maskCloud = ee.ImageCollection(calCloudScore)
.map(fun_maskCloud)
;
var maskCloud2=maskCloud.mean()
print('maskCloud2',maskCloud2 )
Map.addLayer(maskCloud,visualParam, 'maskCloud', false);//显示干净像元筛选过的maskCloud
Map.addLayer(maskCloud2,visualParam, 'maskCloud2', false);//显示干净像元筛选过的maskCloud
return maskCloud;
}之后一句话进行镶嵌与裁剪:
var image=remove_cloud(collection).mosaic().clip(roi);4.构建光谱指数:NDVI、mNDWI,NDBI;
这一步根据每个人的要求来。我的分类体系里面有水体,所以构建mndwi;因为有建筑,所以构建ndbi;因为有植被,所以构建NDVI。当然,这一步可以不要。
var mndwi = image.normalizedDifference(['B3', 'B6']).rename('MNDWI');//计算MNDWI
var ndbi = image.normalizedDifference(['B6', 'B5']).rename('NDBI');//计算NDBI
var ndvi = image.normalizedDifference(['B5', 'B4']).rename('NDVI');//计算NDVI需要注意一点的是,你计算出了这些指数,但是它们都是单幅影像,你需要把它们当做元影像的一个波段,所以需要把它们添加到你的image里面:
image=image
.addBands(ndvi)
.addBands(ndbi)
.addBands(mndwi)5.构建分类样本集 并分为训练样本与验证样本;
首先需要把所有的样本数据融合为一个数据,即都为训练数据。我们现在要构造每个类别的特征,而这些特征包括各个波段与指数的值,所以需要一个波段选择的过程。training就是我们需要的包含类别特征的样本集。
var classNames = city.merge(water).merge(tree).merge(crop).merge(bare);
var bands = ['B2', 'B3', 'B4', 'B5', 'B6', 'B7','MNDWI','NDBI','NDVI'];
var training = image.select(bands).sampleRegions({
collection: classNames,
properties: ['landcover'],
scale: 30
});由于我们需要的不仅是训练数据,还有验证数据。那我们把样本分为两个部分:
var withRandom = training.randomColumn('random');//样本点随机的排列
// 我们想保留一些数据进行测试,以避免模型过度拟合。
var split = 0.7;
var trainingPartition = withRandom.filter(ee.Filter.lt('random', split));//筛选70%的样本作为训练样本
var testingPartition = withRandom.filter(ee.Filter.gte('random', split));//筛选30%的样本作为测试样本6.选择合适方法进行分类;
GEE提供的方法实在是太多了,这个根据个人需求来,下图就为gee的所有监督分类方法。

现在我们有方法,有样本集1,那就进行分类:
// 选择分类的属性
var classProperty = 'landcover';
//分类方法选择smileCart() randomForest() minimumDistance libsvm
var classifier = ee.Classifier.libsvm().train({
features: trainingPartition,
classProperty: 'landcover',
inputProperties: bands
});
//分类
var classified = image.select(bands).classify(classifier);7.精度验证;
精度验证,这就得用到我们之前的验证数据集。这一步可以得到kappa系数、总体精度与转移矩阵。
var test = testingPartition.classify(classifier);//运用测试样本分类,确定要进行函数运算的数据集以及函数
var confusionMatrix = test.errorMatrix('landcover', 'classification');//计算混淆矩阵
print('confusionMatrix',confusionMatrix);//面板上显示混淆矩阵
print('overall accuracy', confusionMatrix.accuracy());//面板上显示总体精度
print('kappa accuracy', confusionMatrix.kappa());//面板上显示kappa值8.导出分类结果;
这个导出都千篇一律,没什么说的,根据自己的要求到处就行,比如说这是我的导出:
Export.image.toDrive({
image: classified,//分类结果
description: 'xuzhou_cart',//文件名
folder: 'xuzhou_cart',
scale: 30,//分辨率
region: roi,//区域
maxPixels:34e10//此处值设置大一些,防止溢出
});下图就是我的监督分类结果,可以看到效果还不错:
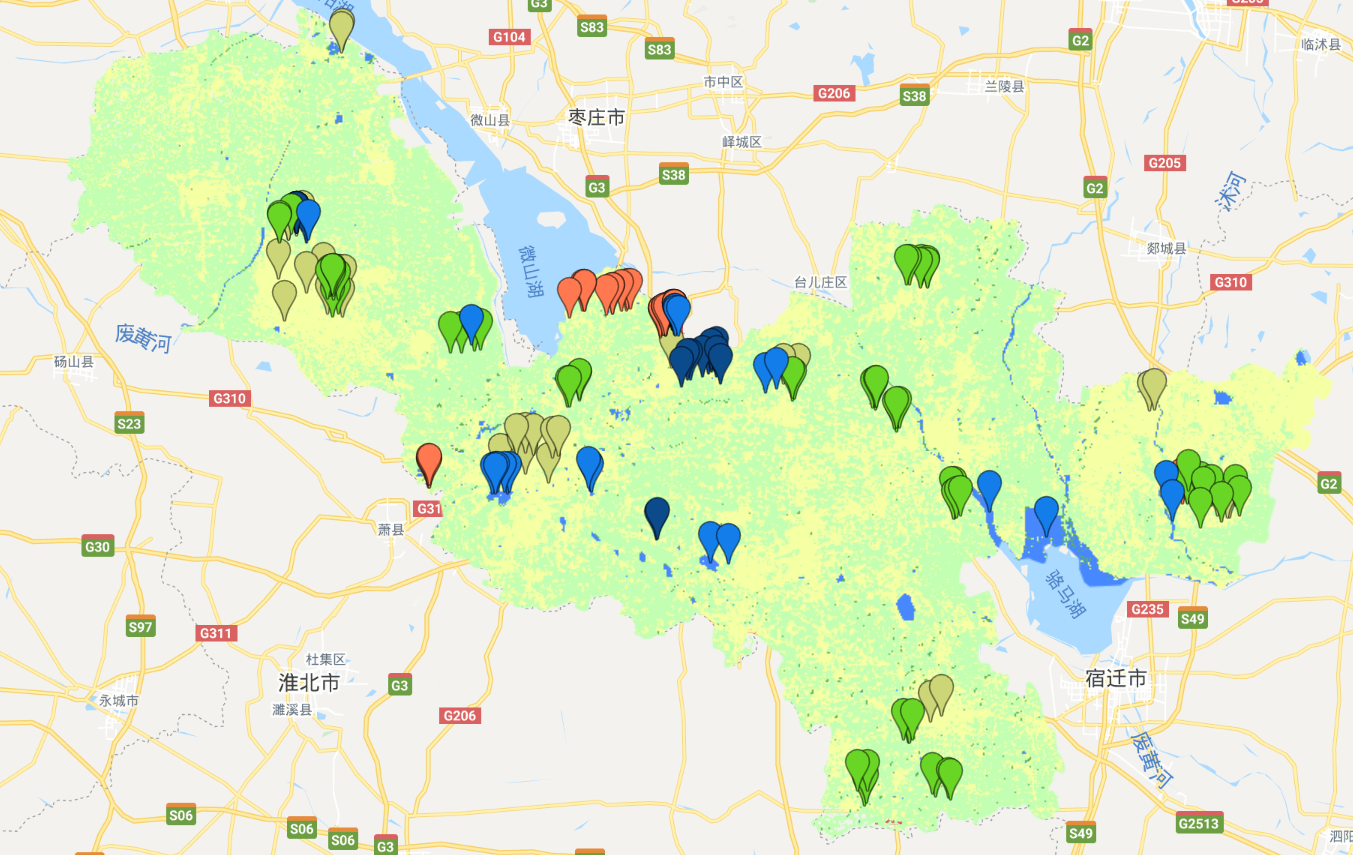
最后给大家一个小建议:选择样本很重要,分类方法倒是次要的,要保证样本的数量以及准确率。
完整代码链接:https://code.earthengine.google.com/3beb3602a1eb4ca79a3f04dddeee7192
可以前往“地信遥感数据汇”获取更多数据。
https://www.gisrsdata.com/
VX:kitmyfaceplease2;欢迎关注公众号:锐多宝的地理空间;

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/191968.html原文链接:https://javaforall.net


