
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺


上一部分研究的是奖励稀疏的情况,本节的问题在于如果连奖励都没有应该怎么办,没有奖励的原因是,一方面在某些任务中很难定量的评价动作的好坏,如自动驾驶,撞死人和撞死动物的奖励肯定不同,但分别为多少却并不清楚,另一方面,手动设置的奖励可能导致不可控的行为。要解决此类问题,可以将人类专家的范例作为强化学习代理的参考去学习,因此模仿学习又叫演示学习(Learning by demonstration)或学徒学习(Apprenticeship Learning)。下面将介绍两种模仿学习方法:行为克隆和逆向强化学习。
1、行为克隆(Behavior Cloning)
行为克隆和监督学习的思想如出一辙,人类专家采取什么动作,代理就采取什么动作。以自动驾驶为例,收集很多人类专家的驾驶资料,这些资料的状态s是开车的场景,动作a是在此场景下的动作。把这些资料输入到神经网络中,使网络的输出尽可能地接近人类实际做出的动作,就可以完成任务。
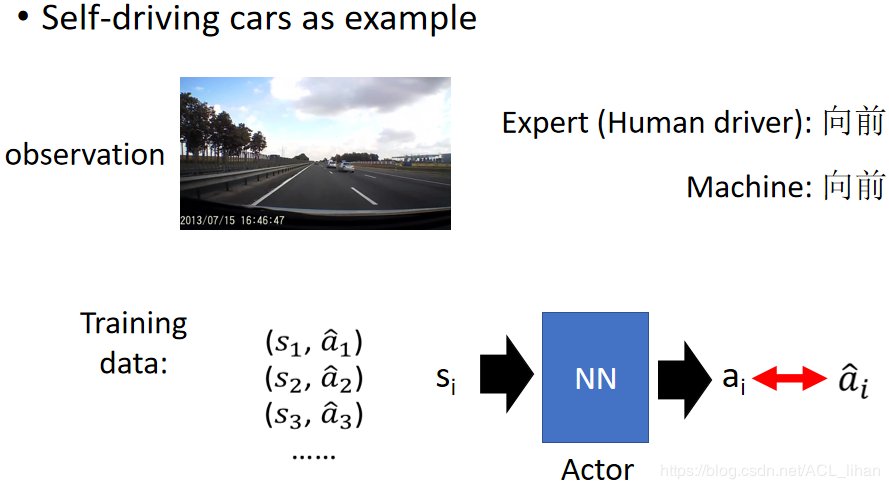
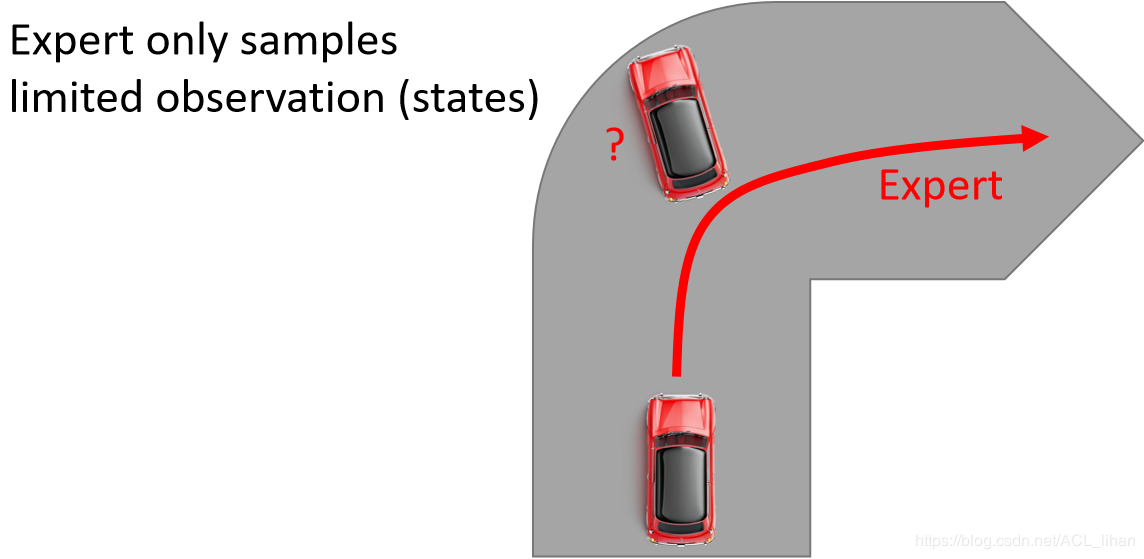
但是在这个过程中,专家观察到的状态是有限的。比如在实验中,让人去开车就都能顺利转弯,而不会出现撞墙的情况,而这时让代理去开车,如果某一时间它没能和人类专家一样及时转弯导致出现快撞墙的状态,由于人类专家并没有给出这种情况下的处理动作,代理就不知道下一步应该怎么办。一种解决方法就是让代理收集更多的数据——Dataset Aggregation。
Dataset Aggregation
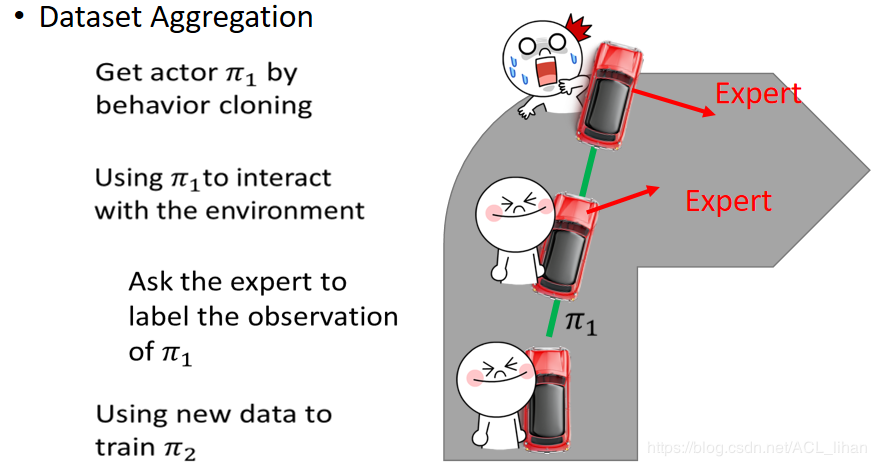
通过Behavior Cloning得到actor Π1,使用Π1与环境进行交互,即开车;让专家坐在车里观察所处的状态并告诉actor做出什么动作;但是actor并不会听取专家的建议,还是以actor的意愿开车,如果最终撞墙一个episode就结束了;这时actor就知道在快要撞墙的时候采取什么动作了,然后用这个新的数据去训练新的策略Π2;重复多次步骤1~4。 以上就是Dataset Aggregation的过程。
从上面可以看出行为克隆很容易实现,但是也存在问题:
- 代理会完全复制专家的行为,不管这个行为对不对,因为没有奖励,代理会将人类专家的行为当成圣旨;
- 代理的学习能力有限,代理会选择错误的行为进行复制,那什么该学什么不该学就显得很重要;
- 有可能出现mismatch的问题(上面开车的例子)。
什么是mismatch问题呢?

在监督学习中,期望训练数据和测试数据具有相同的分布,而在行为克隆中,代理做出的动作是会影响后续状态的。因为神经网络的训练存在误差,训练出来的actor Π*与人类专家Π不可能完全一模一样,就会导致某个状态下,两者采取的动作不一样,自然而然就会导致后面的状态完全不同,最坏的情况就是actor遇到了专家从未遇到过的状态,这时actor就完全懵逼了,即失之毫厘,差之千里。
所以,虽然行为克隆简单但是并不是一种很好的方法,所以就出现了第二种方法:逆向强化学习。
2、逆向强化学习(Inverse Reinforcement Learning,IRL)
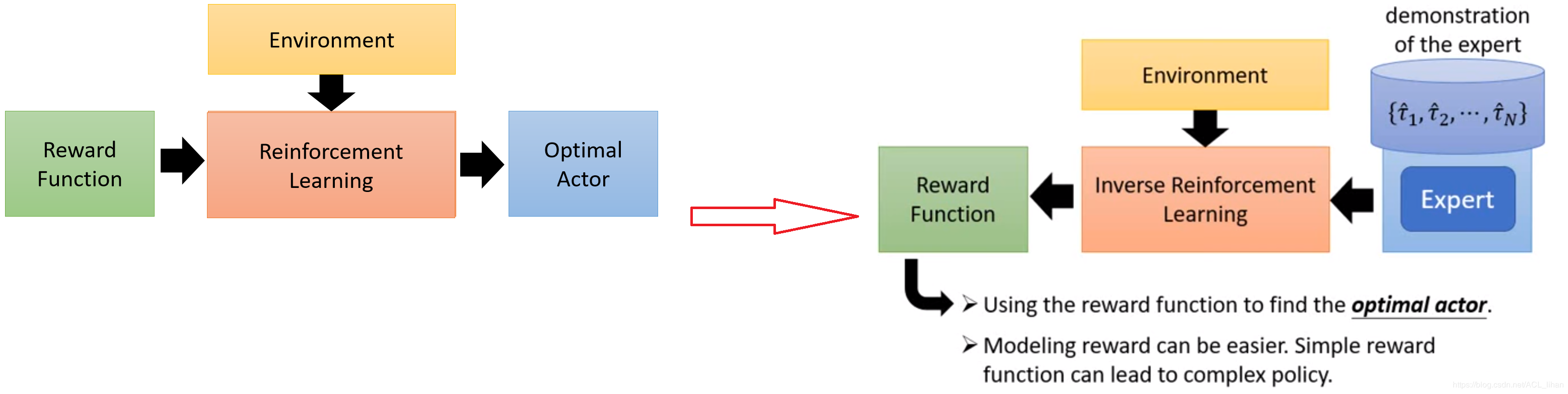
上面的左图是熟悉的强化学习的步骤,通过环境和奖励函数,最终得到理想的actor。右图是逆向强化学习的步骤,由于无法从环境中获得奖励,那就需要通过收集人类专家的资料和环境的信息,来反推奖励函数,推出奖励函数后就可以使用正常强化学习的做法了。
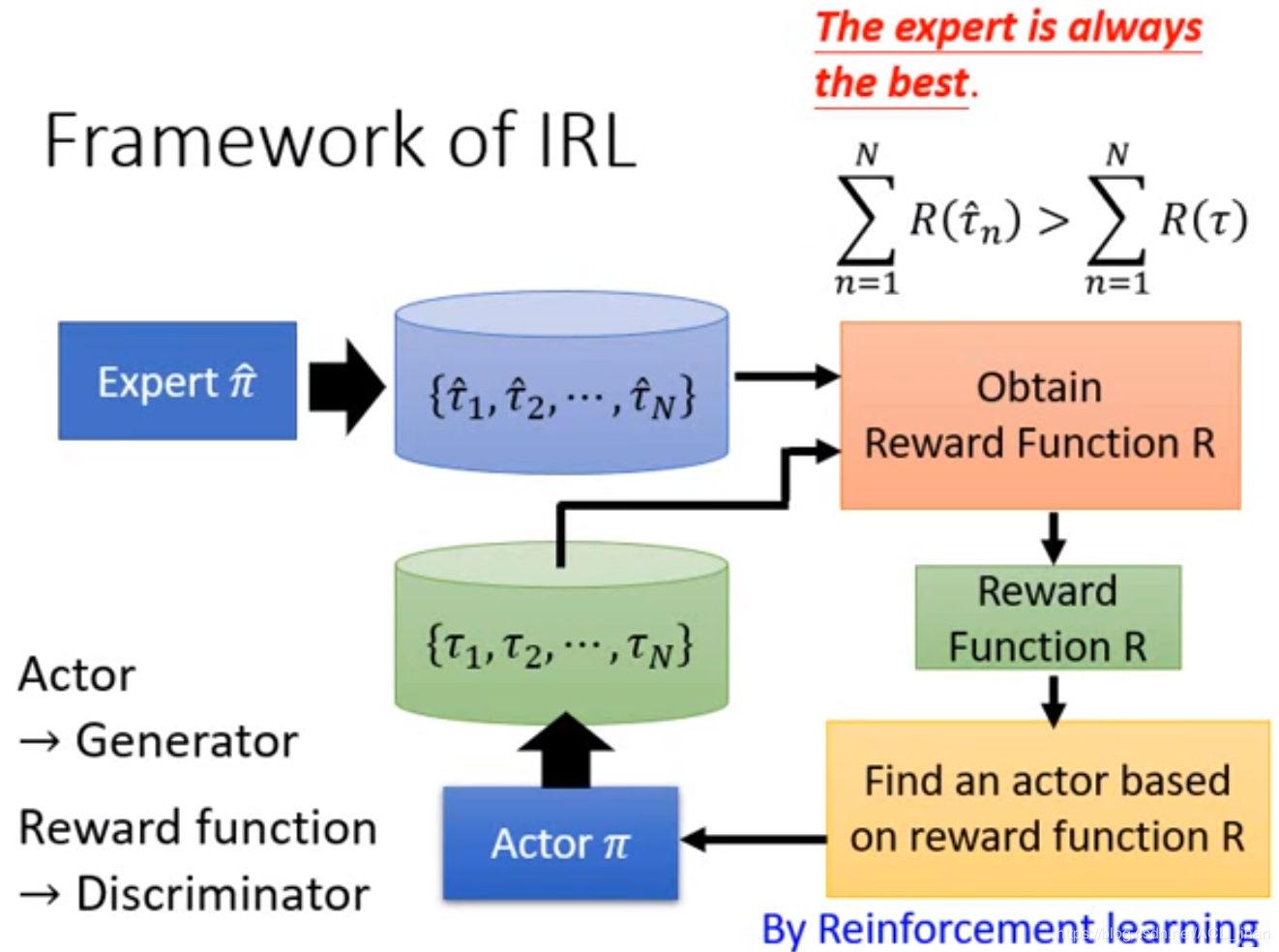
emsp;具体来看逆向强化学习的运作步骤:
- 让专家先玩游戏,记录游戏过程,形成n个episode;
- actor再去玩游戏啊,记录游戏过程,形成n个episode;
- 设定一个奖励函数,这个奖励函数强制要求专家的累计得分一定要高于actor的累计得分;
- 有了奖励函数就可以使actor去更新出更强的actor;
- 当actor能在此时的奖励函数下得到很高的奖励(还是要求专家的得分高于actor),让actor根据新的奖励函数更新出更强的actor;
- 重复执行以上步骤。
逆向强化学习可以实现只用很少的专家示范资料,就可以训练出一个很理想的actor。
看了以上步骤,可以 想到,actor和奖励函数对应于GAN中的generator和discriminator。通过奖励函数的不断修正,使actor越来越接近专家的水平。

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/193153.html原文链接:https://javaforall.net


